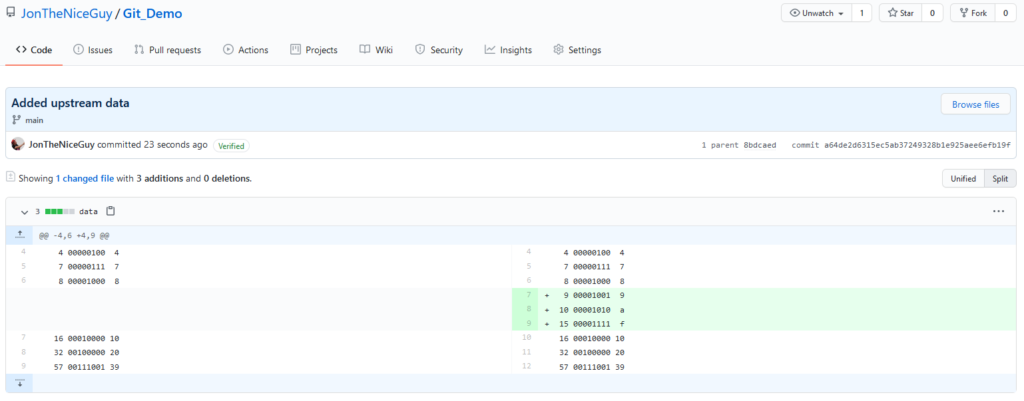
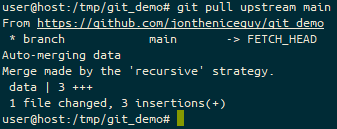
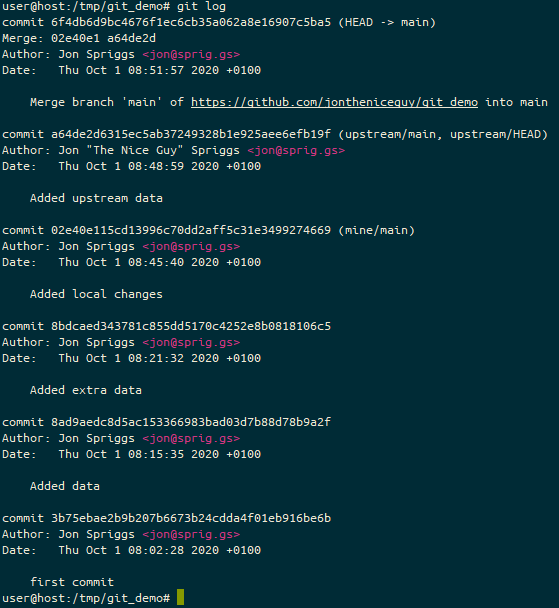
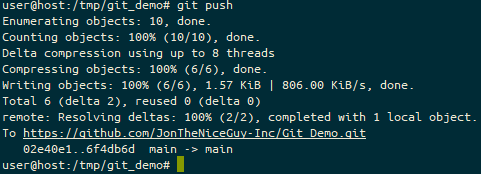
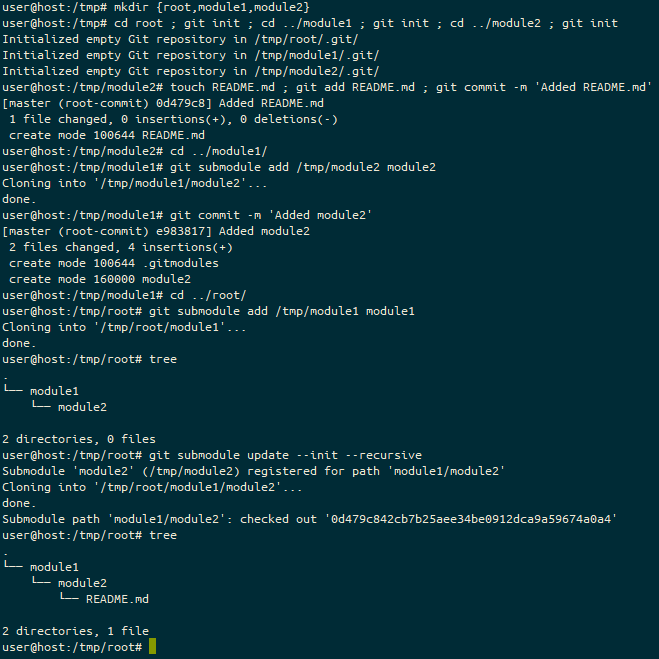
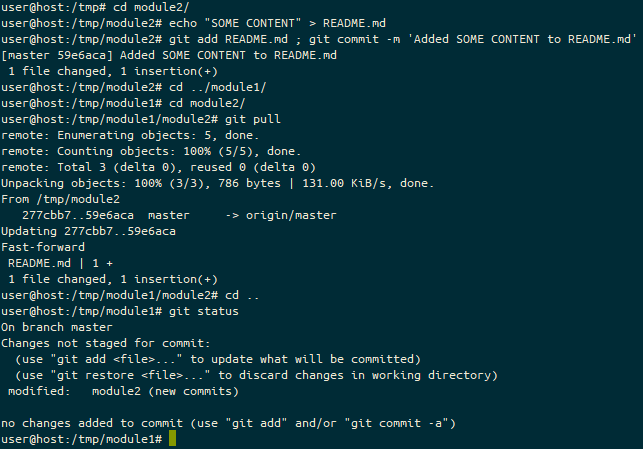
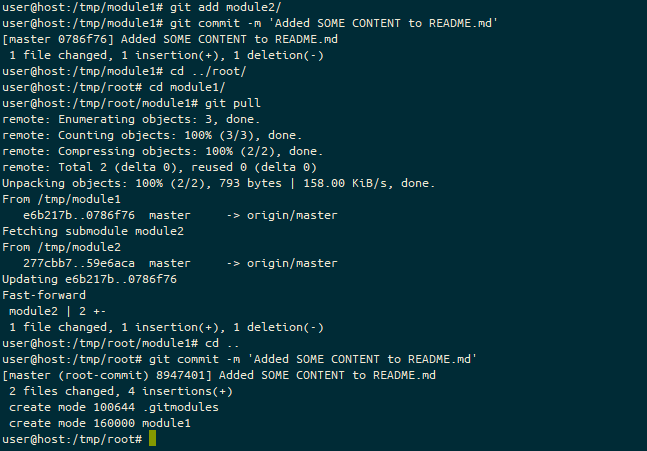
On the Self Hosted Podcast’s Discord Server, someone posted a link to the following blog post, which I read and found really interesting…: https://blog.hay-kot.dev/ssh-notifications-in-home-assistant/
You see, the key part of that post wasn’t that they were posting to Home Assistant when they were logging in, but instead that they were triggering a webhook on login. And I can do stuff with Webhooks.
What’s a webhook?
A webhook is a callable URL, either with a “secret” embedded in the URL or some authentication header that lets you trigger an action of some sort. I first came across these with Github, but they’re pretty common now. Services will offer these as a way to get an action in one service to do something in another. A fairly common webhook for those getting started with these sorts of things is where creating a pull request (PR) on a Github repository will trigger a message on something like Slack to say the PR is there.
Well, that’s all well and good, but what does Matrix or Huginn have to do with things?
Matrix is a decentralized, end to end encrypted, eventually consistent database system, that just happens to be used extensively as a chat network. In particular, it’s used by Open Source projects, like KDE and Mozilla, and by Government bodies, like the whole French goverment (lead by DINSIC) the German Bundeswehr (Unified Armed Forces) department.
Matrix has a reference client, Element, that was previously called “Riot”, and in 2018 I produced a YouTube video showing how to bridge various alternative messaging systems into Matrix.
Huginn describes itself as:
Huginn is a system for building agents that perform automated tasks for you online. They can read the web, watch for events, and take actions on your behalf. Huginn’s Agents create and consume events, propagating them along a directed graph. Think of it as a hackable version of IFTTT or Zapier on your own server. You always know who has your data. You do.
Huginn Readme
With Huginn, I can create “agents”, including a “receive webhook agent” that will take the content I send, and tweak it to do something else. In the past I used IFTTT to do some fun things, like making this blog work, but now I use Huginn to post Tweets when I post to this blog.
So that I knew that Huginn was posting my twitter posts, I created a Matrix room called “Huginn Alerts” and used the Matrix account I created for the video I mentioned before to send me messages that it had made the posts I wanted. I followed the guidance from this page to do it: https://drwho.virtadpt.net/archive/2020-02-12/integrating-huginn-with-a-matrix-server/
Enough already. Just show me what you did.
In Element.io
- Get an access token for the Matrix account you want to post with.
