I’m in the process of building a Network Firewall for a work environment. This blog post is based on that work, but with all the identifying marks stripped off.
For this particular project, we standardised on Alma Linux 9 as the OS Base, and we’ve done some testing and proved that the RedHat default firewalling product, Firewalld, is not appropriate for this platform, but did determine that NFTables, or NetFilter Tables (the successor to IPTables) is.
I’ll warn you, I’m pretty prone to long and waffling posts, but there’s a LOT of technical content in this one. There is also a Git repository with the final code. I hope that you find something of use in here.
This document explains how it is using Vagrant with Virtualbox to build a test environment, how it installs a Puppet Server and works out how to calculate what settings it will push to it’s clients. With that puppet server, I show how to build and configure a firewall using Linux tools and services, setting up an NFTables policy and routing between firewalls using FRR to provide BGP, and then I will show how to deploy a DHCP server.
Let’s go!
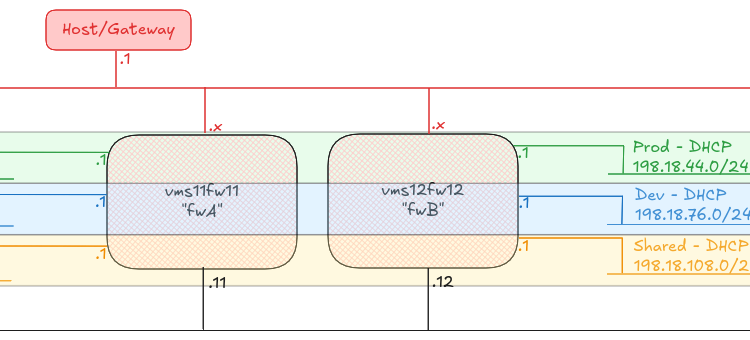
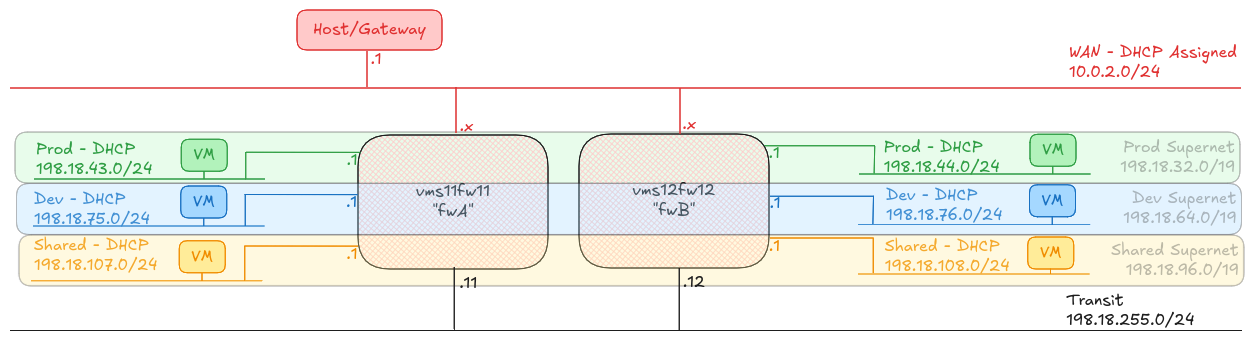
The scenario
To prove the concept, I have built two Firewall machines (A and B), plus six hosts, one attached to each of the A and B side subnets called “Prod”, “Dev” and “Shared”.
Any host on any of the “Prod” networks should be able to speak to any host on any of the other “Prod” networks, or back to the “Shared” networks. Any host on any of the “Dev” networks should be able to speak to any host on the other “Dev” networks, or back to the “Shared” networks.
Any host in Prod, Dev or Shared should be able to reach the internet, and shared can reach any of the other networks.
Tale as old as time, the compute instance type you want to use in AWS is highly contested (or worse yet, not as available in every availability zone in your region)! You plead with your TAM or AM “Please let us have more of that instance type” only to be told “well, we can put in a request, but… haven’t you thought about using a range of instance types”?
And yes, I’ve been on both sides of that conversation, sadly.
The commented terraform
# This is your legacy instance_type variable. Ideally we'd have
# a warning we could raise at this point, telling you not to use
# this variable, but... it's not ready yet.
variable "instance_type" {
description = "The legacy single-instance size, e.g. t3.nano. Please migrate to instance_types ASAP. If you specify instance_types, this value will be ignored."
type = string
default = null
}
# This is your new instance_types value. If you don't already have
# some sort of legacy use of the instance_type variable, then don't
# bother with that variable or the locals block below!
variable "instance_types" {
description = "A list of instance sizes, e.g. [t2.nano, t3.nano] and so on."
type = list(string)
default = null
}
# Use only this locals block (and the value further down) if you
# have some legacy autoscaling groups which might use individual
# instance_type sizes.
locals {
# This means if var.instance_types is not defined, then use it,
# otherwise create a new list with the single instance_type
# value in it!
instance_types = var.instance_types != null ? var.instance_types : [ var.instance_type ]
}
resource "aws_launch_template" "this" {
# The prefix for the launch template name
# default "my_autoscaling_group"
name_prefix = var.name
# The AMI to use. Calculated outside this process.
image_id = data.aws_ami.this.id
# This block ensures that any new instances are created
# before deleting old ones.
lifecycle {
create_before_destroy = true
}
# This block defines the disk size of the root disk in GB
block_device_mappings {
device_name = data.aws_ami.centos.root_device_name
ebs {
volume_size = var.disksize # default "10"
volume_type = var.disktype # default "gp2"
}
}
# Security Groups to assign to the instance. Alternatively
# create a network_interfaces{} block with your
# security_groups = [ var.security_group ] in it.
vpc_security_group_ids = [ var.security_group ]
# Any on-boot customizations to make.
user_data = var.userdata
}
resource "aws_autoscaling_group" "this" {
# The name of the Autoscaling Group in the Web UI
# default "my_autoscaling_group"
name = var.name
# The list of subnets into which the ASG should be deployed.
vpc_zone_identifier = var.private_subnets
# The smallest and largest number of instances the ASG should scale between
min_size = var.min_rep
max_size = var.max_rep
mixed_instances_policy {
launch_template {
# Use this template to launch all the instances
launch_template_specification {
launch_template_id = aws_launch_template.this.id
version = "$Latest"
