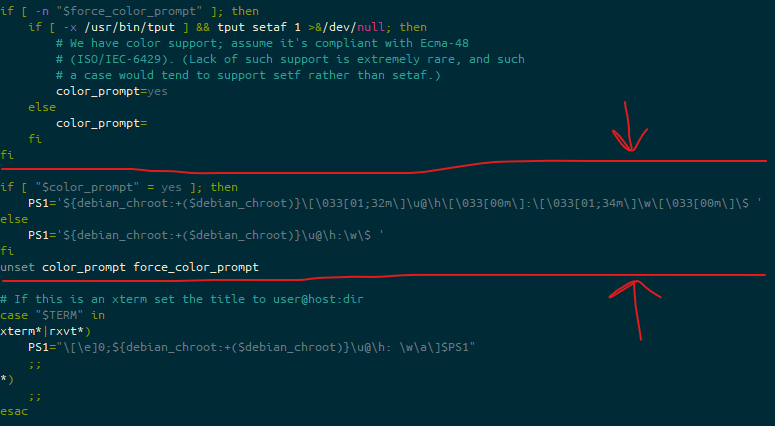
On Wednesday, 21st April, I saw a link to a blog post in a chat group for the Linux Lads podcast. This blog post included a discount code to make the GitLab Certified Associate course and exam free. I signed up, and then shared the post to colleagues.
Free GitLab certification course and exam – until 30th April 2021.
GitLab has created a “Certified Associate” certification course which normally costs $650, but is available for free until 30th April using the discount code listed on this blog post and is available for one year after purchase (or free purchase).
I’ve signed up for the course today, and will be taking the 6 hour course, which covers:
Section 1: Self-Study – Introduction to GitLab
* GitLab Overview
* GitLab Comparison
* GitLab Components and Navigation
* Demos and Hands On Exercises
Section 2: Self-Study – Using Git and GitLab
* Git Basics
* Basic Code Creation in GitLab
* GitLab’s CI/CD Functions
* GitLab’s Package and Release Functions
* GitLab Security Scanning
Section 3: Certification Assessments
* GitLab Certified Associate Exam Instructions
* GitLab Certified Associate Knowledge Exam
* GitLab Certified Associate Hands On Exam
* Final Steps
You don’t need your own GitLab environment – you get one provided to you as part of the course.
Another benefit to this course is that you’ll learn about Git as part of the course, so if you’re looking to do any code development, infrastructure as code, documentation as code, or just learning how to store any content in a version control system – this will teach you how 😀
Good luck to everyone participating in the course!
After sharing this post, the GitLab team amended the post to remove the discount code as they were significantly oversubscribed! I’ve heard rumours that it’s possible to find the code, either on Gitlab’s own source code repository, or perhaps using Archive.org’s wayback machine, but I’ve not tried!
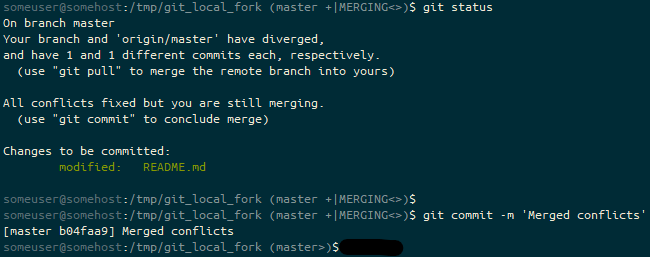
On Friday I started the course and completed it yesterday. The rest of this post will be my thoughts on the course itself, and the exam.
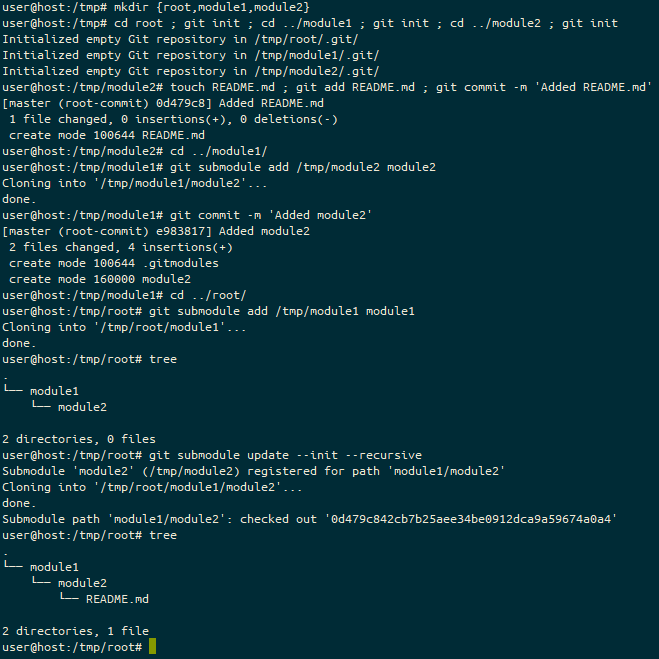
Signing up for the course and getting started
Signing up was pretty straightforward. It wasn’t clear that you had a year between when you enrolled for the course and until you first opened the content, but that once you’d opened the link to use the Gitlab demo environment, you had 21 days to use it. You’re encouraged to sign up for the demo environment on the first stage, thereby limiting you to the 21 days from that point. I suspect that if you re-visit that link on a second or third time, you’d get fresh credentials, so no real disaster there, but it does make you feel a bit under pressure to use the environment.
