A few years ago, I wrote an Ansible role to download the latest version of a file from a Github release. Around the same point, I also wrote a bash script to do the same thing. For some reason, I never released either of them (or if I did, I can’t find them), so here’s the Bash one, as I needed to reuse it today :)
#!/bin/bash
AGENT=""
TRY_WGET=1
TRY_CURL=1
if [ "$TRY_WGET" == "1" ] && command -v wget >/dev/null 2>&1
then
AGENT=wget
elif [ "$TRY_CURL" == "1" ] && command -v curl >/dev/null 2>&1
then
AGENT=curl
fi
if [ -z "$AGENT" ]
then
echo "Error: No HTTP agent (curl and wget tested)" >&2
exit 1
fi
DEBUG() {
echo "$@" >&2
}
GET() {
URL="$1"
TARGET="${2:-}"
if [ "$AGENT" == "curl" ]
then
if [ -z "$TARGET" ]
then
DEBUG curl --silent "$URL"
curl --silent "$URL"
elif [ "$TARGET" == "ORIGIN" ]
then
DEBUG curl --silent -LO "$URL"
curl --silent -LO "$URL"
else
DEBUG curl --output "$TARGET" --silent "$URL"
curl --output "$TARGET" --silent "$URL"
fi
else
if [ -z "$TARGET" ]
then
DEBUG wget -qO- "$URL"
wget -qO- "$URL"
elif [ "$TARGET" == "ORIGIN" ]
then
DEBUG wget -q "$URL"
wget -q "$URL"
else
DEBUG wget -q -O "$TARGET" "$URL"
wget -q -O "$TARGET" "$URL"
fi
fi
}
REPO="${1:-}"
ASSET="${2:-}"
VERSION="${3:-latest}"
[ "$VERSION" != "latest" ] && VERSION="tags/$3"
RELEASE_JSON=$(GET "https://api.github.com/repos/$REPO/releases/$VERSION")
ASSET_URL=$(echo "$RELEASE_JSON" | grep -oP "(?<=browser_download_url\": \")[^\"]*${ASSET}" | head -n 1)
if [ -n "$ASSET_URL" ]
then
GET "$ASSET_URL" "${OUTPUT:-ORIGIN}"
else
echo "Asset not found" >&2
exit 2
fi
I recently was in the situation where I had two github profiles (one work, one personal) that I needed to incorporate in projects.
My work account on this device is my “default”, I use it to push, pull and so on, but the occasional personal activities (like terminate-notice) all should be attributed to my personal account.
To make this happen, I used direnv which reads a .envrcfile in the parents of the directory you’re currently in. I created a directory for my personal projects – ~/Code/Personaland placed a .envrc file which contains:
This means that I have a specific SSH key just for my personal activities (~/.ssh/personal.id_ed25519) and I’ve got my email address defined as two environment variables – AUTHOR (who wrote the code) and COMMITTER (who added it to the tree) – both are required when you’re changing them like this!
Because I don’t ever want it to try to use my SSH Agent, I’ve added the fact that SSH_AUTH_SOCK should be empty.
As an aside, work also require Commit Signing, but I don’t want to use that for my personal projects right now, so I also discovered a new feature as-of 2020 – the environment variables GIT_CONFIG_KEY_x, GIT_CONFIG_VALUE_x and GIT_CONFIG_COUNT=x
By using these, you can override any system, global and repo-level configuration values, like this:
This ensures that I *will not* GPG Sign commits, tags or pushes.
If I accidentally cloned a repo into an unusual location, or on purpose need to make a directory or submodule a personal repo, I just copy the .envrc file into that part of the tree, run direnv allowand hey-presto! I’ve turned that area into a personal repo, without having to remember the .gitconfigstring to mark a new part of my tree as a personal one.
I’ve been working on my Decision Records open source project for a few months now, and I’ve finally settled on the cross-platform language Rust to create my script. As a result, I’ve got a build process which lets me build for Windows, Mac OS and Linux. I’m currently building a single, unsigned binary for each platform, and I wanted to make it so that Github Actions would build and release these three files for me. Most of the guidance which is currently out there points to some unmaintained actions, originally released by GitHub… but now they point to a 3rd party “release” action as their recommended alternative, so I thought I’d explain how I’m using it to release on several platforms at once.