}
# This loop can either use the calculated value "local.instance_types"
# or, if you have no legacy use of this module, remove the locals{}
# and the variable "instance_type" {} block above, and replace the
# for_each and instance_type values (defined as "local.instance_types")
# with "var.instance_types".
#
# Loop through the whole list of instance types and create a
# set of "override" values (the values are defined in the content{}
# block).
dynamic "override" {
for_each = local.instance_types
content {
instance_type = local.instance_types[override.key]
}
}
}
instances_distribution {
# If we "enable spot", then make it 100% spot.
on_demand_percentage_above_base_capacity = var.enable_spot ? 0 : 100
spot_allocation_strategy = var.spot_allocation_strategy
spot_max_price = "" # Empty string is "on-demand price"
}
}
}
So what is all this then?
This is two Terraform resources; an aws_launch_template and an aws_autoscaling_group. These two resources define what should be launched by the autoscaling group, and then the settings for the autoscaling group.
You will need to work out what instance types you want to use (e.g. “must have 16 cores and 32 GB RAM, have an x86_64 architecture and allow up to 15 Gigabit/second throughput”)
When might you use this pattern?
If you have been seeing messages like “There is no Spot capacity available that matches your request.” or “We currently do not have sufficient <size> capacity in the Availability Zone you requested.” then you need to consider diversifying the fleet that you’re requesting for your autoscaling group. To do that, you need to specify more instance types. To achieve this, I’d use the above code to replace (something like) one of the code samples below.
Then this new method is a much better idea :) Even more so if you had two launch templates to support spot and non-spot instance types!
Hat-tip to former colleague Paul Moran who opened my eyes to defining your fleet of variable instance types, as well as to my former customer (deliberately unnamed) and my current employer who both stumbled into the same documentation issue. Without Paul’s advice with my prior customer’s issue I’d never have known what I was looking for this time around!
In my current role we are using Packer to build images on a Xen Orchestrator environment, use a CI/CD system to install that image into both a Xen Template and an AWS AMI, and then we use Terraform to use that image across our estate. The images we build with Packer have this stanza in it:
But, because Xen doesn’t track when a template is created, instead I needed to do something different. Enter get_xoa_template.sh.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
[ -z "$TEMPLATE_IS" ] && fail "Could not match this template" 4
if [ -n "$DEBUG" ]
then
echo "{\"is\": ${TEMPLATE_IS}}" | tee -a "$DEBUG"
else
echo "{\"is\": ${TEMPLATE_IS}}"
fi
}
[ -n "$(command -v xo-cli)" ] || fail "xo-cli is missing, and is a required dependency for this script. Please install it; \`sudo npm -g install xo-cli\`" 5
This script is invoked from your terraform like this:
variable "template_name" {
default = "SomeLinux-version.iso-"
description = "A regex, partial or full string to match in the template name"
}
variable "poolname" {
default = "MyPool"
}
data "external" "get_xoa_template" {
program = [
"/bin/bash", "${path.module}/get_xoa_template.sh",
"--template", var.template_name,
"--pool", var.poolname
]
}
data "xenorchestra_pool" "pool" {
name_label = var.poolname
}
data "xenorchestra_template" "template" {
name_label = data.external.get_xoa_template.result.is
pool_id = data.xenorchestra_pool.pool.id
}
And that’s how you do it. Oh, and if you need to pin to a specific version? Change the template_name value from the partial or regex version to the full version, like this:
variable "template_name" {
# This assumes your image was minted at midnight on 1970-01-01
default = "SomeLinux-version.iso-19700101000000"
}
In my current project I am often working with Infrastructure as Code (IoC) in the form of Terraform and Terragrunt files. Before I joined the team a decision was made to use SOPS from Mozilla, and this is encrypted with an AWS KMS key. You can only access specific roles using the SAML2AWS credentials, and I won’t be explaining how to set that part up, as that is highly dependant on your SAML provider.
While much of our environment uses AWS, we do have a small presence hosted on-prem, using a hypervisor service. I’ll demonstrate this with Proxmox, as this is something that I also use personally :)
Firstly, make sure you have all of the above tools installed! For one stage, you’ll also require yq to be installed. Ensure you’ve got your shell hook setup for direnv as we’ll need this later too.
Late edit 2023-07-03: There was a bug in v0.22.0 of the terraform which didn’t recognise the environment variables prefixed PROXMOX_VE_ – a workaround by using TF_VAR_PROXMOX_VE and a variable "PROXMOX_VE_" {} block in the Terraform code was put in place for the inital publication of this post. The bug was fixed in 0.23.0 which this post now uses instead, and so as a result the use of TF_VAR_ prefixed variables was removed too.
Set up AWS Vault
AWS KMS
AWS Key Management Service (KMS) is a service which generates and makes available encryption keys, backed by the AWS service. There are *lots* of ways to cut that particular cake, but let’s do this a quick and easy way… terraform
So far, so good… but wait, you’ve authenticated to your SAML access to AWS. Let’s close that shell, and go back in again
$ cd /path/to/demo
direnv: loading /path/to/demo/.envrc
direnv: using sops
$
Ah, now we don’t have our values exported. That’s what we wanted!
What now?!
Configuring the details of the proxmox cluster
We have our .envrc file which provides our credentials (let’s pretend we’re using a shared set of credentials across all the boxes), but now we need to setup access to each of the boxes.
