I have been playing again, recently, with Nebula, an Open Source Peer-to-Peer VPN product which boasts speed, simplicity and in-built firewalling. Although I only have a few nodes to play with (my VPS, my NAS, my home server and my laptop), I still wanted to simplify, for me, the process of onboarding devices. So, naturally, I spent a few evenings writing a bash script that helps me to automate the creation of my Nebula nodes.
Nebula Certificates
Nebula have implemented their own certificate structure. It’s similar to an x509 “TLS Certificate” (like you’d use to access an HTTPS website, or to establish an OpenVPN connection), but has a few custom fields.
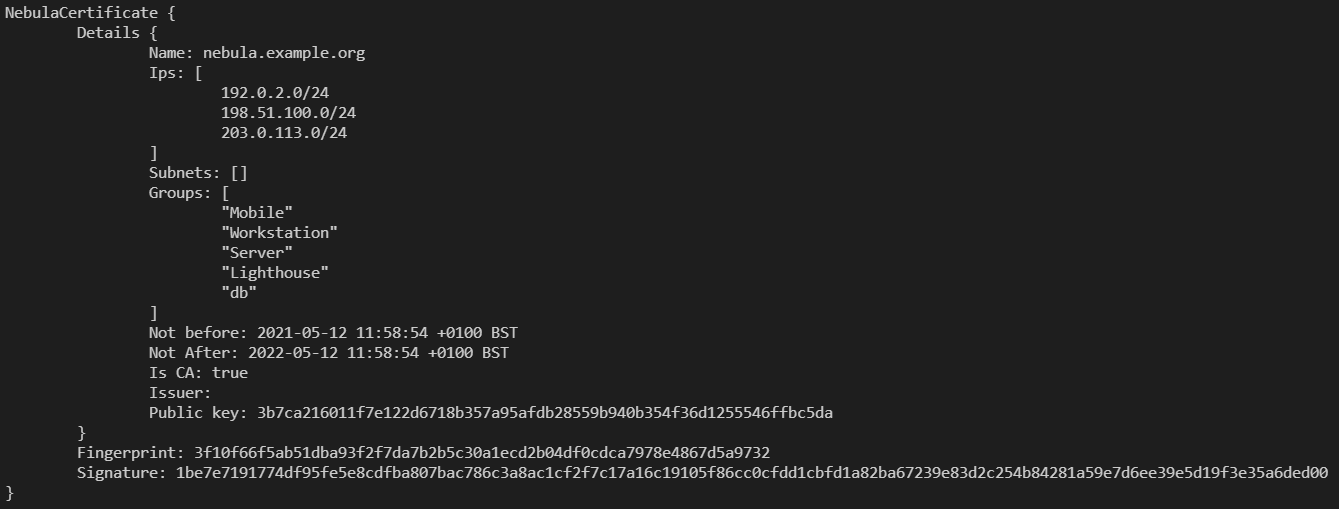
nebula-cert print -path ca.crt” to print the custom fieldsIn this context, I’ve created a nebula Certificate Authority (CA), using this command:
nebula-cert ca -name nebula.example.org -ips 192.0.2.0/24,198.51.100.0/24,203.0.113.0/24 -groups Mobile,Workstation,Server,Lighthouse,dbSo, what does this do?
Well, it creates the certificate and private key files, storing the name for the CA as “nebula.example.org” (there’s a reason for this!) and limiting the subnets and groups (like AWS or Azure Tags) the CA can issue certificates with.
Here, I’ve limited the CA to only issue IP addresses in the RFC5737 “Documentation” ranges, which are 192.0.2.0/24, 198.51.100.0/24 and 203.0.113.0/24, but this can easily be expanded to 10.0.0.0/8 or lots of individual subnets (I tested, and proved 1026 separate subnets which worked fine).
Groups, in Nebula parlance, are building blocks of the Security product, and can act like source or destination filters. In this case, I limited the CA to only being allowed to issue certificates with the groups of “Mobile”, “Workstation”, “Server”, “Lighthouse” and “db”.
As this certificate authority requires no internet access, and only enough access to read and write files, I have created my Nebula CA server on a separate Micro SD card to use with a Raspberry Pi device, and this is used only to generate a new CA certificate each 6 months (in theory, I’ve not done this part yet!), and to sign keys for all the client devices as they come on board.
I copy the ca.crt file to my target machines, and then move on to creating my client certificates
Client Certificates
When you generate key materials for Public Key Cryptographic activities (like this one), you’re supposed to generate the private key on the source device, and the private key should never leave the device on which it’s generated. Nebula allows you to do this, using the nebula-cert command again. That command looks like this:
nebula-cert keygen -out-key host.key -out-pub host.pubIf you notice, there’s a key difference at this point between Nebula’s key signing routine, and an x509 TLS style certificate, you see, this stage would be called a “Certificate Signing Request” or CSR in TLS parlance, and it usually would specify the record details for the certificate (normally things like “region”, “organisational unit”, “subject name” and so on) before sending it to the CA for signing (marking it as trusted).