Log into the web interface at https://app.element.io and go to your settings
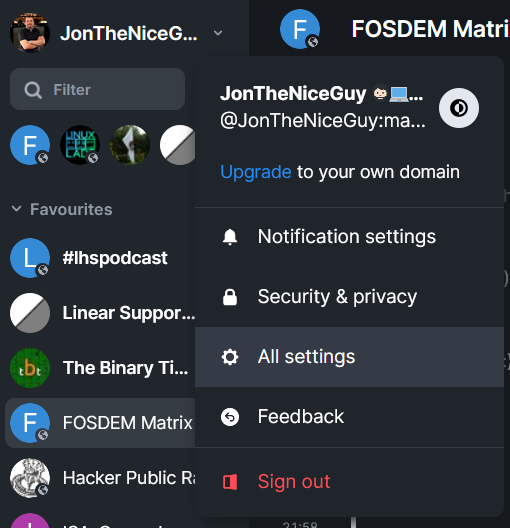
Then click on “Help & About” and scroll to the bottom of that page, where it says “Advanced”
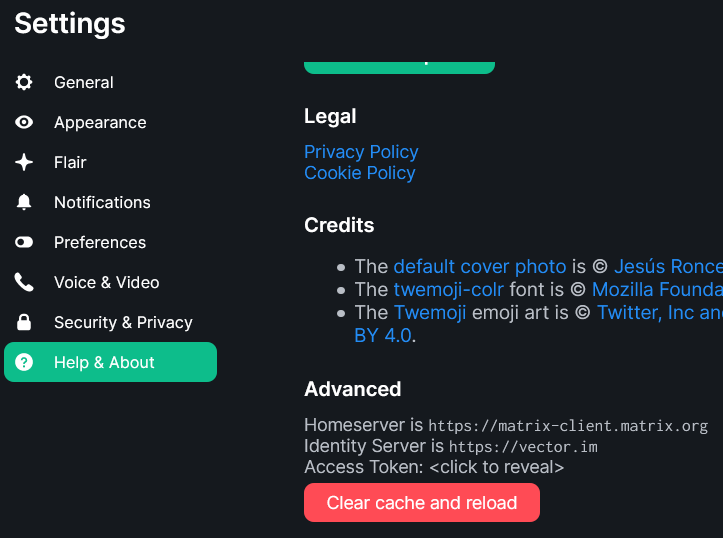
Click where it says “Access Token: <click to reveal>” (strangely, I’m not posting that 😉)
- Click on the room, then click on it’s name at the top to open the settings, then click on “Advanced” to get the “Internal room ID”
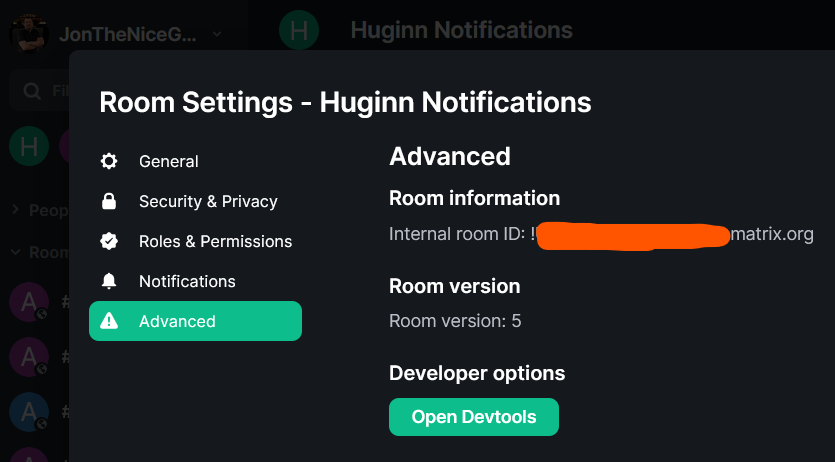
In Huginn
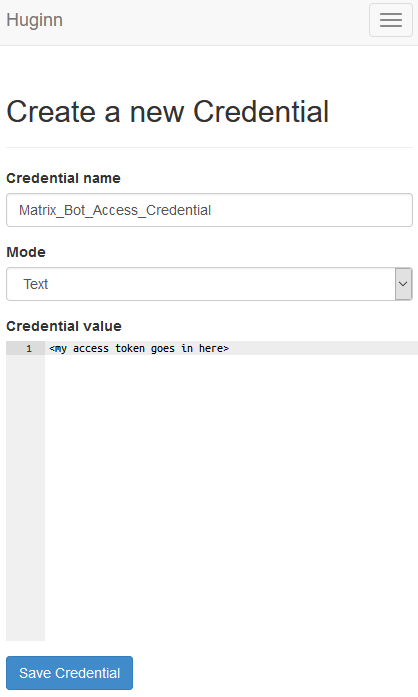
- Go to the “Credentials” tab, and click on “New Credential”. Give the credential a name (perhaps “Matrix Bot Access Token”), leave it as text and put your access token in here.
