Several months ago, I wrote a post talking about Architectural Decision Records with adr-tools, but since then I’ve moved on a bit with things, so I wanted to write about alternatives.
Late edit 2021-12-14: I released (v0.0.1) my own rust-based application for creating Decision Records. Please feel free to make pull requests, raise issues, etc :)
I also wanted to comment a bit on why I use the term “Decision Records” (always “decision record”, never “DR” due to the overloading of that particular abbreviation) rather than “Architectural Decision Records” (ADR), but I’ll get to that towards the end of the post 😊
Using Decision Records the Manual Way
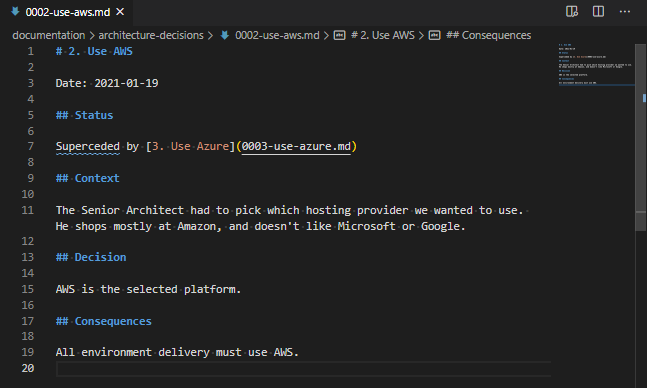
A decision record is usually basically a text file, using the “Markdown” format, which has several “standard” blocks of text in it. The “npryce” version, which most people use, has the following sections in it:
- Title (as a “level 1” heading) which also holds the date of the record.
- A (level 2 heading) status section, holding the status of this decision (and any links to documents which supersede or relate to this decision).
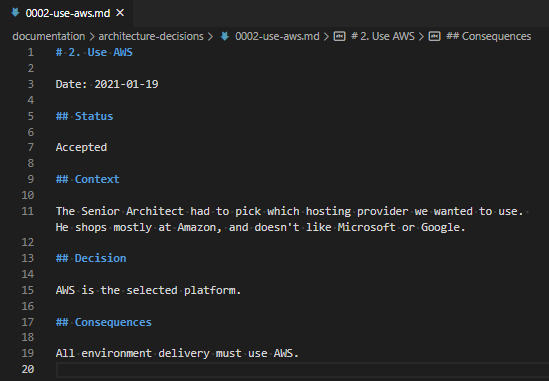
- The context of the decision.
- The decision.
- The consequences of that decision.
So, somewhat understandably, your organisational tooling should support you making your own documents, without using those tools.
There are conventions about how the index-critical details will be stored:
- Your title block should follow the format
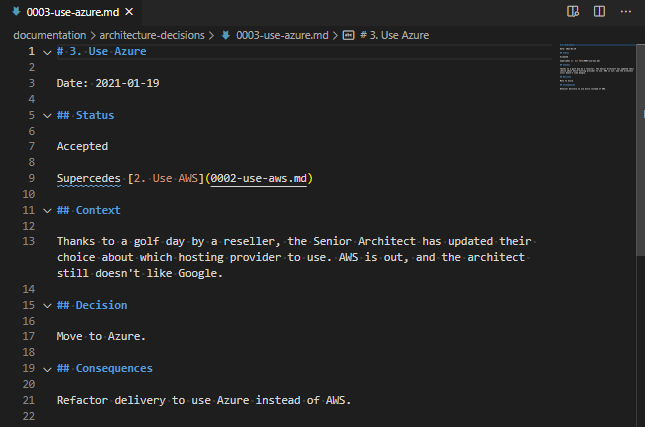
# 1. Decision Title. The#symbol means it is the primary heading for the document, then the number, which should probably be lower than 9999, is used as an index for linking to other records and then the text of the title should also be the name of the file you’ve created. In this case, it will likely be0001-decision-title.md. - The status will usually be one of:
ApprovedorProposed. If a document is superseded, it should remove this status. Any other link type will live under the line showing the current status.