In the Nebula world, you create a key, and send the public part of that (in this case, “host.pub” but it can have any name you like) to the CA, at which point the CA defines what IP addresses it will have, what groups it is in, and so on, so let’s do that.
nebula-cert sign -ca-crt ca.crt -ca-key ca.key -in-pub host.pub -out-crt host.crt -groups Workstation -ip 192.0.2.5/24 -name host.nebula.example.orgLet’s pick apart these options, shall we? The first four flags “-ca-crt“, “-ca-key“, “-in-pub” and “-out-crt” all refer to the CSR process – it’s reading the CA certificate and key, as well as the public part of the keypair created for the process, and then defines what the output certificate will be called. The next switch, -groups, identifies the tags we’re assigning to this node, then (the mandatory flag) -ip sets the IP address allocated to the node. Note that the certificate is using one of the valid group names, and has been allocated a valid IP address address in the ranges defined above. If you provide a value for the certificate which isn’t valid, you’ll get a warning message.

In the above screenshot, I’ve bypassed the key generation and asked for the CA to sign with values which don’t match the constraints.
The last part is the name of the certificate. This is relevant because Nebula has a DNS service which can resolve the Nebula IPs to the hostnames assigned on the Certificates.
Anyway… Now that we know how to generate certificates the “hard” way, let’s make life a bit easier for you. I wrote a little script – Nebula Cert Maker, also known as certmaker.sh.
certmaker.sh
So, what does certmaker.sh do that is special?
- It auto-assigns an IP address, based on the MD5SUM of the FQDN of the node. It uses (by default) the first CIDR mask (the IP range, written as something like
192.0.2.0/24) specified in the CA certificate. If multiple CIDR masks are specified in the certificate, there’s a flag you can use to select which one to use. You can override this to get a specific increment from the network address. - It takes the provided name (perhaps
webserver) and adds, as a suffix, the name of the CA Certificate (likenebula.example.org) to the short name, to make the FQDN. This means that you don’t need to run a DNS service for support staff to access machines (perhaps you’ll have webserver1.nebula.example.org and webserver2.nebula.example.org as well as database.nebula.example.org). - Three “standard” roles have been defined for groups, these are “Server”, “Workstation” and “Lighthouse” [1] (the latter because you can configure Lighthouses to be the DNS servers mentioned in step 2.) Additional groups can also be specified on the command line.
[1] A lighthouse, in Nebula terms, is a publically accessible node, either with a static IP, or a DNS name which resolves to a known host, that can help other nodes find each other. Because all the nodes connect to it (or a couple of “it”s) this is a prime place to run the DNS server, as, well, it knows where all the nodes are!
So, given these three benefits, let’s see these in a script. This script is (at least currently) at the end of the README file in that repo.
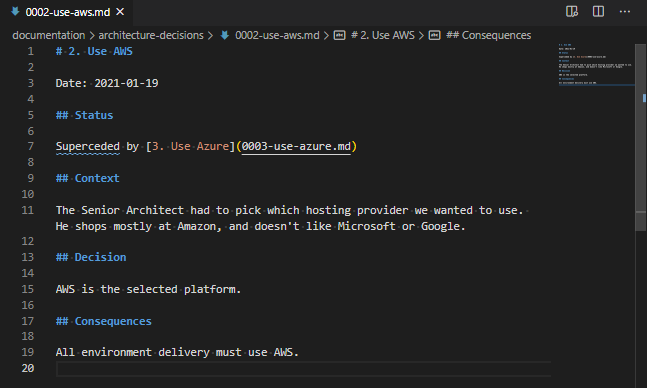
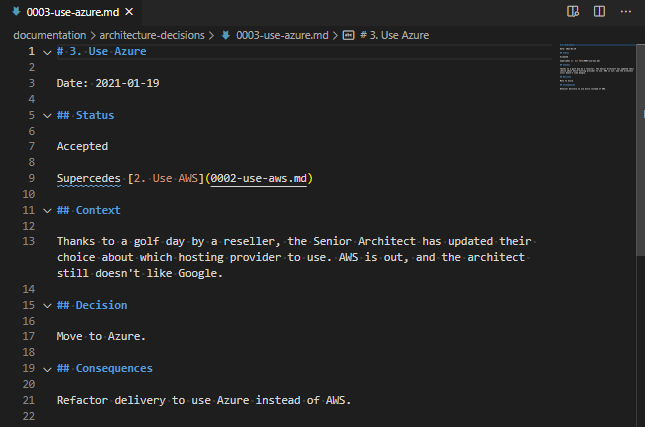
# Create the CA
mkdir -p /tmp/nebula_ca
nebula-cert ca -out-crt /tmp/nebula_ca/ca.crt -out-key /tmp/nebula_ca/ca.key -ips 192.0.2.0/24,198.51.100.0/24 -name nebula.example.org
# First lighthouse, lighthouse1.nebula.example.org - 192.0.2.1, group "Lighthouse"
./certmaker.sh --cert_path /tmp/nebula_ca --name lighthouse1 --ip 1 --lighthouse
# Second lighthouse, lighthouse2.nebula.example.org - 192.0.2.2, group "Lighthouse"
./certmaker.sh -c /tmp/nebula_ca -n lighthouse2 -i 2 -l
# First webserver, webserver1.nebula.example.org - 192.0.2.168, groups "Server" and "web"
./certmaker.sh --cert_path /tmp/nebula_ca --name webserver1 --server --group web
# Second webserver, webserver2.nebula.example.org - 192.0.2.191, groups "Server" and "web"
./certmaker.sh -c /tmp/nebula_ca -n webserver2 -s -g web