Although I can go into detail about the release file I’m using for Rust-Decision-Records, I’m instead going to provide a much more simplistic view, based on my (finally working) initial test run.
GitHub Actions
GitHub have a built-in Continuous Integration, Continuous Deployment/Delivery (CI/CD) system, called GitHub Actions. You can have several activities it performs, and these are executed by way of instructions in .github/workflows/<somefile>.yml. I’ll be using .github/workflows/build.yml in this example. If you have multiple GitHub Action files you wanted to invoke (perhaps around issue management, unit testing and so on), these can be stored in separate .yml files.
The build.yml actions file will perform several tasks, separated out into two separate activities, a “Create Release” stage, and a “Build Release” stage. The Build stage will use a “Matrix” to execute builds on the three platforms at the same time – Linux AMD64, Windows and Mac OS.
The actual build steps? In this case, it’ll just be writing a single-line text file, stating the release it’s using.
So, let’s get started.
Create Release
A GitHub Release is typically linked to a specific “tagged” commit. To trigger the release feature, every time a commit is tagged with a string starting “v” (like v1.0.0), this will trigger the release process. So, let’s add those lines to the top of the file:
name: Create Release
on:
push:
tags:
- 'v*'
You could just as easily use the filter pattern ‘v[0-9]+.[0-9]+.[0-9]+’ if you wanted to use proper Semantic Versioning, but this is a simple demo, right? 😉
Next we need the actual action we want to start with. This is at the same level as the “on” and “name” tags in that YML file, like this:
So, this is the actual “create release” job. I don’t think it matters what OS it runs on, but ubuntu-latest is the one I’ve seen used most often.
In this, you instruct it to create a simple release, using the text in the annotated tag you pushed as the release notes.
This is using a third-party release action, softprops/action-gh-release, which has not been vetted by me, but is explicitly linked from GitHub’s own action.
If you check the release at this point, (that is, without any other code working) you’d get just the source code as a zip and a .tgz file. BUT WE WANT MORE! So let’s build this mutha!
Build Release
Like with the create_release job, we have a few fields of instructions before we get to the actual actions it’ll take. Let’s have a look at them first. These instructions are at the same level as the jobs:\n create_release: line in the previous block, and I’ll have the entire file listed below.
So this section gives this job an ID (build_release) and a name (Build Release), so far, so exactly the same as the previous block. Next we say “You need to have finished the previous action (create_release) before proceeding” with the needs: create_release line.
But the real sting here is the strategy:\n matrix: block. This says “run these activities with several runners” (in this case, an unspecified Ubuntu, Mac OS and Windows release (each just “latest”). The include block asks the runners to add some template variables to the tasks we’re about to run – specifically release_suffix.
The last line in this snippet asks the runner to interpret the templated value matrix.os as the OS to use for this run.
Let’s move on to the build steps.
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Run Linux Build
if: matrix.os == 'ubuntu-latest'
run: echo "Ubuntu Latest" > release_ubuntu
- name: Run Mac Build
if: matrix.os == 'macos-latest'
run: echo "MacOS Latest" > release_mac
- name: Run Windows Build
if: matrix.os == 'windows-latest'
run: echo "Windows Latest" > release_windows
This checks out the source code on each runner, and then has a conditional build statement, based on the OS you’re using for each runner.
It should be fairly simple to see how you could build this out to be much more complex.
The final step in the matrix activity is to add the “built” file to the release. For this we use the softprops release action again.
The last post I made was about using submodules to work with code that is being developed, either in isolation from other aspects of a project, or so components can be reused without requiring lots of copy-and-paste activities. It was inspired by a question from a colleague. After asking a few more questions, it turns out that may be what that colleague needed was to consume code from other repositories and store them in their own project.
In this case, I’ve created two repositories, both on GitHub (which will both be removed by the time this post is published) called JonTheNiceGuy/Git_Demo (the “upstream”, open source project) and JonTheNiceGuy-Inc/Git_Demo (the private project, referred to as “mine”).