Let’s make our two cluster directories;
mkdir cluster_01
mkdir cluster_02
And in each of these clusters, we need to put an .envrc file with the right IP address in. This needs to check up the tree for any credentials we may have already loaded:
source_env "$(find_up ../.envrc)"
export PROXMOX_VE_ENDPOINT="https://192.0.2.1:8006" # Documentation IP address for the first cluster - change for the second cluster.
The first line works up the tree, looking for a parent .envrc file to inject, and then, with the second line, adds the Proxmox API endpoint to the end of that chain. When we run direnv allow (having logged back into our saml2aws session), we get this:
Then in the cluster_01 directory, create a directory for the code you want to run (e.g. create a VLAN might be called “VLANs/30/“) and put in it this terragrunt.hcl
This assumes you have a terraform directory called terraform-module-network/vlan in a particular place in your tree or even better, a module in your git repo, which uses the input values you’ve provided.
That double slash in the source line isn’t a typo either – this is the point in that tree that Terragrunt will copy into the directory to run terraform from too.
A quick note about includes and provider blocks
The other key thing is that the “include” block loads the values from the first matching terragrunt.hcl file in the parent directories, which in this case is the one which defined the providers block. You can’t include multiple different parent files, and you can’t have multiple generate blocks either.
Running it all together!
Now we have all our depending files, let’s run it!
user@host:~$ cd test
direnv: loading ~/test/.envrc
direnv: using sops
user@host:~/test$ saml2aws login --skip-prompt --quiet ; saml2aws exec -- bash
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test$ cd cluster_01/VLANs/30
direnv: loading ~/test/cluster_01/.envrc
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_ENDPOINT +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test/cluster_01/VLANs/30$ terragrunt apply
data.proxmox_virtual_environment_nodes.available_nodes: Reading...
data.proxmox_virtual_environment_nodes.available_nodes: Read complete after 0s [id=nodes]
Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# proxmox_virtual_environment_network_linux_bridge.this[0] will be created
+ resource "proxmox_virtual_environment_network_linux_bridge" "this" {
+ autostart = true
+ comment = "VLAN30"
+ id = (known after apply)
+ mtu = (known after apply)
+ name = "vmbr30"
+ node_name = "proxmox01"
+ ports = [
+ "enp3s0.30",
]
+ vlan_aware = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
proxmox_virtual_environment_network_linux_bridge.this[0]: Creating...
proxmox_virtual_environment_network_linux_bridge.this[0]: Creation complete after 2s [id=proxmox01:vmbr30]
user@host:~/test/cluster_01/VLANs/30$
Slides: Available to view (Firefox/Chrome recommended – press “S” to see the required speaker notes)
Video: There was a stream recorded on the day, however, due to the technical issues detailed below, I uploaded a better, pre-recorded version, after the event.
Slot: Room 1, 14:30-15:00
Notes: Wow, this probably had the worst technical issues of any of my talks so far.
In the morning before the talk, I checked my talk, and realised the speaker notes were still the long-form version I’d written for the recording… so I jumped into the editor and started putting the bullet-points in. I checked the output, and the formatting had all changed! Oh no, what had I done? Well, actually, a recent update to the presenter plugin I use for WordPress had moved the location of all the theme CSS files… fortunately, I’d had this happen to me before, so I knew what to look for – but for 10 minutes, I thought editing the speaker notes had properly caused me issues! Thank goodness for SSH!!
In the actual venue, in the morning, I was told that they’d moved the room allocations for everything in Slot 1, because they needed to run to pre-recorded videos for speakers who couldn’t attend in there. No worries! I said! We get to the afternoon, and they let me know that I’m in Room 1, as they’d finished screening the videos… The adjustments to the schedule is probably the one (small) issue I have had with BSides Liverpool – but having been involved with OggCamp, I know how hard this piece is!
I head to Room 1 and set up, but it’s the first time I tried to deliver a talk using my new laptop, which doesn’t have any external video ports, so a few weeks ago, I bought an USB HDMI interface… tested it at home, and thought all was “good”. The screen they were using for Room 1 didn’t recognise the interface I was using! Oh no!! So I borrowed a laptop from one of the crew, but it didn’t have bluetooth, so I couldn’t use the “clicker” for moving my slides on, and then we’re just about to go live, and the crew tell me that the camera to use to record my talking head, is not rendering any video, and “can I use the webcam on the laptop”.. Hmmm Of course, I say yes, but it means that I need to have the Windows Camera app on screen the whole time.
Anyway, talk starts up, and part way through the presentation, I don’t notice, but the WiFi drops out, so when I get to the pre-recorded demo of running Ansible…. NOPE. Bah, OK, so I continue on, and the final images (a QR code for the project I’m plugging, and my social media avatar) are missing. Oh well. Also, part way through, I realised that the screen resolution where the slides are being rendered are basically showing up dreadfully, because the text size is so very small on the screen, and the people at the back of the room really can’t see the content!
Had some fab questions from the audience, talking about things I’ve not really thought about (and really made me interested in how to do things with Windows and Ansible).
And then, just as I wrap up, I noticed that when I’d clicked on to show the demo, it had hidden the webcam. Ah, oh well. Fortunately, as I mentioned, I’d pre-recorded my talk, the only thing I’ve “lost” is the questions, but as I wasn’t really sure on many of the answers I provided, I’m not desperately sad about it.
Fundamentally, all of the technical issues really stemmed from the fact my laptop wasn’t capable of rendering on the screen. If I’d solved that in advance, the rest of the issues could have been resolved when I wasn’t stressing about getting my presentation to work on an unfamiliar machine.
I’m very grateful to BSides Liverpool for giving me the opportunity to deliver my presentation, and the rest of the event (I’ll post about that later) was fab!
As previously mentioned, I use Ansible a lot inside Virtual machines orchestrated with Vagrant. Today’s brief tip is how to make Vagrant install the absolutely latest version of Ansible on Ubuntu boxes with Pip.