# Database Server, db.nebula.example.org - 192.0.2.182, groups "Server" and "db"
./certmaker.sh --cert_path /tmp/nebula_ca --name db --server --group db
# First workstation, admin1.nebula.example.org - 198.51.100.205, group "Workstation"
./certmaker.sh --cert_path /tmp/nebula_ca --index 1 --name admin1 --workstation
# Second workstation, admin2.nebula.example.org - 198.51.100.77, group "Workstation"
./certmaker.sh -c /tmp/nebula_ca -d 1 -n admin2 -w
# First Mobile device - Create the private/public key pairing first
nebula-cert keygen -out-key mobile1.key -out-pub mobile1.pub
# Then sign it, mobile1.nebula.example.org - 198.51.100.217, group "mobile"
./certmaker.sh --cert_path /tmp/nebula_ca --index 1 --name mobile1 --group mobile --public mobile1.pub
# Second Mobile device - Create the private/public key pairing first
nebula-cert keygen -out-key mobile2.key -out-pub mobile2.pub
# Then sign it, mobile2.nebula.example.org - 198.51.100.22, group "mobile"
./certmaker.sh -c /tmp/nebula_ca -d 1 -n mobile2 -g mobile -p mobile2.pubTechnically, the mobile devices are simulating the local creation of the private key, and the sharing of the public part of that key. It also simulates what might happen in a more controlled environment – not where everything is run locally.
So, let’s pick out some spots where this content might be confusing. I’ve run each type of invocation twice, once with the short version of all the flags (e.g. -c instead of --cert_path, -n instead of --name) and so on, and one with the longer versions. Before each ./certmaker.sh command, I’ve added a comment, showing what the hostname would be, the IP address, and the Nebula Groups assigned to that node.
It is also possible to override the FQDN with your own FQDN, but this command option isn’t in here. Also, if the CA doesn’t provide a CIDR mask, one will be selected for you (10.44.88.0/24), or you can provide one with the -b/--subnet flag.
If the CA has multiple names (e.g. nebula.example.org and nebula.example.com), then the name for the host certificates will be host.nebula.example.org and also host.nebula.example.com.
Using Bash
So, if you’ve looked at, well, almost anything on my site, you’ll see that I like to use tools like Ansible and Terraform to deploy things, but for something which is going to be run on this machine, I’d like to keep things as simple as possible… and there’s not much in this script that needed more than what Bash offers us.
For those who don’t know, bash is the default shell for most modern Linux distributions and Docker containers. It can perform regular expression parsing (checking that strings, or specific collections of characters appear in a variable), mathematics, and perform extensive loop and checks on values.
I used a bash template found on a post at BetterDev.blog to give me a basic structure – usage, logging and parameter parsing. I needed two functions to parse and check whether IP addresses were valid, and what ranges of those IP addresses might be available. These were both found online. To get just enough of the MD5SUM to generate a random IPv4 address, I used a function to convert the hexedecimal number that the MDSUM produces, and then turned that into a decimal number, which I loop around the address space in the subnets. Lastly, I made extensive use of Bash Arrays in this. This was largely thanks to an article on OpenSource.com about bash arrays. It’s well worth a read!
So, take a look at the internals of the script, if you want to know some options on writing bash scripts that manipulate IP addresses and read the output of files!
If you’re looking for some simple tasks to start your portfolio of work, there are some “good first issue” tasks in the “issues” of the repo, and I’d be glad to help you work through them.
Wrap up
I hope you enjoy using this script, and I hope, if you’re planning on writing some bash scripts any time soon, that you take a look over the code and consider using some of the templates I reference.
Featured image is “Observatories Combine to Crack Open the Crab Nebula” by “NASA Goddard Space Flight Center” on Flickr and is released under a CC-BY license.