Getting the “Open Source” project started
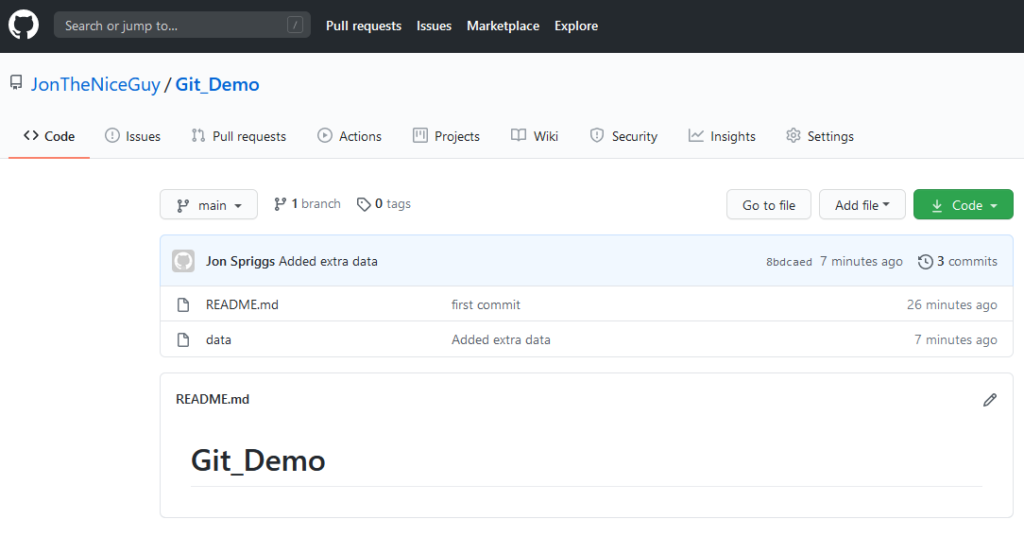
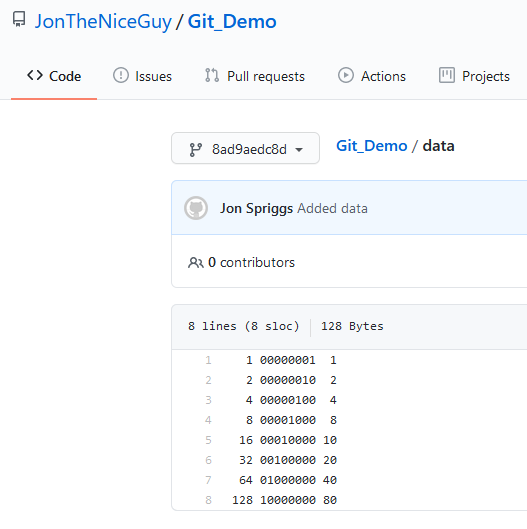
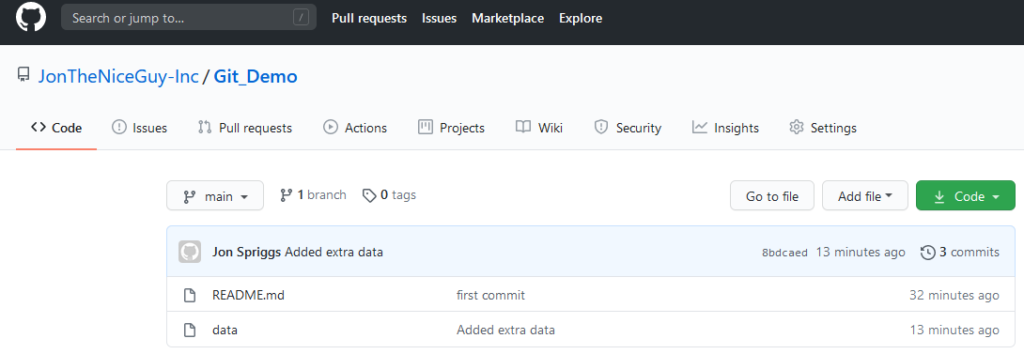
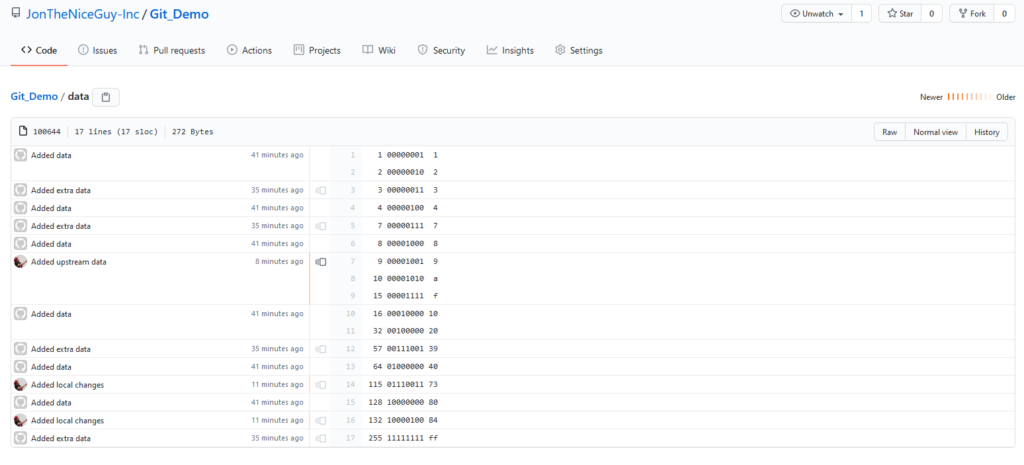
Here we have a simple repository, showing the README file for the project (which is likely, in the real world, to show what license that code has been released under, some explaination on what it’s for, etc.) and the actual data source. In this demo, the data source is a series of numbers, showing the decimal number in the first column, the binary representation of that number in the second column, and the hexedecimal representation in the third column.
Our “upstream” repository, showing the README.md file and the data source we want to use.The data source itself. Note, I forgot to take a screen shot of this file, so I’ve had to “go back to a previous commit” to collect this particular image.