Here’s your Vagrantfile
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/focal64"
config.vm.provision "ansible_local", run: "always" do |ansible|
ansible.playbook = "setup.yml"
ansible.playbook_command = "sudo ansible-playbook"
ansible.install_mode = "pip"
ansible.pip_install_cmd = "(until sudo apt update ; do sleep 1 ; done && sudo apt install -y python3-pip && sudo rm -f /usr/bin/pip && sudo ln -s /usr/bin/pip3 /usr/bin/pip && sudo -H pip install --upgrade pip) 2>&1 | tee -a /var/log/vagrant-init"
end
end
“But, that pip_install_cmd block is huge”, I hear you cry!
Well, yes, but let’s split that out into a slightly more readable code block! (Yes, I’ve removed the “&&” for clarity sake – it just means “only execute the next command if this one worked”)
(
# Wait until we get the apt "package lock" released
until sudo apt update
do
# By sleeping for 1 second increments until it works
sleep 1
done
# Then install python3-pip
sudo apt install -y python3-pip
# Just in case python2-pip is installed, delete it
sudo rm -f /usr/bin/pip
# And symbolically link pip3 to pip
sudo ln -s /usr/bin/pip3 /usr/bin/pip
# And then do a pip self-upgrade
sudo -H pip install --upgrade pip
# And output this to the end of the file /var/log/vagrant-init, including any error messages
) 2>&1 | tee -a /var/log/vagrant-init
What does this actually do? Well, pip is the python package manager, so we’re asking for the latest packaged version to be installed (it often isn’t particularly with older releases of, well, frankly any Linux distribution) – this is the “pip_install_cmd” block. Then, once pip is installed, it’ll run “pip install ansible” – which will give it the latest version available to Pip, and then when that’s all done, it’ll run “sudo ansible-playbook /vagrant/setup.yml”
I’ve been using HashiCorp’s Vagrant with Oracle’s VirtualBox for several years (probably since 2013, if my blog posts are anything to go by), and I’ve always been pretty comfortable with how it works.
This said, when using a Windows machine running Microsoft’s Hyper-V (built into Windows since Windows 7/2018) VirtualBox is unable (by default) to run 64 bit virtual machines (thanks to Hyper-V “stealing” the VT-x/AMD-V bit from the BIOS/EFI).
Around last year or maybe even the year before, Microsoft introduced a “Hypervisior Platform” add-on, which lets VirtualBox run 64 bit machines on a Hyper-V host (more on this later). HOWEVER, it is much slower than in native mode, and can often freeze on booting…
Meanwhile, Vagrant, (a configuration file that acts as a wrapper around various hypervisors, using VirtualBox by default) boots machines in a “headless” mode by default, so you can’t see the freezing.
I’m trying to use an Ubuntu 18.04 virtual machine for various builds I’m creating, and found that I’d get a few issues on boot, so let’s get these sorted out.
VirtualBox can’t start 64bit virtual machines when Hyper-V is installed.
You need to confirm that certain Windows features are enabled, including “Hyper-V” and “Windows Hypervisor Platform”. Confirm you’re running at least Windows 10 version 1803 which is the first release with the “Windows Hypervisor Platform”.
GUI mode
Run winver to bring up this box. Confirm the version number is greater than 1803. Mine is 1909.
A screenshot of the “winver” command, highlighting the version number, which in this case shows 1909, but needs to show at least 1803.
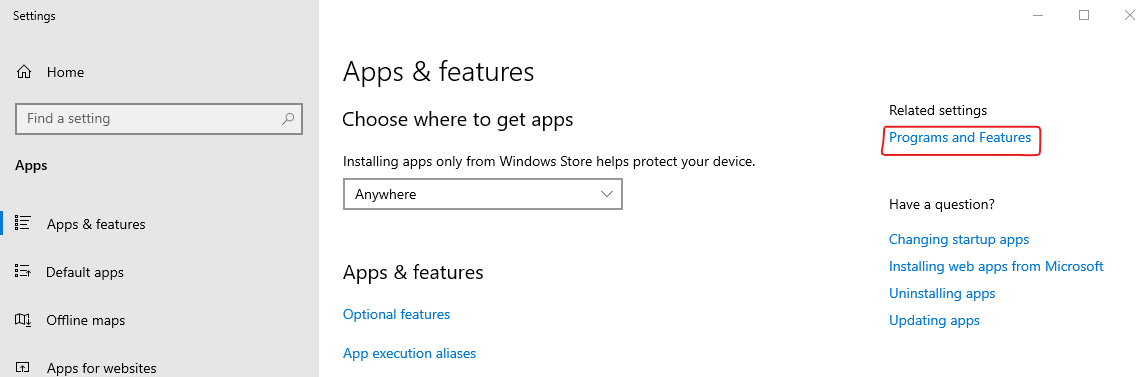
Right click on the start menu, and select “Apps and Features”. Click on “Programs and Features”.
The settings panel found by right clicking the “Start Menu” and selecting “Apps and Features”. Note the desired next step – “Programs and Features” is highlighted.
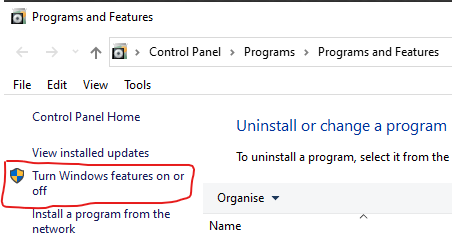
In the “Programs and Features” window, click on “Turn Windows Features on or off”. Note the shield icon here indicates that administrative access is required, and you may be required to authenticate to the machine to progress past this stage.
A fragment of the “Programs and Features” window, with the “Turn Windows features on or off” link highlighted.