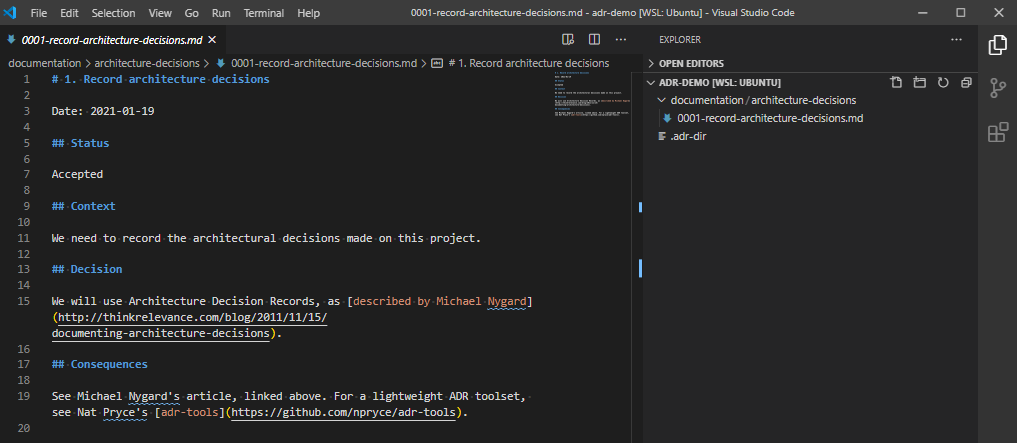
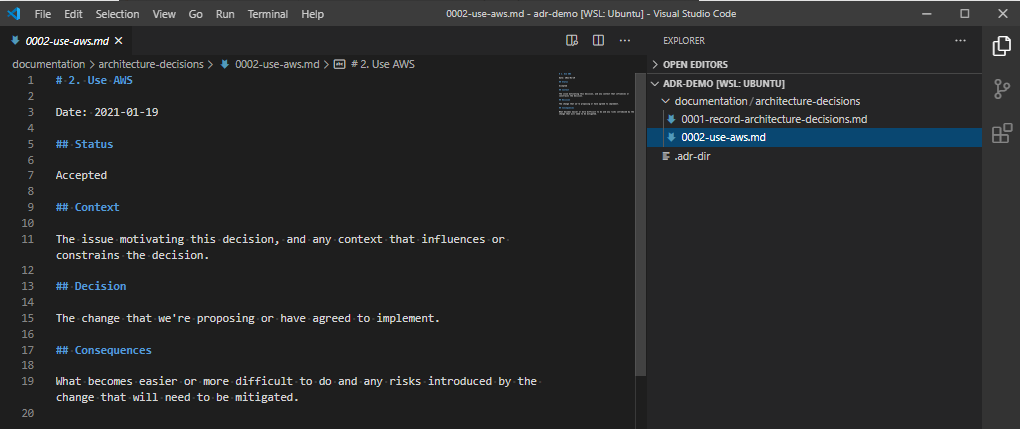
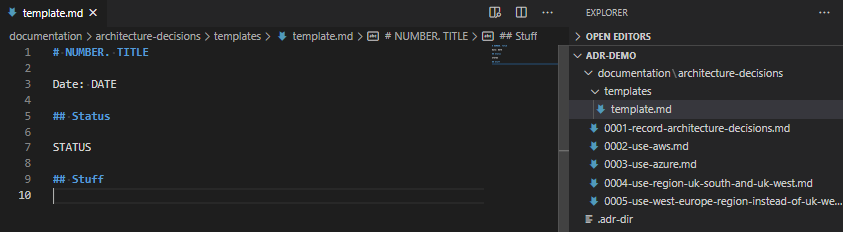
So, there’s no reason why you couldn’t just use this template for any files you create:
# NUMBER. TITLE
Date: yyyy-mm-dd
## Status
Accepted
Superseded by [2. Another Decision](0002-another-decision.md)
## Context
The context of the decision.