Elsewhere in the world, a private project has started! It’s going to use this data source as some element of this project, and to ensure that the code they’re relying on doesn’t go away, they create their own repository which this code will go into.
Preparing the private project
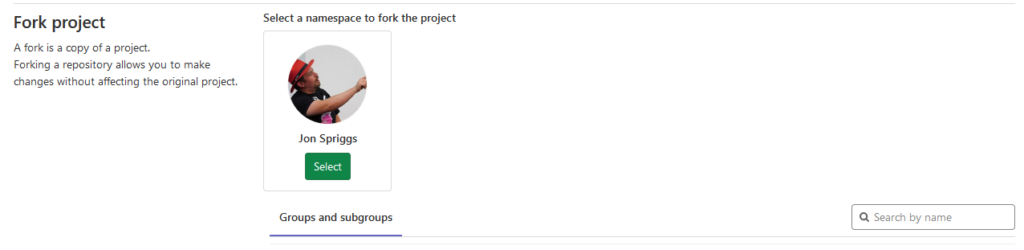
If both repositories are using GitHub, or if both repositories are using GitLab, then you should be able to “just” Fork the repository, using the “Fork” button in the top right corner:
The “Fork” button
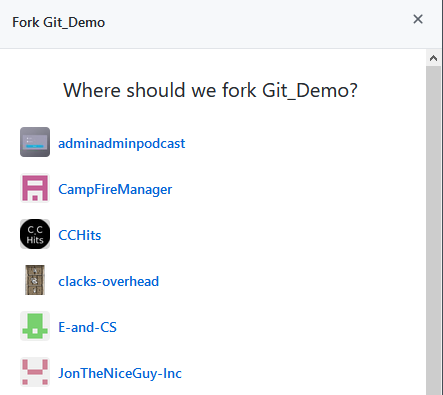
And then select the organisation or account to place the forked repo into.
A list of potential targets to fork the repository into. Your view may differ if you are part of less organisations.
Gitlab has a similar workflow – they have a similar “fork” button, but the list of potential targets is different (but still works the same way).
Gitlab’s list of potential targets to fork the repository into.
