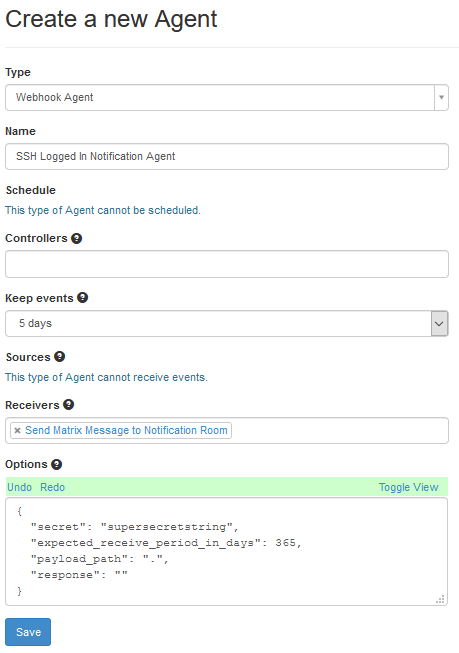
Hi! Long time, no see!
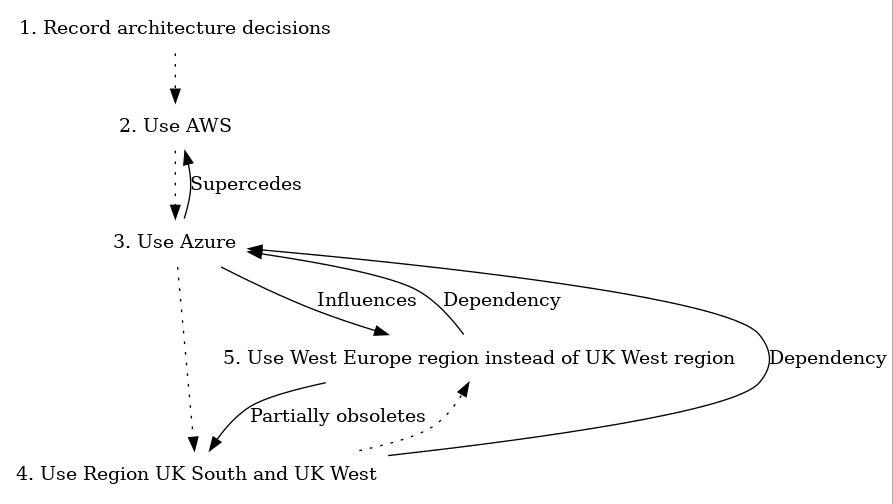
I’ve been working on my Decision Records open source project for a few months now, and I’ve finally settled on the cross-platform language Rust to create my script. As a result, I’ve got a build process which lets me build for Windows, Mac OS and Linux. I’m currently building a single, unsigned binary for each platform, and I wanted to make it so that Github Actions would build and release these three files for me. Most of the guidance which is currently out there points to some unmaintained actions, originally released by GitHub… but now they point to a 3rd party “release” action as their recommended alternative, so I thought I’d explain how I’m using it to release on several platforms at once.
Although I can go into detail about the release file I’m using for Rust-Decision-Records, I’m instead going to provide a much more simplistic view, based on my (finally working) initial test run.
GitHub Actions
GitHub have a built-in Continuous Integration, Continuous Deployment/Delivery (CI/CD) system, called GitHub Actions. You can have several activities it performs, and these are executed by way of instructions in .github/workflows/<somefile>.yml. I’ll be using .github/workflows/build.yml in this example. If you have multiple GitHub Action files you wanted to invoke (perhaps around issue management, unit testing and so on), these can be stored in separate .yml files.
The build.yml actions file will perform several tasks, separated out into two separate activities, a “Create Release” stage, and a “Build Release” stage. The Build stage will use a “Matrix” to execute builds on the three platforms at the same time – Linux AMD64, Windows and Mac OS.
The actual build steps? In this case, it’ll just be writing a single-line text file, stating the release it’s using.
So, let’s get started.
