Introducing Architectural Decision Records
Over the last week, I discovered a new tool for my arsenal called Architectural Decision Records (ADR). They were first written about in 2011, in a post called “Documenting Architecture Decisions“, where the author, Michael Nygard, advocates for short documents explaining each decision that influences the architecture of an environment.
I found this via a Github repository, created by the team at gov.uk, which includes their ADR library, and references the tool they use to manage these documents – adr-tools.
Late edit 2021-01-25: I also found a post which suggests that Spotify uses ADR.
Late edit 2021-08-11: I wrote a post about using other tooling.
Late edit 2021-12-14: I released (v0.0.1) my own rust-based application for making Decision Records. Yes, Decision Records – not Architecture Decision Records… because I think you should be able to apply the same logic to all decisions, not just architectural ones.
Installing adr-tools on Linux
Currently adr-tools are easier to install under OSX rather than Linux or Windows Subsystem for Linux (WSL) (I’m working on this – bear with me! 😃 ).
The current installation notes suggest for Linux (which would also work on WSL) is to download the latest release tar.gz or zip file and unpack it into your path somewhere. This isn’t exactly the best way to deploy anything on Linux, but… I guess it works right now?
For me, I downloaded the file, and unpacked the whole tar.gz file (as root) into /usr/local/bin/, giving me a directory of /usr/local/bin/adr-tools-3.0.0/. There’s a subdirectory in here, called src which contains a large number of files – mostly starting _adr or adr- and two additional files, init.md and template.md.
Rather than putting all of these files into /usr/local/bin directly, instead I leave them in the adr-tools-3.0.0 directory, and create a symbolic link (symlink) to the /usr/local/bin directory with this command:
cd /usr/local/bin
ln -s adr-tools-3.0.0/src/* .This gives me all those files in one place, so I can refer to them later.
An aside – why link everything in that src directory? (Feel free to skip this block!)
Now, why, you might ask, do all of these unrelated files need to be in the same place? Well…. the author of the script has put this in at the top of almost all the files:
#!/bin/bash
set -e
eval "$($(dirname $0)/adr-config)"And then in that script, it says:
#!/bin/bash
basedir=$(cd -L $(dirname $0) > /dev/null 2>&1 && pwd -L)
echo "adr_bin_dir=$basedir"
echo "adr_template_dir=$basedir"There are, technically, good reasons for this! This is designed to be run in, what in the Windows world, you might call as a “Portable Script”. So, you bung adr-tools into some directory somewhere, and then just call adr somecommand and it knows that all the files are where they need to be. The (somewhat) down side to this is that if you just want to call adr somecommand rather than path/to/my/adr somecommand then all those files need to be there
I’m currently looking to see if I can improve this somewhat, so that it’s not quite so complex to install, but for now, that’s what you need.
Anyway…
Using adr-tools to document your decisions
I’ll start documenting a fictional hosted web service project, and note down some of the decisions which have been made.
Initializing your ADR directory
Start by running adr init. You may want to specify a directory where you want to put these records, so instead use: adr init path/to/adr, like this:

adr init documentation/architecture-decisionsYou’ll notice that when I run this command, it creates a new entry, called 0001-record-architecture-decisions.md. Let’s open this up, and see what’s in here.
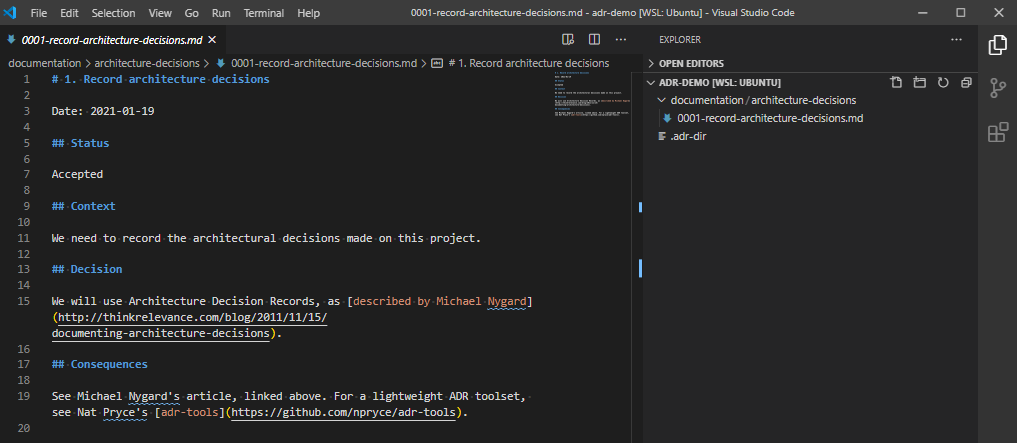
In here we have the record ID (1.), the title of the record Record architecture decisions, the date the choice was made Date: 2021-01-19, a status of Accepted, the context on why we made this choice, the decision, and the consequences of making this decision. Make changes, if needed, and save it. Let’s move on.
Creating our first own record
This all is quite straightforward thus far. Let’s create our next record.