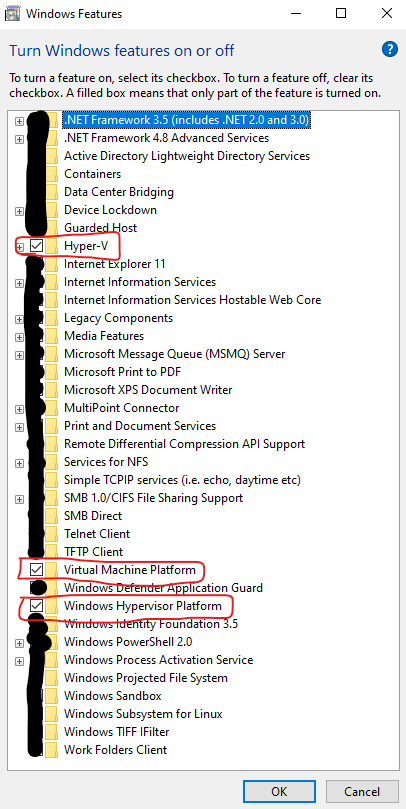
Next, ensure that the following “Windows Features” are enabled; “Hyper-V”, “Virtual Machine Platform” and “Windows Hypervisor Platform”. Click on “OK” to install these features, if they’re not already installed.
A screen capture of the “Turn Windows features on or off” dialogue box, with certain features obscured and others highlighted.
Note that once you’ve pressed “OK”, you’ll likely need to reboot your machine, if any of these features were not already installed.
CLI mode
Right click on the start menu, and start an Administrative Powershell session.
Run the command Get-ComputerInfo | select WindowsVersion. You should get a response which looks like this:
WindowsVersion
--------------
1909
Note that the version number needs to be greater than 1803.
Next, find the names of the features you need to install. These features have region specific names, so outside EN-GB, these names may not match your requirements!
Run the command Get-WindowsOptionalFeature -online | select FeatureName,State and you’re looking for the following lines (this has been cropped to just what you need):
FeatureName State
----------- -----
HypervisorPlatform Enabled
VirtualMachinePlatform Enabled
Microsoft-Hyper-V-All Enabled
If any of these three features are not enabled, run Enable-WindowsOptionalFeature -online -FeatureName x where “x” is the name of the feature, listed in the above text block, you want to install. For example: Enable-WindowsOptionalFeature -online -FeatureName HypervisorPlatform,VirtualMachinePlatform,Microsoft-Hyper-V-All. If you run this when they’re already enabled, it should return RestartNeeded : False, but otherwise you’re likely to need to reboot.
After the reboot
After you’ve rebooted, and you start a 64 bit virtual machine in VirtualBox, you’ll see this icon in the bottom corner.
A screen grab of the VirtualBox Status Bar, highlighting the “Slow Mode” icon representing the CPU
Booting the Virtual Machine with Vagrant fails because it takes too long to boot
This was historically a big issue with Vagrant and VirtualBox, particularly with Windows Vagrant boxes, but prior to the Hyper-V/VirtualBox solution, it’d been largely fixed (or at least, I wasn’t seeing it!) There is a “standard” timeout for booting a Virtual Machine, I think at approximately 5 minutes, but I might be wrong. To make this “issue” stop occurring, add this config.vm.boot_timeout = 0 line to your Vagrantfile, like this:
Vagrant.configure("2") do |config|
config.vm.boot_timeout = 0
end
This says to Vagrant, don’t worry how long it takes to boot, just keep waiting until it does. Yes, it will be slower, but it should get there in the end!
Booting the Virtual Maching with Vagrant does not fail, but it never authenticates with your Private Key.
Your VM may sit at this block for quite a while:
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 127.0.0.1:2222
default: SSH username: vagrant
default: SSH auth method: private key
If this occurs, you may find that your virtual machine has hung during the boot process… but weirdly, a simple work-around to this is to ensure that the VirtualBox GUI is open, and that you’ve got a block like this (config.vm.provider / vb.gui=true / end) in your Vagrantfile:
Vagrant.configure("2") do |config|
config.vm.provider "virtualbox" do |vb|
vb.gui = true
end
end
This forces VirtualBox to open a window with your Virtual Machine’s console on it (much like having a monitor attached to real hardware). You don’t need to interact with it, but any random hangs or halts on your virtual machine may be solved just by bringing this window, or the VirtualBox Machines GUI, to the foreground.
Sometimes you may see, when this happens, a coredump or section of kernel debugging code on the console. Don’t worry about this!
Vagrant refuses to SSH to your virtual machine when using the vagrant ssh command.
Provisioning works like a treat, and you can SSH into the virtual machine from any other environment, but, when you run vagrant ssh, you get an error about keys not being permitted or usable. This is fixable by adding a single line, either to your system or user -wide environment variables, or by adding a line to your Vagrantfile.
The environment variable is VAGRANT_PREFER_SYSTEM_BIN, and by setting this to 0, it will use bundled versions of ssh or rsync instead of using any versions provided by Windows.
You can add a line like this ENV['VAGRANT_PREFER_SYSTEM_BIN']="0" to your Vagrantfile, outside of the block Vagrant.configure…end, like this:
ENV['VAGRANT_PREFER_SYSTEM_BIN']="0"
Vagrant.configure("2") do |config|
end
A few posts ago I wrote about building Windows virtual machines with Terraform, and a couple of days ago, “YoureInHell” on Twitter reached out and asked what advice I’d give about having several different terraform modules use the same basic build of custom data.
They’re trying to avoid putting the same template file into several repos (I suspect so that one team can manage the “custom-data”, “user-data” or “cloud-init” files, and another can manage the deployment terraform files), and asked if I had any suggestions.
I had three ideas.