## Decision
The decision.
## Consequences
The consequences of that decision.BUT, that’s not very automated, is it?
ADRs using Bash
Of course, most people making decision records use the Bash command line….. right? Oh, perhaps not. I’ll get back to you in a tic. If you’re using Bash, the “npryce” tooling I mentioned above is the same one I wrote about those months ago. So, read that, and then crack on with your ADRs.
ADRs using Powershell
So, if you’re using Windows, you might be tempted to find a decision record tool for Powershell. If so, I found “ajoberstar” on Github had produced just such a thing, and you “just”, as an administrator, run:
Install-Module -Name ArchitectureDecisionRecords
Set-ExecutionPolicy -ExecutionPolicy RemoteSignedThen edit the script you installed (in C:\Program Files\WindowsPowerShell\Modules\ArchitectureDecisionRecords\0.1.1\ArchitectureDecisionRecords.psm1) and search-and-replace UTF8NoBOM for UTF8 and then save it…
And then you can run commands like Initialize-Adr or New-Adr -Title 'Use a database'. However, this script was last touched on 2nd July 2018, and although I’ve raised a few issues, they don’t seem to have been resolved (see also replacing UTF8NoBOM above).
ADRs using VSCode
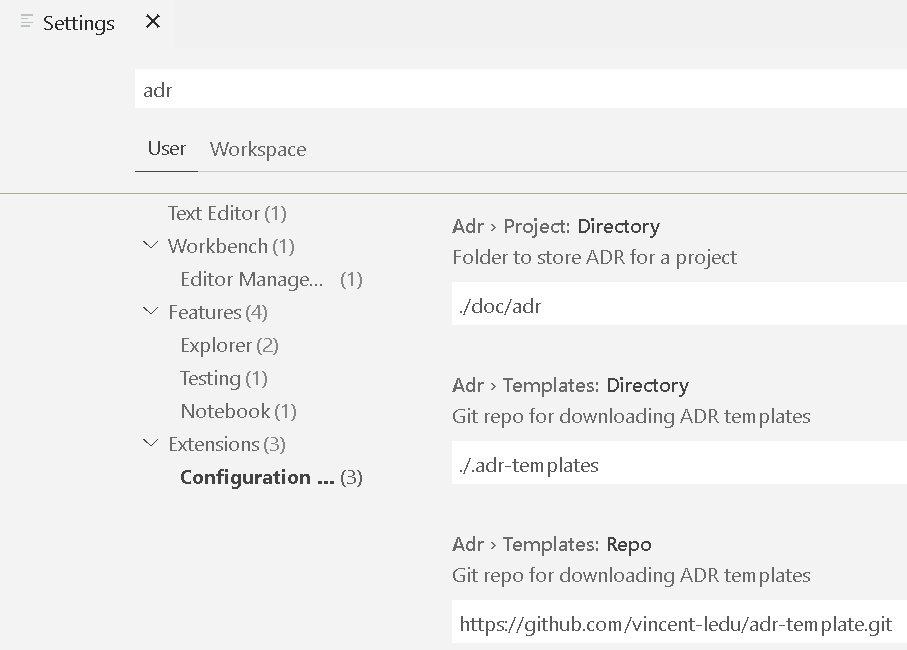
By far, so far, the best tooling I’ve seen in this space is the adr-tools extension for VSCode. It too, however, has it’s own caveats, but these are not disastrous. Essentially, you need to create a path in which you store the template to use. You can get this from his own repo, here: https://github.com/vincent-ledu/adr-template.git and put it in .adr-templates in the root directory of your project. This, however, is customizable, by going to the settings for your user or workspace, searching for ADR and adjusting the paths accordingly.