adr new <sometitle> you create the next ADR record.Let’s open up that record.
Like the first record, we have a title, a status, a context, decision and consequences. Let’s define these.
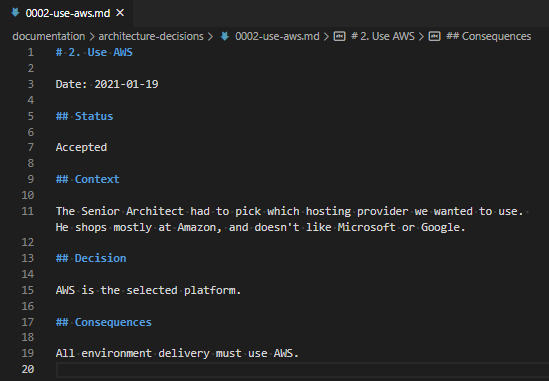
This document shouldn’t be very long! It just describes why a choice was made and what that entails.
Changing decisions – completely replacing (superseding) a decision
Of course, over time, decisions will be replaced due to various decisions elsewhere.

adr to supersede a previous record, using the “-s” flag, and the record number.Let’s look at how that works on the second ADR record.
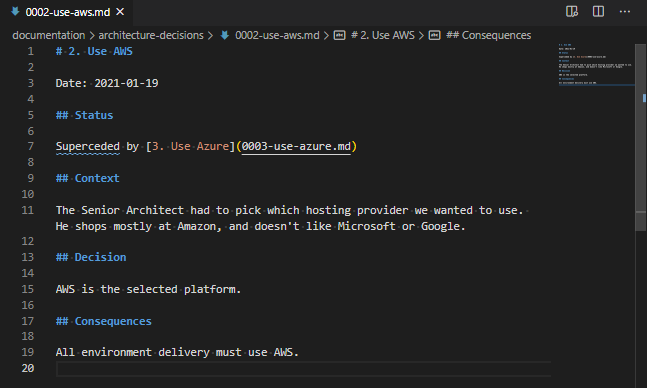
adr new -s 2 Use Azure, the ADR record number 2 has a new status, “Superceded by” and the superseded linked document. Yes, “Superceded” is a typo. There is an open PR for itSo, under the “Status”, where is previously said “Approved”, it now says “Superceded by [3. Use Azure](0003-use-azure.md)“. This is a markdown statement which indicates where the superseded document is located. As I mentioned in the comment below the above image, there is an open Pull Request to fix this on the adr-tools, so hopefully that typo won’t last long!
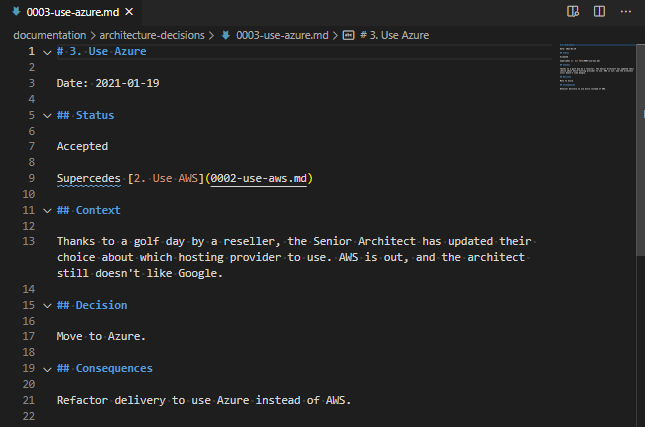
We’ve got our new ADR too – let’s take a look at that one?
Other references
Of course, you don’t always completely overrule a decision. Sometimes your decision is influenced by, or has a dependency on something else, like this one.

