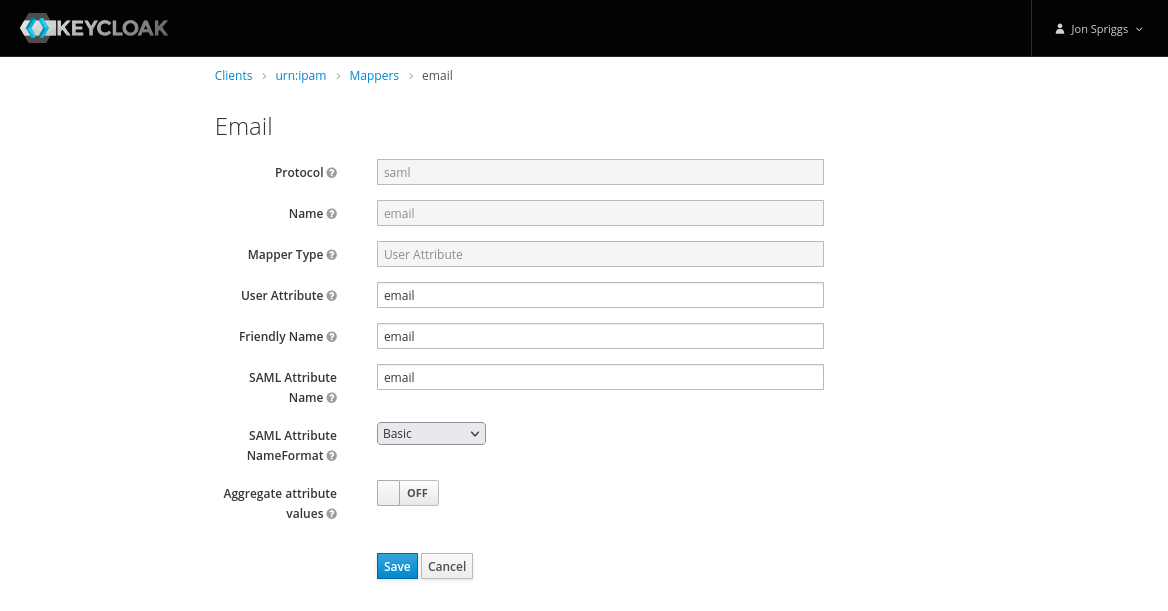
Tale as old as time, the compute instance type you want to use in AWS is highly contested (or worse yet, not as available in every availability zone in your region)! You plead with your TAM or AM “Please let us have more of that instance type” only to be told “well, we can put in a request, but… haven’t you thought about using a range of instance types”?
And yes, I’ve been on both sides of that conversation, sadly.
The commented terraform
# This is your legacy instance_type variable. Ideally we'd have
# a warning we could raise at this point, telling you not to use
# this variable, but... it's not ready yet.
variable "instance_type" {
description = "The legacy single-instance size, e.g. t3.nano. Please migrate to instance_types ASAP. If you specify instance_types, this value will be ignored."
type = string
default = null
}
# This is your new instance_types value. If you don't already have
# some sort of legacy use of the instance_type variable, then don't
# bother with that variable or the locals block below!
variable "instance_types" {
description = "A list of instance sizes, e.g. [t2.nano, t3.nano] and so on."
type = list(string)
default = null
}
# Use only this locals block (and the value further down) if you
# have some legacy autoscaling groups which might use individual
# instance_type sizes.
locals {
# This means if var.instance_types is not defined, then use it,
# otherwise create a new list with the single instance_type
# value in it!
instance_types = var.instance_types != null ? var.instance_types : [ var.instance_type ]
}
resource "aws_launch_template" "this" {
# The prefix for the launch template name
# default "my_autoscaling_group"
name_prefix = var.name
# The AMI to use. Calculated outside this process.
image_id = data.aws_ami.this.id
# This block ensures that any new instances are created
# before deleting old ones.
lifecycle {
create_before_destroy = true
}
# This block defines the disk size of the root disk in GB
block_device_mappings {
device_name = data.aws_ami.centos.root_device_name
ebs {
volume_size = var.disksize # default "10"
volume_type = var.disktype # default "gp2"