First impressions
The training environment is pretty standard, as far as corporate training goes. You have a side-bar showing the modules you need to complete before the end of the course, and as you scroll down through each module, you get various different media-types arriving, including youtube videos, fade-in text, flashcards which require clicking on and side-scrolling presentation cards. (Honestly, I do wonder whether this is particularly accessible to those with visual or motor impairments… I hope so, but I don’t know how I’d check!)
As you progress through each module, in the sidebar to the left, a circle outline is slowly turned from grey to purple, and when you finish a module the outline is replaced by a filled circle with a white tick in it. At the bottom of each module is a link to the next module.
The content
You have a series of 3 sections:
- “Introduction to Gitlab” (aka, “Corporate Propaganda” 😉) which includes the history of the GitLab project and product, how many contributors it has, what it’s primary objective is, and so on. There’s even an “Infotainment” QVC-like advert about how amazing GitLab is in this section, which is quite cute. At the end of this first section, you get a “Hands On” section, where you’re encouraged to use GitLab to create a new Project. I’ll come back to the Hands on sections after this.
- “Using Git and Gitlab”, which you’d expect to be more hands-on but is largely more flashcards and presentation cards, each with a hands on section at the end.
- “Certification Assessments” has two modules to explain what needs to happen (one before, one after) and then two parts to the “assessment” – a multiple-choice section which has to be answered 100% correctly to proceed, and a “hands on” exam, which is basically a collection of “perform this task” questions, which you are expected to perform in the demo environment.
Hands-on sections focus on a specific task – “create a project”, “commit code”, “create an issue”, “create a merge request” and so-on. There are no tasks which will stretch even the freshest Git user, and seeing the sorts of things that the “Auto DevOps” function can enable might interest someone who wants to use GitLab. I was somewhat disappointed that there was barely any focus on the fact that GitLab can be self-hosted, and what it takes to set something like that up.
We also get to witness the entire power (apparently) of upgrading to the “Premium” and “Ultimate” packages of GitLab’s proprietary add-ons… Epics. I jest of course, I’ve looked and there’s loads more to that upgrade!
The final exams (No Spoilers)
This is in two parts, a multiple-choice selection on a fixed set of 14 questions, with 100% accuracy required to move on to the next stage that can be retaken indefinitely, and a hands-on set of… from memory… 14ish tasks which must be completed on a project you create.
The exam is generally things about GitLab which you’ve covered in the course, but included two questions about using Git that were not covered in any of the modules. For this reason, I’d suggest when you get to those questions, open a git environment, and try each of the commands offered given the specific scenario.
Once you’ve finished the hands-on section, using the credentials you were given, you’re asked to complete a Google Forms page which includes the URL of the GitLab Project you’ve performed your work in, and the username for your GitLab Demo Environment. You submit this form, and in 7 days (apparently, although, given the take-up of the course, I’m not convinced this is an accurate number) you’ll get your result. If you fail, apparently, you’ll be invited to re-try your hands-on exam again.
At least some of the hands-on section tasks are a bit ambiguous, suggesting you should make this change on the first question, and then “merge that change into this branch” (again, from memory) in the next task.
My final thoughts
So, was it worth $650 to take this course? No, absolutely not. I realise that people have put time and effort into the content and there will be people within GitLab Inc checking the results at the end… but at most it’s worth maybe $200, and even that is probably a stretch.
If this course was listed at any price (other than free) would I have taken it? …. Probably not. It’s useful to show you can drive a GitLab environment, but if I were going for a job that needed to use Git, I’d probably point them at a project I’ve created on GitHub or GitLab, as the basics of Git are more likely to be what I’d need to show capabilities in.
Does this course teach you anything new about Git or GitLab that just using the products wouldn’t have done? Tentatively, yes. I didn’t know anything about the “Auto DevOps” feature of GitLab, I’d never used the “Quick Actions” in either issues or merge requests, and there were a couple of git command lines that were new to me… but on the whole, the course is about using a web based version control system, which I’ve been doing for >10 years.
Would this course have taught you anything about Git and GitLab if you were new to both? Yes! But I wouldn’t have considered paying $650… or even $65 for this, when YouTube has this sort of content for free!
What changes would you make to this course? For me, I’d probably introduce more content about the CI/CD elements of GitLab, I might introduce a couple of questions or a module about self-hosting and differences about the tiers (to explain why it would be worth paying $99/user/month for the additional features in the software). I’d probably also split the course up into several pieces, where each of those pieces goes towards a larger target… so perhaps there might be a “basic user” track, which is just “GitLab inc history”, “using git” and “using Gitlab for issues and changes”, then an advanced user, covering “GitLab tiers”, “GitLab CI/CD”, “Auto DevOps”, running “Git Runners”, and perhaps a Self Hosting course which adds running the service yourself, integrating GitLab with other services, and so on. You might also (as GitLab are a very open company) have a “marketing GitLab” course (for TAMs, Pre-Sales and Sales) which could also be consumed externally.
Have you passed? Yep
Read More