Couch to 5k is a training plan for jogging or running, where you start from doing very little jogging and move up to doing longer and longer extended runs. In the UK the BBC have an app which helps you follow the plan, but outside the UK there are other apps you can try.
Why did I start?
With the exception of the beginning of lockdown (where we were doing “big walks” to “keep our fitness up”), I found myself becoming progressively more and more sedentary. Yes, I’d still take the kids out each day, but I was finding myself more and more stuck in doing the same short walks that they were happy to do. I needed to push myself a bit. I’ve never been a runner, in fact many of my worst memories of secondary school involved being sent out for a run, or doing laps around the field… but Jules suggested I try Couch to 5k.
What am I using?
I’ve been using the BBC One You Couch to 5k app.
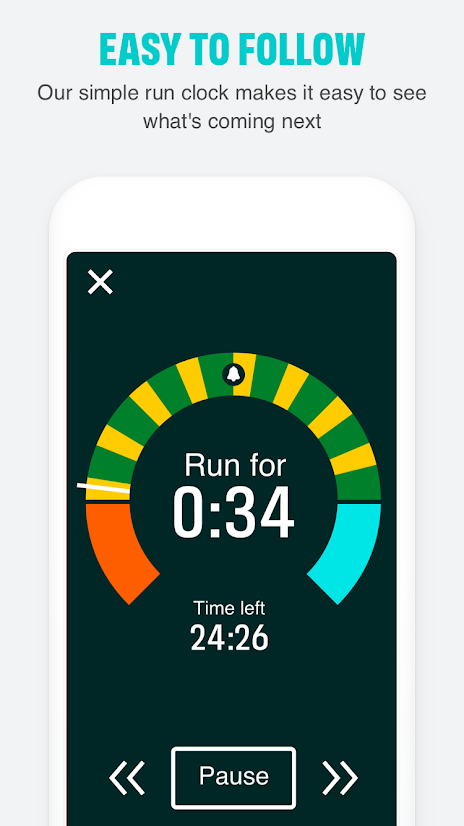
Following the plan
The first week, I was out, three times, shuffling along for 19 minutes, doing cycles of “jogging” for 60 seconds and then walking for 90 seconds. I felt like I couldn’t possibly jog for 60 seconds, but just keep going as best as I could. More often than not in the first couple of sessions I’d only be able to jog the full 60 seconds, but instead I’d do 30 to 45 seconds. And then session three came along, and I managed the full 60 seconds of the jog, each time! Wow!
The next week was a little bit harder, it’s still three sessions a week, but now it’s 5 cycles of jogging 90 seconds and walking for 2 minutes. Again I had the same pattern, the first session I couldn’t jog the full 90 seconds, but I could usually do 60 seconds, and sometimes I’d make it up to 75… and again, by the third session, I was managing the full 90 seconds for each of the cycles. I still wasn’t feeling like I could do any serious distance or speed, but at least I was going out consistently.
Week three got a bit harder. The three sessions this week all followed this cycle – 90 seconds jogging, 90 seconds walking, 3 minutes jogging, 3 minutes walking, 90 seconds jogging, 90 seconds walking, then 3 minutes jogging. Oof. The first time I did this I don’t think I even made the 90 seconds out of the 3 minutes jogging, but again, by the third session, I had this one sorted!
Week four changed the dynamic a bit. In this week you jog more than you walk. Yes, it sounds hard, but… well, as the app’s voice in my ear, Jo Whiley, says “You’ve done all the preparation for this, you can do it”. I’ll talk about the “Coaches” and the app itself in a bit. This week you do 3 minutes jogging, 90 seconds walking, 5 minutes jogging, 2.5 minutes walking, 3 minutes jogging, 90 seconds walking and then 5 minutes jogging. I followed a fairly standard (for me) pattern in this – I ended up not being able to do all of the running on each jog for the first two sessions, but on the third, I could manage it.
Week five was where I struggled the most. A combination of bad weather and, well, a global pandemic meant that I ended up doing this week twice. I quite like the fact that you can re-do individual sessions, or whole weeks of the Couch to 5k app. Anyway, the actual cycles this week are different from each session. It seems a bit hard but on the second time around I managed OK.
So, week 5 session one is 5 minutes jogging, 3 minutes walking, 5 minutes jogging, 3 minutes walking and then a final 5 minutes jogging. First time around I did OK with this – I think I managed 5 minutes jogging, then 3 minutes jogging and then 3 minutes jogging. Second time around I did 5 minutes, 4.5 minutes and 5 minutes.
Week 5 session two is 8 minutes jogging, 5 minutes walking and 8 minutes jogging. Oof. I think on my first pass at this I managed 5 minutes and then 2 minutes on the first block and then 6 minutes and walked the rest of the second block. On my second pass of this week I got both sets of 8 minutes, but I was exhausted. It was all good stuff.
And then the real killer. Week 5 session three is 20 minutes “non-stop” jogging. So, I’m going to remind you. It took me two goes at this week to manage this. The first time around I essentially managed 5 minute blocks, did what I could for each of those and then walked for anywhere from 30 seconds to 1 minute between each of them. Not great. Not what the plan said, but… I could re-do it. On the second run through I think I managed 12 minutes and then walked for 30 seconds, and then jogged for the rest of it. Whoop whoop.