Note that you can’t “easily” fork between different Version Control Services! To do something similar, you need to create a new repository in the target service, and then, run some commands to move the code over.
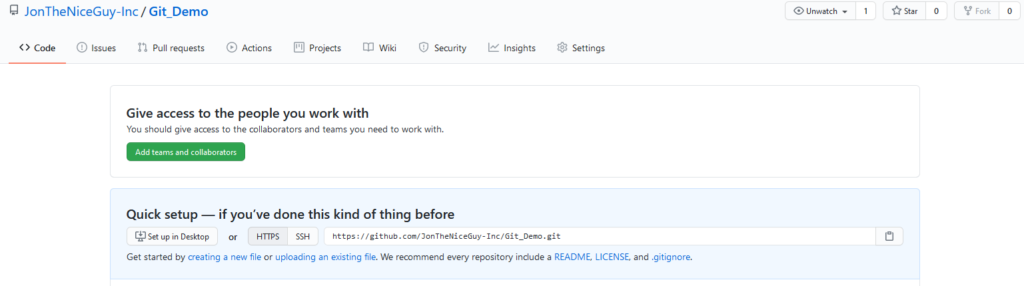
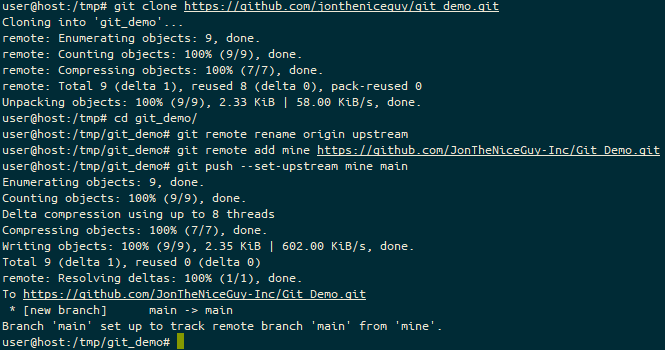
The screen you see immediately after you’ve created a new project – here I’ve created it in the “JonTheNiceGuy-Inc” Organisation. You can see the “quick setup” panel which has the URL to use for the repository.Here we see the results of running five commands, which are: git clone <url> ; cd <target-dir> ; git remote rename origin upstream ; git remote add mine <url> ; git push –set-upstream mine main
If you’re using the command line method, here’s the commands you issue:
git clone http://service/user/repo – This command clones the repository from your service of choice to your local file system. It usually places it into the name of the repository you specified. In this case, “repo”, but in the above context (cloning from Git_Demo.git) it goes into “Git_Demo”. Note, HTTP(S) isn’t the only git transport, another common one is SSH, so if you prefer using SSH instead of HTTP, the URL in this case will be something like git@service:user/repo or service:user/repo. If you’re using submodules, however, I’d strongly recommend using HTTP(S) over SSH for at least the initial pull, as this is much easier for clients to navigate.
cd repo – Move into the directory where the cloned repository has been placed.
OPTIONAL: git remote rename origin upstream – Rename the remote source of the repository. By default, when you git clone or use git submodule add, the name of the remote resource is called “origin”. I prefer to give a descriptive name for my remote sources, so using “upstream” makes more sense to me. In later commands, I’ll use the remote name “upstream” again. If you don’t want to run this command, and leave the remote name as “origin”, you’ll just have to remember to change it back to “origin”.
git remote add mine http://new-service/user/repo – this adds a new remote source, to which you can push new commits, or pull code from your peers. Again, like in the git clone command above, you may use another URL format instead of HTTP(S). You may want to use a different name for the new remote, but again, I tend to prefer “mine” for anything I’m personally working on.
git push --set-upstream mine main – This sends the entire commit tree for the branch you’re currently on to your remote source.