Using a New Module
This was my initial thought; create a new module called something like “Standard Build File”, and this build file contains just the following terraform file, and a template file called “build.tmpl”.
module "buildTemplate" {
source = "git::https://git.example.net/buildTemplate.git?ref=latestLive"
# See https://www.terraform.io/docs/language/modules/sources.html
# for more details on how to specify the source of this module
unsetVar = "Set To This String"
}
output "RenderedTemplate" {
value = module.buildTemplate.template
}
And that means that you can use the module.buildTemplate.template anywhere you’d normally specify your templateFile, and get a consistent, yet customizable template (and note, because I specified a particular tag, you can use that to move to the “current latest” or “the version we released into live on YYYY-MM-DD” by using a tag, or a commit ref.)
Now, the downside to this is that you’ve now got a whole separate module for creating your instances that needs to be maintained. What are our other options?
Git Submodules for your template
I use Git Submodules a LOT for my code. It’s a bit easy to get into a state with them, particularly if you’re not great at keeping on top of them, but… if you are OK with them, you’d create a repo, again, let’s use “https://git.example.net/buildTemplate.git” as our git repo, and put your template in there. In your terraform git repo, you’d run this command: git submodule add https://git.example.net/buildTemplate.git and this would add a directory to your repo called “buildTemplate” that you can use your templatefile function in Terraform against (like this: templatefile("buildTemplate/build.tmpl", {someVar="var"})).
Now, this means that you’ve effectively got two git repos in one tree, and if any changes occur in your submodule repo, you’d need to do git checkout main ; git pull to get the latest updates from your main branch, and when you check it out initially on another machine, you’ll need to do git clone https://git.example.net/terraform --recurse-submodules to get the submodules populated at the same time.
A benefit to this is that because it’s “inline” with the rest of your tree, if you need to make any changes to this template, it’s clearly where it’s supposed to be in your tree, you just need to remember about the submodule when it comes to making PRs and suchforth.
How about that third idea?
Keep it simple, stupid 😁
Why bother with submodules, or modules from a git repo? Terraform can be quite easy to over complicate… so why not create all your terraform files in something like this structure:
And then in each of your terraform files (web_servers, logic_servers and database_servers) just reference the file in your project root, like this: templatefile("../build.tmpl", {someVar="var"})
The downside to this is that you can’t as easily farm off the control of that build script to another team, and they’d be making (change|pull|merge) requests against the same repo as you… but then again, isn’t that the idea for functional teams? 😃
I have been playing again, recently, with Nebula, an Open Source Peer-to-Peer VPN product which boasts speed, simplicity and in-built firewalling. Although I only have a few nodes to play with (my VPS, my NAS, my home server and my laptop), I still wanted to simplify, for me, the process of onboarding devices. So, naturally, I spent a few evenings writing a bash script that helps me to automate the creation of my Nebula nodes.
Nebula Certificates
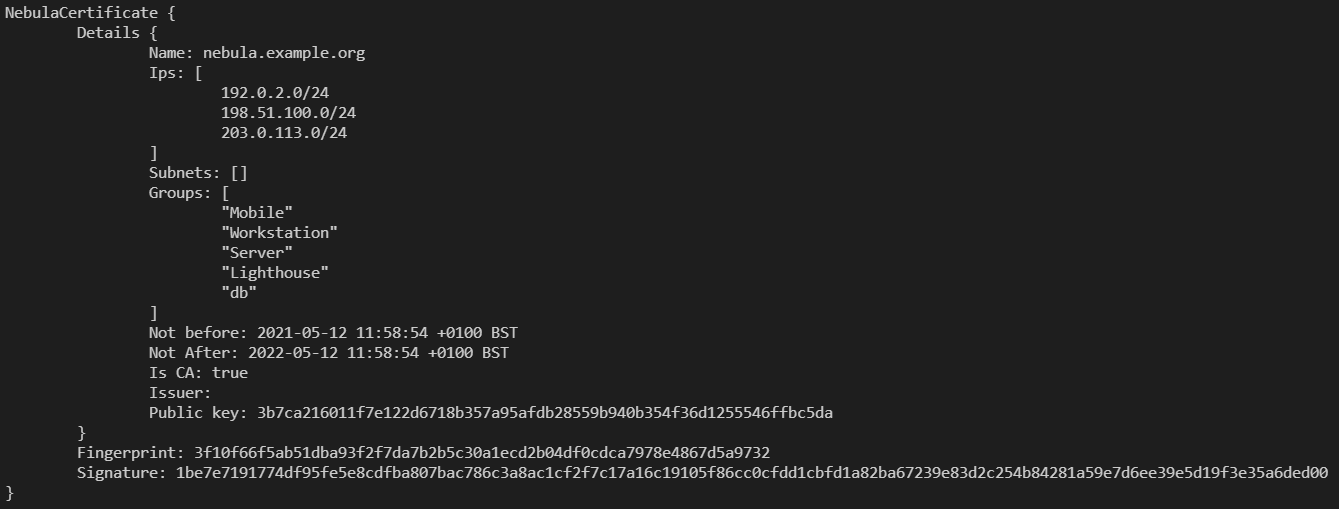
Nebula have implemented their own certificate structure. It’s similar to an x509 “TLS Certificate” (like you’d use to access an HTTPS website, or to establish an OpenVPN connection), but has a few custom fields.
The result of typing “nebula-cert print -path ca.crt” to print the custom fields
In this context, I’ve created a nebula Certificate Authority (CA), using this command:
nebula-cert ca -name nebula.example.org -ips 192.0.2.0/24,198.51.100.0/24,203.0.113.0/24 -groups Mobile,Workstation,Server,Lighthouse,db
So, what does this do?
Well, it creates the certificate and private key files, storing the name for the CA as “nebula.example.org” (there’s a reason for this!) and limiting the subnets and groups (like AWS or Azure Tags) the CA can issue certificates with.
Here, I’ve limited the CA to only issue IP addresses in the RFC5737 “Documentation” ranges, which are 192.0.2.0/24, 198.51.100.0/24 and 203.0.113.0/24, but this can easily be expanded to 10.0.0.0/8 or lots of individual subnets (I tested, and proved 1026 separate subnets which worked fine).