-l flag to “link” between the referenced and new ADR. The context for the -l flag is “<number>:<text for link to number>:<text for link in targetted document>”.The command here is:
adr new -l '3:Dependency:Influences' Use Region UK South and UK WestI’m just going to crop from the “Status” block on both the referenced ADR (3) and the ADR which references it (4):
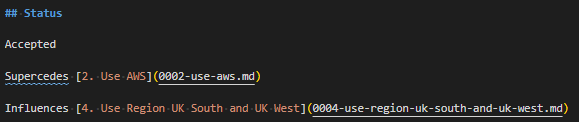

And of course, you can also use the same switch to mark documents as partially obsoleted, like this:
adr new -l '4:Partially obsoletes:Partially obsoleted by' Use West Europe region instead of UK West region
If you forget to add the referencing in, you can also use the adr link command, like this:
adr link 3 Influences 5 DependencyTo be clear, that command adds a (complete) line to ADR 0003 saying “Influences [5. ADR Title](link)” and a separate (complete) line to ADR 0005 saying “Dependency [3. ADR Title](link)“.
What else can we do?
There are four other “things” that it’s worth doing at this point.
- Note that you can change the template per-ADR directory.
Create a directory called “templates” in the ADR directory, and put a file in there called “template.md“. Tweak this as you need. Ensure you have AT LEAST the line ## Status and # NUMBER. TITLE as these are required by the script.
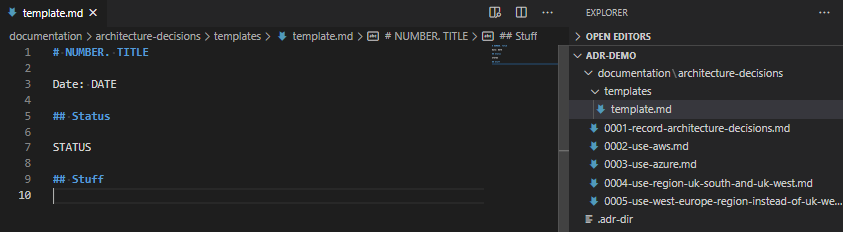
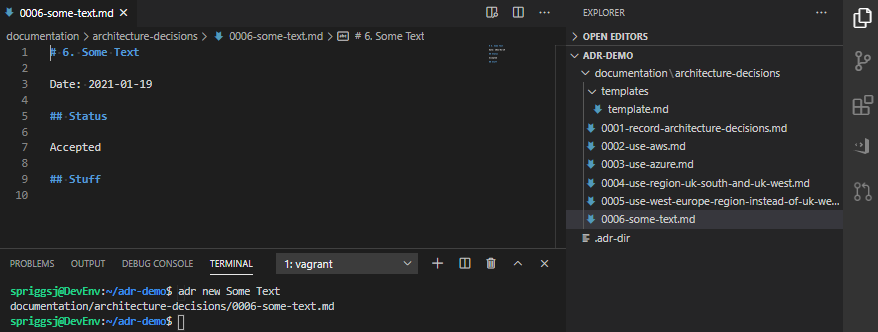
adr new Some Text once you’ve created that template.As you can see, it’s possible to add all sorts of content in this template as a result. Bear in mind, before your template turns into something like this, that it’s supposed to be a short document explaining why each decision was made, not a funding proposal, or a complex epic of your user stories!