Week 6 also had different timings for each of the sessions. This and Week 7 were also a bit of a muddle for me. I was away from my house from the end of week 6, all of week 7 and I was on my main summer holiday break. My children were both interested in coming out for a run with me, so I ended up doing the following sessions over the 9 days we were away (and the couple of days each side of it)!
- Week 6 session 1 (just me) 5 minutes jogging, 3 minutes walking, 8 minutes jogging, 3 minutes walking and 5 minutes jogging. At home. All generally OK. I don’t recall any issues with this one, but I clearly did have an issue, as I repeated it later in the week
- Week 6 session 2 (just me) 10 minutes jogging, 3 minutes walking then 10 minutes jogging. At home. Again, generally fine.
- Week 6 session 1 (just me) repeated for some reason! At home.
- Week 6 session 3 (just me) 25 minutes along the Abergele sea wall. All OK.
- Week 7 session 1 (me and Daniel) 25 minutes along the Abergele sea wall. Daniel struggles a bit with pace, so he’d rush off, then stop, then rush off, then stop. We did it OK though.
- Week 1 session 1 (me and Emily) (60 seconds jogging, 90 seconds walking, cycled 7 times) Good, and better paced too. Emily said she didn’t want to do it again 😁
- Week 2 session 1 (me and Daniel) (90 seconds jogging, 90 seconds walking, cycled 5 times) OK. Still no better paced, but Daniel also said he didn’t want to do it again.
- Week 7 session 2 (just me) 25 minutes at home. Felt amazing.
- Week 7 session 3 (just me) 25 minutes at home. Felt like I’d nailed this distance.
Back home from that break, I got back into it! I did week 8 session 1 last night, it’s now up to 28 minutes and I feel like I managed it with no worries at all.
Apps and accessories
That first week, I hadn’t known what to do with my phone – the first session I was wearing jogging bottoms and had the phone in my pocket – ugh, that was uncomfortable. The next time I had a small bag that went over my shoulder, but it kept rising up and catching me on the throat – that also didn’t work. I tried a small backpack and the phone just kept bouncing around in there and felt really uncomfortable and painful.
In the end I bought a “VGuard Running Phone Armband” from Amazon.

I measured my upper arm, and thought it would be tight, but would fit. In the end, I’ve actually started wearing it on my forearm, as I can actually see the display there, and because it’s not quite so tight. I wear wired headphones from my Nokia 6.2 phone which pass under a flap on the side of the case and then goes up my sleeve. I’m thinking of getting some bond conducting bluetooth headphones, as none of the over-the-ear or in-the-ear ones I’ve worn are really suitable for how I jog. Aside from anything I cross a couple of roads when I’m jogging, and while I can do this by vision alone, having an audio cue too would be helpful.
On my other wrist, I wear a Fossil Gen 4 Android Wear based watch.

I use this to signal to Google Fit when I start and stop the couch to 5k session, so I can get more accurate tracking of my activities. I upgraded to this during week 6 from my LG Urbane watch, and the new model has in-built heart rate tracking. As such, I get an idea of my heart rate during my jogs now too.
How about the app itself? On the whole, it’s OK. You do a 5 minute “brisk walk” to warm up and another to warm down at the end. Half way around the course, there’s a bell sound, so you know when you’re half way. You get a set of yellow circles showing what stages you’ve completed, and you’re reminded not to do the later stages without having done the earlier ones. Apparently, in the App there are also
There’s a few different coach voices to select from – I chose Jo Whiley, but there are also a few others, most of which I didn’t recognise, except for the comedienne Sarah Millican.
I had some niggles, but they’re not disastrous, for example, around week 2 I had a few sessions where the app would restart itself during the final block of speech, and so it didn’t record that run as having been completed (to resolve this, once I got home, I just put the phone on the side, set it to “running” and then pressed “end” once the timed session was done). On another occasion, the bell sounded, and it re-started the podcast which had been paused for my coach to talk to me about how far I’d gone. Not a disaster, again, as I just paused the podcast again, but a little frustrating!
Talking of the coaches and niggles, one of the later weeks, perhaps 5 or 6, the app indicated that it had failed to download my preferred voice for that week, and asked me to change coach. I picked Sarah Millican, and it was clear that Jo Whiley is much more my style of coach. Jo spends much of her time with you on the course telling you how she found getting started with running, or making suggestions about things to distract you while you’re running. Sarah was very matter-of-fact “You’ve done 5 minutes, well done”, and so on. A few people have remarked that some of the coaches are “too chatty” – Jo probably falls into that category, but I found it just enough distraction to keep me going. Sarah did not work for me! I swapped back to Jo when I got back to reliable Wifi and it downloaded fine! Whew.
I don’t think the app stores any data “in the cloud”, so I don’t think it’s possible to swap over to another phone – I think you’d just need to jump ahead to where you got to, and maybe afterwards go back and let it play through the track for each session to catch up.
In summary
If I was starting again, would I do “Couch to 5k”? Yes, absolutely. Have I encouraged others? Yep. Oh, and am I anywhere near 5k? No, not a shot! I’m currently doing about 2.3miles, which is a little over 3.5k. At 30 minutes, I’ll probably be doing about 2.5miles, which is about 4k, so to get to 3.1miles (which is around 5k), I’ll probably need to be running for maybe 40 minutes? Something like that. Anyway, I’m looking forward to getting close to that! And then, maybe, just maybe, I’ll start looking at doing 10k? Who knows!
Featured image is “jogger” by “Acid Pix” on Flickr and is released under a CC-BY license.