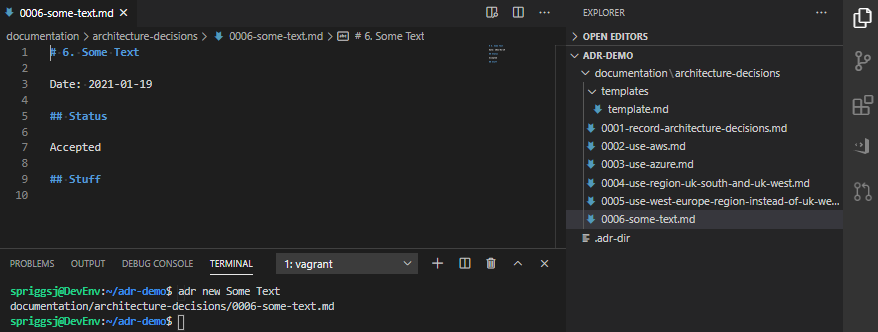
To add a new decision record, press Ctrl+Shift+P or click the cog icon in the sidebar, and select “Command Palette…”
Then start typing “adr” to select from “ADR New”, “ADR Init”, “ADR Change Status” or “ADR Link”.
All of these will walk you through some options at the top of the screen, either asking for some text input, or asking you to select between options.
You may be tempted to just run this up now, and select “ADR New”, and it’ll look like it’s working, but, you first need to have obtained the template and create the directory structure. Selecting “ADR Init” will create the directory structure for your project and will try to perform a git clone of the repo mentioned above, but if you are already in a git repository, or you have some form of MITM proxy in the way, this will also break silently. The easiest thing to do is to either manually create the paths in your tree, according to what you have set or selected, or just run the ADR init, and then obtain the template from the git repo.
Talking of templates, in the previous scripts, the script would come with a template file built-in, and it would do a simple string replacement of the values “NUMBER”, “TITLE” and “STATUS”. With this script it instead uses it’s own template, which is stored in your project’s file tree, and uses parameter substitution, finding strings wrapped in pairs of curled braces (like {{ this }}). The downside to this is that you can’t just reuse the template I listed above… but no worries, get the file from the repo and stick it in your tree where it’s expecting it, or let the adr init function clone the template into your path – job done.
What other options are there?
Well, actually, this comes down to why I’m using the term “decision records” rather than “architectural decision record”, because I’m writing my own tool, and all the “adr” namespaces on Github were taken, and I’d seen a fair amount of posts suggesting that the “A” in “ADR” should stand for “Any”.. and I figured why should it exist at all?
The tool I’ve written so far is written in Javascript, and is starting from a (somewhat loose) TDD development process. It’s here: https://github.com/DecisionRecords/javascript-decision-records
Why Javascript? Frankly, I needed to learn a modern programming language, and wanted to apply it to a domain I was interested in. It’s currently not complete, it creates the record path and a configuration file, and I’m currently writing the functions to create new records. Also, because it’s Javascript, in theory I can also use the internals to create a VSCode extension with this later… MUCH later!
Why re-implement this at all? Firstly, it looks like most of the development work on those projects halted around 3-4 years ago, with no further interest in updating them to resolve bugs and issues. I didn’t want to fork the projects as-is, as I think they were largely written to scratch a particular itch (which is fine!) but they all miss key things I want to provide, like proper unit testing (only the npryce project comes close to this), internationalisation (none of them have this) and the ability to use a company- or project-wide template (only the VSCode extension does this). I also saw requests to support alternative file formats (like Restructured Text, which was completely rejected) and realised that if you built the script in such a way that these alternate formats could be used, then there was no reason not to support that.
In summary
There are tools you can use, whatever platform you’re using. My preference is the VSCode extension, and eventually will (hopefully!!) be the script I’m writing… but it’s not ready, yet.
Featured image is “Platform” by “Brian Crawford” on Flickr and is released under a CC-BY license.