Groups, in Nebula parlance, are building blocks of the Security product, and can act like source or destination filters. In this case, I limited the CA to only being allowed to issue certificates with the groups of “Mobile”, “Workstation”, “Server”, “Lighthouse” and “db”.
As this certificate authority requires no internet access, and only enough access to read and write files, I have created my Nebula CA server on a separate Micro SD card to use with a Raspberry Pi device, and this is used only to generate a new CA certificate each 6 months (in theory, I’ve not done this part yet!), and to sign keys for all the client devices as they come on board.
I copy the ca.crt file to my target machines, and then move on to creating my client certificates
Client Certificates
When you generate key materials for Public Key Cryptographic activities (like this one), you’re supposed to generate the private key on the source device, and the private key should never leave the device on which it’s generated. Nebula allows you to do this, using the nebula-cert command again. That command looks like this:
If you notice, there’s a key difference at this point between Nebula’s key signing routine, and an x509 TLS style certificate, you see, this stage would be called a “Certificate Signing Request” or CSR in TLS parlance, and it usually would specify the record details for the certificate (normally things like “region”, “organisational unit”, “subject name” and so on) before sending it to the CA for signing (marking it as trusted).
In the Nebula world, you create a key, and send the public part of that (in this case, “host.pub” but it can have any name you like) to the CA, at which point the CA defines what IP addresses it will have, what groups it is in, and so on, so let’s do that.
Let’s pick apart these options, shall we? The first four flags “-ca-crt“, “-ca-key“, “-in-pub” and “-out-crt” all refer to the CSR process – it’s reading the CA certificate and key, as well as the public part of the keypair created for the process, and then defines what the output certificate will be called. The next switch, -groups, identifies the tags we’re assigning to this node, then (the mandatory flag) -ip sets the IP address allocated to the node. Note that the certificate is using one of the valid group names, and has been allocated a valid IP address address in the ranges defined above. If you provide a value for the certificate which isn’t valid, you’ll get a warning message.
nebula-cert issues a warning when signing a certificate that tries to specify a value outside the constraints of the CA
In the above screenshot, I’ve bypassed the key generation and asked for the CA to sign with values which don’t match the constraints.
The last part is the name of the certificate. This is relevant because Nebula has a DNS service which can resolve the Nebula IPs to the hostnames assigned on the Certificates.
Anyway… Now that we know how to generate certificates the “hard” way, let’s make life a bit easier for you. I wrote a little script – Nebula Cert Maker, also known as certmaker.sh.
certmaker.sh
So, what does certmaker.sh do that is special?
It auto-assigns an IP address, based on the MD5SUM of the FQDN of the node. It uses (by default) the first CIDR mask (the IP range, written as something like 192.0.2.0/24) specified in the CA certificate. If multiple CIDR masks are specified in the certificate, there’s a flag you can use to select which one to use. You can override this to get a specific increment from the network address.
It takes the provided name (perhaps webserver) and adds, as a suffix, the name of the CA Certificate (like nebula.example.org) to the short name, to make the FQDN. This means that you don’t need to run a DNS service for support staff to access machines (perhaps you’ll have webserver1.nebula.example.org and webserver2.nebula.example.org as well as database.nebula.example.org).
Three “standard” roles have been defined for groups, these are “Server”, “Workstation” and “Lighthouse” [1] (the latter because you can configure Lighthouses to be the DNS servers mentioned in step 2.) Additional groups can also be specified on the command line.
[1] A lighthouse, in Nebula terms, is a publically accessible node, either with a static IP, or a DNS name which resolves to a known host, that can help other nodes find each other. Because all the nodes connect to it (or a couple of “it”s) this is a prime place to run the DNS server, as, well, it knows where all the nodes are!
So, given these three benefits, let’s see these in a script. This script is (at least currently) at the end of the README file in that repo.
# Create the CA
mkdir -p /tmp/nebula_ca
nebula-cert ca -out-crt /tmp/nebula_ca/ca.crt -out-key /tmp/nebula_ca/ca.key -ips 192.0.2.0/24,198.51.100.0/24 -name nebula.example.org
# First lighthouse, lighthouse1.nebula.example.org - 192.0.2.1, group "Lighthouse"
./certmaker.sh --cert_path /tmp/nebula_ca --name lighthouse1 --ip 1 --lighthouse
# Second lighthouse, lighthouse2.nebula.example.org - 192.0.2.2, group "Lighthouse"
./certmaker.sh -c /tmp/nebula_ca -n lighthouse2 -i 2 -l
# First webserver, webserver1.nebula.example.org - 192.0.2.168, groups "Server" and "web"
./certmaker.sh --cert_path /tmp/nebula_ca --name webserver1 --server --group web
# Second webserver, webserver2.nebula.example.org - 192.0.2.191, groups "Server" and "web"
./certmaker.sh -c /tmp/nebula_ca -n webserver2 -s -g web
# Database Server, db.nebula.example.org - 192.0.2.182, groups "Server" and "db"
./certmaker.sh --cert_path /tmp/nebula_ca --name db --server --group db
# First workstation, admin1.nebula.example.org - 198.51.100.205, group "Workstation"
./certmaker.sh --cert_path /tmp/nebula_ca --index 1 --name admin1 --workstation
# Second workstation, admin2.nebula.example.org - 198.51.100.77, group "Workstation"
./certmaker.sh -c /tmp/nebula_ca -d 1 -n admin2 -w
# First Mobile device - Create the private/public key pairing first
nebula-cert keygen -out-key mobile1.key -out-pub mobile1.pub
# Then sign it, mobile1.nebula.example.org - 198.51.100.217, group "mobile"
./certmaker.sh --cert_path /tmp/nebula_ca --index 1 --name mobile1 --group mobile --public mobile1.pub
# Second Mobile device - Create the private/public key pairing first
nebula-cert keygen -out-key mobile2.key -out-pub mobile2.pub
# Then sign it, mobile2.nebula.example.org - 198.51.100.22, group "mobile"
./certmaker.sh -c /tmp/nebula_ca -d 1 -n mobile2 -g mobile -p mobile2.pub
Technically, the mobile devices are simulating the local creation of the private key, and the sharing of the public part of that key. It also simulates what might happen in a more controlled environment – not where everything is run locally.