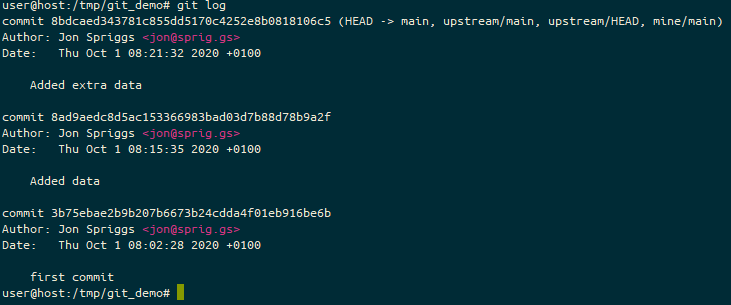
Once we’ve run the git push, you can now see that the code has all been pushed to your private project.Issuing a git log command, shows the current tip on the branch “main” in the “upstream” repository is equal to the current tip on the branch “main” in the “mine” repository, as well as the tip of the “main” repository locally.
Making your local changes
So, while you could just keep using just the upstream project’s code (and doing the above groundwork is good practice to keep you from putting yourself into the situation that the NPM world got into with “left-pad”). What’s more likely is that you want to make your own, local changes to this repository. I’ve done this in the past where I wanted to demonstrate a software build using a public machine image, but internally at work we used our own images. Using this method, I can consume the code I’ve created in public, and just update the assets we use at work.
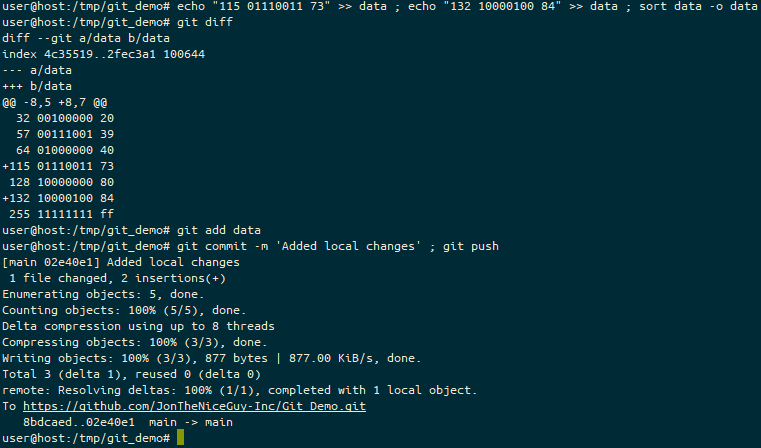
In this example, let’s update that data file. I’ve added two new lines, “115” (and it’s binary/hex representations) and “132”. I can use the git diff command to confirm the changes I want to make – it’s all good!
Next, I stage the changes with git add, use git commit to write it to the branch, and git push to push it up to my repository. This is all fairly standard stuff in the Git world.
Here we make a change to the data source, confirm there is a difference, add and commit it, and then push it to our default branch (mine/main).
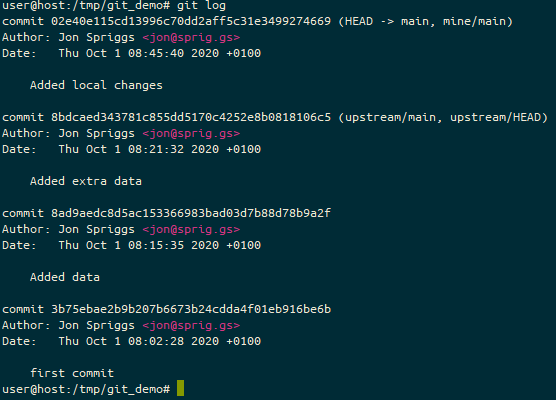
When I then check the git log, we see that there’s a divergence, between my local main branch and the upstream main branch. You could also use git log -p to see the exact code changes, if you wanted… but we know what’s changed already.
The git log, showing that we have a “local” change from the “upstream” source, and that we’ve pushed that local change to the “mine” source.