}
}
# Security Groups to assign to the instance. Alternatively
# create a network_interfaces{} block with your
# security_groups = [ var.security_group ] in it.
vpc_security_group_ids = [ var.security_group ]
# Any on-boot customizations to make.
user_data = var.userdata
}
resource "aws_autoscaling_group" "this" {
# The name of the Autoscaling Group in the Web UI
# default "my_autoscaling_group"
name = var.name
# The list of subnets into which the ASG should be deployed.
vpc_zone_identifier = var.private_subnets
# The smallest and largest number of instances the ASG should scale between
min_size = var.min_rep
max_size = var.max_rep
mixed_instances_policy {
launch_template {
# Use this template to launch all the instances
launch_template_specification {
launch_template_id = aws_launch_template.this.id
version = "$Latest"
}
# This loop can either use the calculated value "local.instance_types"
# or, if you have no legacy use of this module, remove the locals{}
# and the variable "instance_type" {} block above, and replace the
# for_each and instance_type values (defined as "local.instance_types")
# with "var.instance_types".
#
# Loop through the whole list of instance types and create a
# set of "override" values (the values are defined in the content{}
# block).
dynamic "override" {
for_each = local.instance_types
content {
instance_type = local.instance_types[override.key]
}
}
}
instances_distribution {
# If we "enable spot", then make it 100% spot.
on_demand_percentage_above_base_capacity = var.enable_spot ? 0 : 100
spot_allocation_strategy = var.spot_allocation_strategy
spot_max_price = "" # Empty string is "on-demand price"
}
}
}So what is all this then?
This is two Terraform resources; an aws_launch_template and an aws_autoscaling_group. These two resources define what should be launched by the autoscaling group, and then the settings for the autoscaling group.
You will need to work out what instance types you want to use (e.g. “must have 16 cores and 32 GB RAM, have an x86_64 architecture and allow up to 15 Gigabit/second throughput”)
When might you use this pattern?
If you have been seeing messages like “There is no Spot capacity available that matches your request.” or “We currently do not have sufficient <size> capacity in the Availability Zone you requested.” then you need to consider diversifying the fleet that you’re requesting for your autoscaling group. To do that, you need to specify more instance types. To achieve this, I’d use the above code to replace (something like) one of the code samples below.
If you previously have had something like this:
resource "aws_launch_configuration" "this" {
iam_instance_profile = var.instance_profile_name
image_id = data.aws_ami.this.id
instance_type = var.instance_type
name_prefix = var.name
security_groups = [ var.security_group ]
user_data_base64 = var.userdata
spot_price = var.spot_price
root_block_device {
volume_size = var.disksize
}
lifecycle {
create_before_destroy = true
}
}
resource "aws_autoscaling_group" "this" {
capacity_rebalance = false
launch_configuration = aws_launch_configuration.this.id
max_size = var.max_rep
min_size = var.min_rep
name = var.name
vpc_zone_identifier = var.private_subnets
}Or this:
resource "aws_launch_template" "this" {
lifecycle {
create_before_destroy = true
}
block_device_mappings {
device_name = data.aws_ami.this.root_device_name
ebs {
volume_size = var.disksize
}
}
iam_instance_profile {
name = var.instance_profile_name
}
network_interfaces {
associate_public_ip_address = true
security_groups = local.node_security_groups
}
image_id = data.aws_ami.this.id
name_prefix = var.name
instance_type = var.instance_type
user_data = var.userdata
instance_market_options {
market_type = "spot"
spot_options {
spot_instance_type = "one-time"
}
}
metadata_options {
http_tokens = var.imds == 1 ? "optional" : "required"
http_endpoint = "enabled"
http_put_response_hop_limit = 1
}
}
resource "aws_autoscaling_group" "this" {
name = var.name
vpc_zone_identifier = var.private_subnets
min_size = var.min_rep
max_size = var.max_rep
launch_template {
id = aws_launch_template.this.id
version = "$Latest"
}
}Then this new method is a much better idea :) Even more so if you had two launch templates to support spot and non-spot instance types!
Hat-tip to former colleague Paul Moran who opened my eyes to defining your fleet of variable instance types, as well as to my former customer (deliberately unnamed) and my current employer who both stumbled into the same documentation issue. Without Paul’s advice with my prior customer’s issue I’d never have known what I was looking for this time around!
Featured image is “Fishing fleet” by “Nomad Tales” on Flickr and is released under a CC-BY-SA license.