So, let’s pick out some spots where this content might be confusing. I’ve run each type of invocation twice, once with the short version of all the flags (e.g. -c instead of --cert_path, -n instead of --name) and so on, and one with the longer versions. Before each ./certmaker.sh command, I’ve added a comment, showing what the hostname would be, the IP address, and the Nebula Groups assigned to that node.
It is also possible to override the FQDN with your own FQDN, but this command option isn’t in here. Also, if the CA doesn’t provide a CIDR mask, one will be selected for you (10.44.88.0/24), or you can provide one with the -b/--subnet flag.
If the CA has multiple names (e.g. nebula.example.org and nebula.example.com), then the name for the host certificates will be host.nebula.example.org and also host.nebula.example.com.
Using Bash
So, if you’ve looked at, well, almost anything on my site, you’ll see that I like to use tools like Ansible and Terraform to deploy things, but for something which is going to be run on this machine, I’d like to keep things as simple as possible… and there’s not much in this script that needed more than what Bash offers us.
For those who don’t know, bash is the default shell for most modern Linux distributions and Docker containers. It can perform regular expression parsing (checking that strings, or specific collections of characters appear in a variable), mathematics, and perform extensive loop and checks on values.
So, take a look at the internals of the script, if you want to know some options on writing bash scripts that manipulate IP addresses and read the output of files!
If you’re looking for some simple tasks to start your portfolio of work, there are some “good first issue” tasks in the “issues” of the repo, and I’d be glad to help you work through them.
Wrap up
I hope you enjoy using this script, and I hope, if you’re planning on writing some bash scripts any time soon, that you take a look over the code and consider using some of the templates I reference.
I tend to write long and overly complicated set_fact statements in Ansible, ALL THE DAMN TIME. I write stuff like this:
rulebase: |
{
{% for var in vars | dict2items %}
{% if var.key | regex_search(regex_rulebase_match) | type_debug != "NoneType"
and (
var.value | type_debug == "dict"
or var.value | type_debug == "AnsibleMapping"
) %}
{% for item in var.value | dict2items %}
{% if item.key | regex_search(regex_rulebase_match) | type_debug != "NoneType"
and (
item.value | type_debug == "dict"
or item.value | type_debug == "AnsibleMapping"
) %}
"{{ var.key | regex_replace(regex_rulebase_match, '\2') }}{{ item.key | regex_replace(regex_rulebase_match, '\2') }}": {
{# This block is used for rulegroup level options #}
{% for key in ['log_from_start', 'log', 'status', 'nat', 'natpool', 'schedule', 'ips_enable', 'ssl_ssh_profile', 'ips_sensor'] %}
{% if var.value[key] is defined and rule.value[key] is not defined %}
{% if var.value[key] | type_debug in ['string', 'AnsibleUnicode'] %}
"{{ key }}": "{{ var.value[key] }}",
{% else %}
"{{ key }}": {{ var.value[key] }},
{% endif %}
{% endif %}
{% endfor %}
{% for rule in item.value | dict2items %}
{% if rule.key in ['sources', 'destinations', 'services', 'src_internet_service', 'dst_internet_service'] and rule.value | type_debug not in ['list', 'AnsibleSequence'] %}
"{{ rule.key }}": ["{{ rule.value }}"],
{% elif rule.value | type_debug in ['string', 'AnsibleUnicode'] %}
"{{ rule.key }}": "{{ rule.value }}",
{% else %}
"{{ rule.key }}": {{ rule.value }},
{% endif %}
{% endfor %}
},
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
}
Now, if you’re writing set_fact or vars like this a lot, what you tend to end up with is the dreaded dict2items requires a dictionary, got instead. which basically means “Hah! You wrote a giant blob of what you thought was JSON, but didn’t render right, so we cast it to a string for you!”
The way I usually write my playbooks, I’ll do something with this set_fact at line, let’s say, 10, and then use it at line, let’s say, 500… So, I don’t know what the bloomin’ thing looks like then!
- name: Type Check - is_a_string
assert:
quiet: yes
that:
- vars[this_key] is not boolean
- vars[this_key] is not number
- vars[this_key] | int | string != vars[this_key] | string
- vars[this_key] | float | string != vars[this_key] | string
- vars[this_key] is string
- vars[this_key] is not mapping
- vars[this_key] is iterable
success_msg: "{{ this_key }} is a string"
fail_msg: |-
{{ this_key }} should be a string, and is instead
{%- if vars[this_key] is not defined %} undefined
{%- else %} {{ vars[this_key] is boolean | ternary(
'a boolean',
(vars[this_key] | int | string == vars[this_key] | string) | ternary(
'an integer',
(vars[this_key] | float | string == vars[this_key] | string) | ternary(
'a float',
vars[this_key] is string | ternary(
'a string',
vars[this_key] is mapping | ternary(
'a dict',
vars[this_key] is iterable | ternary(
'a list',
'unknown (' ~ vars[this_key] | type_debug ~ ')'
)
)
)
)
)
)}}{% endif %} - {{ vars[this_key] | default('unset') }}
I hope this helps you, bold traveller with complex jinja2 templating requirements!
(Oh, and if you get “template error while templating string: no test named 'boolean'“, you’re probably running Ansible which you installed using apt from Ubuntu Universe, version 2.9.6+dfsg-1 [or, at least I was!] – to fix this, use pip to install a more recent version – preferably using virtualenv first!)