- Note that you can automatically open an editor, by setting the
EDITOR(where the process is expected to finish before returning control, like using nano, emacs or vim, for example) orVISUAL(where the process is expected to “fork”, like for example, gedit or vscode) environment variable, and then runningadr new A Title, like this:
- We can create “Table of Contents” files, using the
adr generate toccommand, like this:

This can be included into your various other markdown files. There are switches, so you can set the link path, but your best bet is to find that using adr help generate toc.
- We can also generate graphviz files of the link maps between elements of the various ADRs, like this:
adr generate graph | dot -Tjpg > graph.jpg
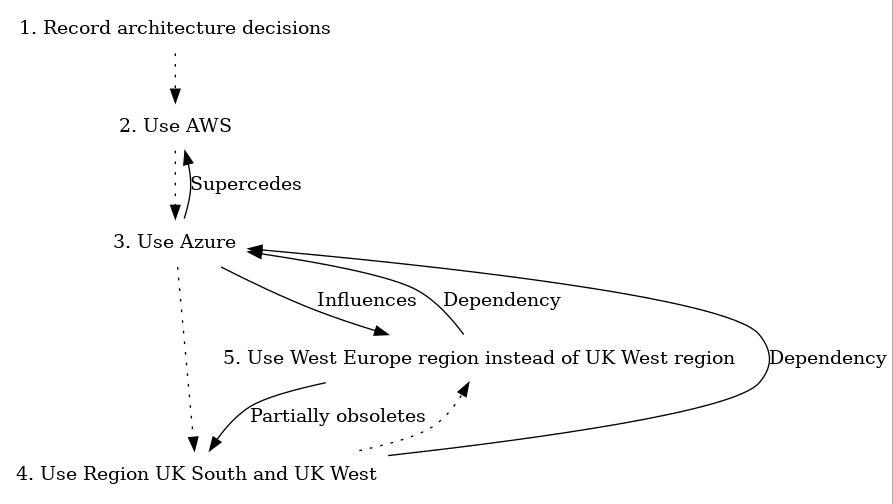
If you omit the “| dot -Tjpg > graph.jpg” part, then you’ll see the graphviz output, which looks like this: (I’ve removed the documents 6 and 7).
digraph {
node [shape=plaintext];
subgraph {
_1 [label="1. Record architecture decisions"; URL="0001-record-architecture-decisions.html"];
_2 [label="2. Use AWS"; URL="0002-use-aws.html"];
_1 -> _2 [style="dotted", weight=1];
_3 [label="3. Use Azure"; URL="0003-use-azure.html"];
_2 -> _3 [style="dotted", weight=1];
_4 [label="4. Use Region UK South and UK West"; URL="0004-use-region-uk-south-and-uk-west.html"];
_3 -> _4 [style="dotted", weight=1];
_5 [label="5. Use West Europe region instead of UK West region"; URL="0005-use-west-europe-region-instead-of-uk-west-region.html"];
_4 -> _5 [style="dotted", weight=1];
}
_3 -> _2 [label="Supercedes", weight=0]
_3 -> _5 [label="Influences", weight=0]
_4 -> _3 [label="Dependency", weight=0]
_5 -> _4 [label="Partially obsoletes", weight=0]
_5 -> _3 [label="Dependency", weight=0]
}To make the graphviz part work, you’ll need to install graphviz, which is just an apt get away.
Any caveats?
adr-tools is not actively maintained. I’ve contacted the author, about seeing if I can help out with the maintenance, but… we’ll see, and given some fairly high profile malware takeovers of projects like this sort of thing on Github, Docker, NPM, and more… I can see why there might be some reluctance to consider it! Also, I’m an unknown entity, I’ve just dropped in on the project and offered to help, with no previous exposure to the lead dev or the project… so, we’ll see. Worst case, I’ll fork it!
Working with this also requires an understanding of markdown files, and why these might be a useful document format for records like this. There was a PR submitted to support multiple file formats (like asciidoc and rst) but these were not approved by the author.
There is no current intention to support languages other than English. The tool is hard-coded to look for strings like “status” and “superceded” which is hard. Part of the reason I raised the PRs I did was to let me fix some of these sorts of issues. Again, we’ll see what happens.
Lastly, it can be overwhelming to see a lot of documents in one place, particularly if they’re as granular as the documents I produced in this demo. If the project supported categories, or could be broken down into components (like doc/adr/networking and doc/adr/server_builds and doc/adr/applications) then this might help, but it’s not on the roadmap right now!
Late edit 2021-01-25: If you don’t think these templates have enough context or content, there are lots of others listed on Joel Parker Henderson’s repo of examples and templates. If you want a python based viewer of ADR records, take a look at adr-viewer.
Featured image is “Blueprints” by “Cameron Degelia” on Flickr and is released under a CC-BY license.