Bringing data from the upstream source
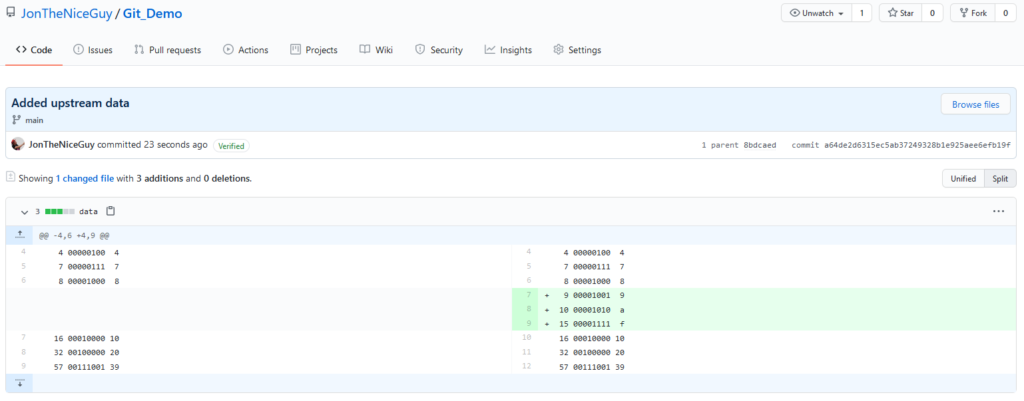
Oh joy! The upstream project (“JonTheNiceGuy” not “JonTheNiceGuy-Inc”) have updated their Git_Demo repository – they’ve had the audacity to add three new numbers – 9, 10 and 15 – to the data source.
The patch that was applied to this branch. We can check the difference here before we try to do anything with it! It’s something we want!
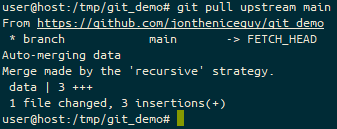
Well, actually we want to use that data, so let’s start bringing it in. We use the git pull command.
The git pull command, with the remote source (“upstream”) and the branch (“main”) to use.
Because this makes a change to a file that you’ve amended as part of your work, it can’t perform a “Fast forward” of these changes, so Git has to perform a merge commit. This means there’s a new commit in the log, so it’s clear that we’ve updated files because of this merge.
If there were a conflict in this file (which, fortunately, there isn’t!) you’d also be prompted to fix the merge conflicts too. This is a bit bigger than what I’m trying to explain, so instead, I’ll link to a tutorial by Atlassian on merge conflicts. You may also want to take a quick look at the rebasing page on the Git Project’s documentation site, and see whether this might have made your life easier in the case of a conflict!
Anyway, let’s use the default merge message.
The default message when performing a git pull where the change can’t be fast-forwarded.
Once the merge message is done, the merge completes. Yey!
We successfully merged our change, and it’s now part of our local tree
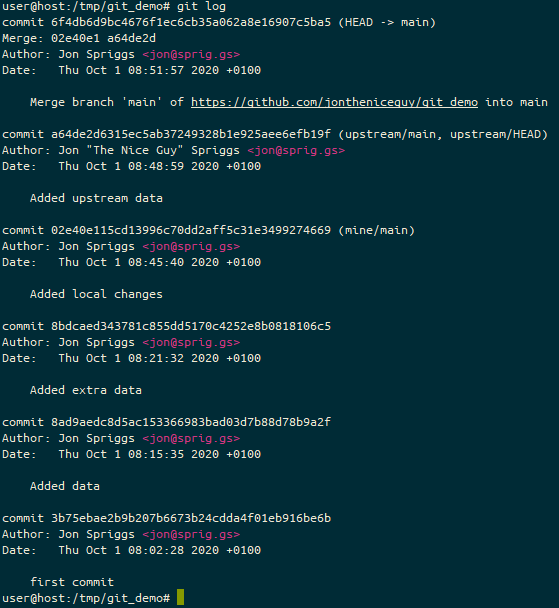
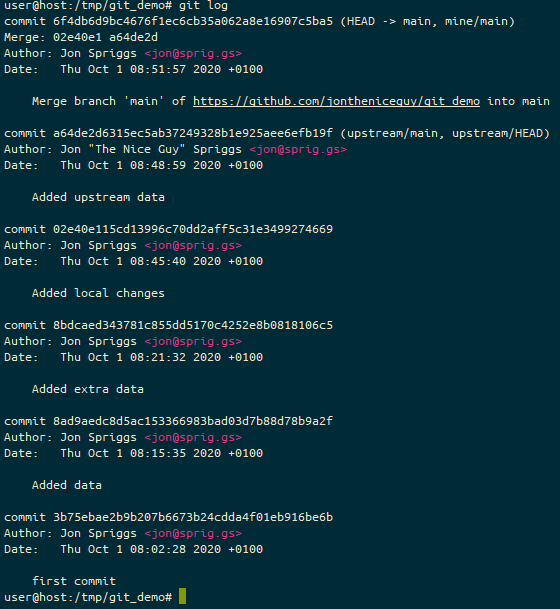
And to prove it, we can now see that we have all the changes from the upstream (commits starting 3b75eb, 8ad9ae, 8bdcae and the new one at a64de2) and our local changes (starting 02e40e).