Create Release
A GitHub Release is typically linked to a specific “tagged” commit. To trigger the release feature, every time a commit is tagged with a string starting “v” (like v1.0.0), this will trigger the release process. So, let’s add those lines to the top of the file:
name: Create Release
on:
push:
tags:
- 'v*'You could just as easily use the filter pattern ‘v[0-9]+.[0-9]+.[0-9]+’ if you wanted to use proper Semantic Versioning, but this is a simple demo, right? 😉
Next we need the actual action we want to start with. This is at the same level as the “on” and “name” tags in that YML file, like this:
jobs:
create_release:
name: Create Release
runs-on: ubuntu-latest
steps:
- name: Create Release
id: create_release
uses: softprops/action-gh-release@v1
with:
name: ${{ github.ref_name }}
draft: false
prerelease: false
generate_release_notes: falseSo, this is the actual “create release” job. I don’t think it matters what OS it runs on, but ubuntu-latest is the one I’ve seen used most often.
In this, you instruct it to create a simple release, using the text in the annotated tag you pushed as the release notes.
This is using a third-party release action, softprops/action-gh-release, which has not been vetted by me, but is explicitly linked from GitHub’s own action.
If you check the release at this point, (that is, without any other code working) you’d get just the source code as a zip and a .tgz file. BUT WE WANT MORE! So let’s build this mutha!
Build Release
Like with the create_release job, we have a few fields of instructions before we get to the actual actions it’ll take. Let’s have a look at them first. These instructions are at the same level as the jobs:\n create_release: line in the previous block, and I’ll have the entire file listed below.
build_release:
name: Build Release
needs: create_release
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
include:
- os: ubuntu-latest
release_suffix: ubuntu
- os: macos-latest
release_suffix: mac
- os: windows-latest
release_suffix: windows
runs-on: ${{ matrix.os }}So this section gives this job an ID (build_release) and a name (Build Release), so far, so exactly the same as the previous block. Next we say “You need to have finished the previous action (create_release) before proceeding” with the needs: create_release line.
But the real sting here is the strategy:\n matrix: block. This says “run these activities with several runners” (in this case, an unspecified Ubuntu, Mac OS and Windows release (each just “latest”). The include block asks the runners to add some template variables to the tasks we’re about to run – specifically release_suffix.
The last line in this snippet asks the runner to interpret the templated value matrix.os as the OS to use for this run.
Let’s move on to the build steps.
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Run Linux Build
if: matrix.os == 'ubuntu-latest'
run: echo "Ubuntu Latest" > release_ubuntu
- name: Run Mac Build
if: matrix.os == 'macos-latest'
run: echo "MacOS Latest" > release_mac
- name: Run Windows Build
if: matrix.os == 'windows-latest'
run: echo "Windows Latest" > release_windowsThis checks out the source code on each runner, and then has a conditional build statement, based on the OS you’re using for each runner.
It should be fairly simple to see how you could build this out to be much more complex.
The final step in the matrix activity is to add the “built” file to the release. For this we use the softprops release action again.
- name: Release
uses: softprops/action-gh-release@v1
with:
tag_name: ${{ needs.create_release.outputs.tag-name }}
files: release_${{ matrix.release_suffix }}The finished file
So how does this all look when it’s done, this most simple CI/CD build script?
name: Create Release
on:
push:
tags:
- 'v*'
jobs:
create_release:
name: Create Release
runs-on: ubuntu-latest
steps:
- name: Create Release
id: create_release
uses: softprops/action-gh-release@v1
with:
name: ${{ github.ref_name }}
draft: false
prerelease: false
generate_release_notes: false
build_release:
name: Build Release
needs: create_release
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
include:
- os: ubuntu-latest
release_suffix: ubuntu
- os: macos-latest
release_suffix: mac
- os: windows-latest
release_suffix: windows
runs-on: ${{ matrix.os }}
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Run Linux Build
if: matrix.os == 'ubuntu-latest'
run: echo "Ubuntu Latest" > release_ubuntu
- name: Run Mac Build
if: matrix.os == 'macos-latest'
run: echo "MacOS Latest" > release_mac
- name: Run Windows Build
if: matrix.os == 'windows-latest'
run: echo "Windows Latest" > release_windows
- name: Release
uses: softprops/action-gh-release@v1
with:
tag_name: ${{ needs.create_release.outputs.tag-name }}
files: release_${{ matrix.release_suffix }}I hope this helps you!
My Sources and Inspirations
- https://github.com/actions/create-release/issues/14
- https://dev.to/eugenebabichenko/automated-multi-platform-releases-with-github-actions-1abg
- https://ncorti.com/blog/howto-github-actions-build-matrix
Featured image is “Catch and Release” by “Trish Hamme” on Flickr and is released under a CC-BY license.