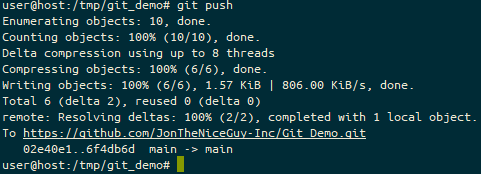
Because we performed a merge, not a fast forward, our local branch is at a different commit than either of our remote sources – the commit starting 6f4db6 is on our local version, “upstream” is at a64de2 and “mine” is at 02e40e. So we need to fix at least our “mine/main” branch. We do this with a git push.
We do our git push here to get the code into our “mine/main” branch.
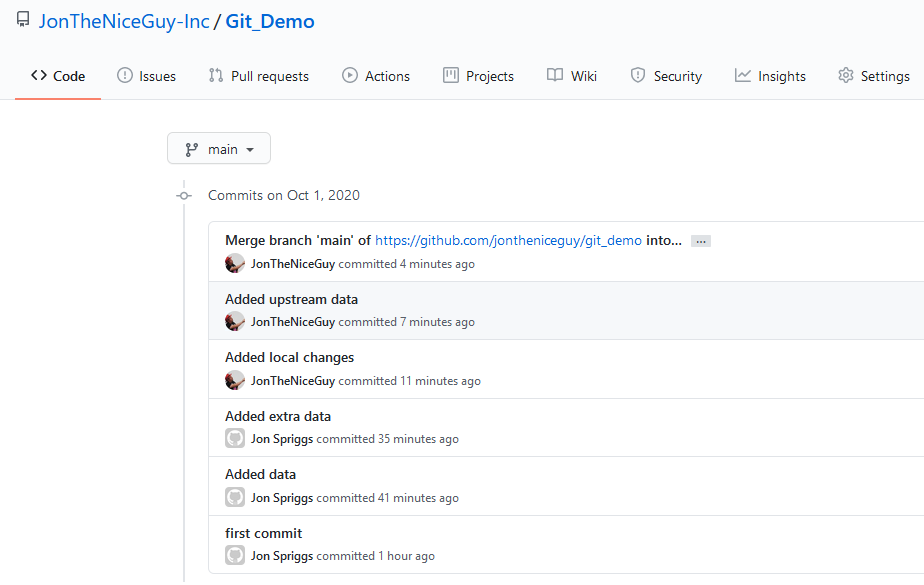
And now we can see the git log on our service.
The list of commits on Github for our “mine/main” branch.
And locally, we can see that the remote state has changed too. Let’s look at that git log again.
The result of the git log command on our local machine, showing the new position of the pointers for “upstream/main”, “mine/main” and the local “main” branches.
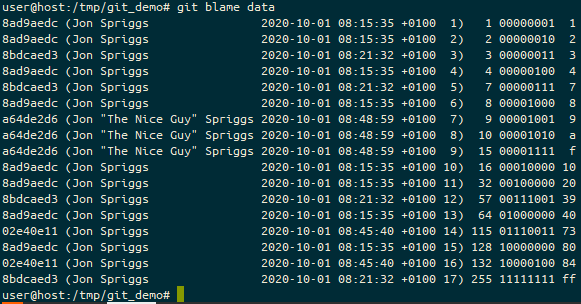
We can also look at the git blame on the service.
The git blame screen on GitHub, showing who made the various commits.
Or on our local machine.
git blame run locally, showing the commit reference, the author, the date and time of the commit, and the line number, followed by the line in question.