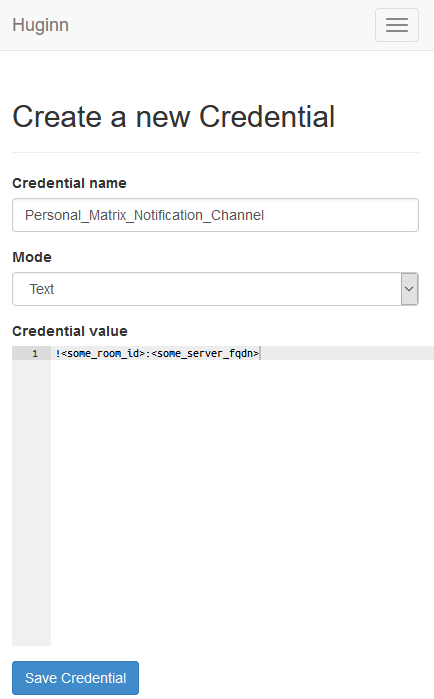
- Create a Credential for the Room ID. Like before, name it something sensible and put the ID you found earlier.
- Create a “Post Agent” by going to Agents and selecting “New agent”. This will show just the “Type” box. You can type in this box to put “Post Agent” and then find it. That will then provide you with the rest of these boxes. Provide a name, and tick the box marked “Propagate immediately”. I’ll cover the content of the “Options” box after this screenshot.
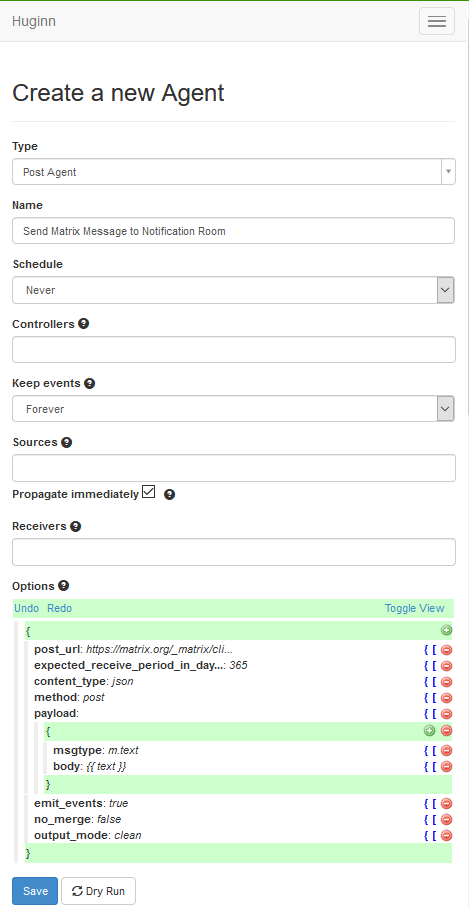
In the “Options” block is a button marked “Toggle View”. Select this which turns it from the above JSON pretty editor, into this text field (note your text is likely to be different):
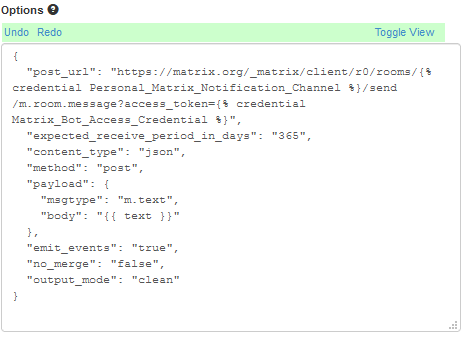
My content of that box is as follows:
{
"post_url": "https://matrix.org/_matrix/client/r0/rooms/{% credential Personal_Matrix_Notification_Channel %}/send/m.room.message?access_token={% credential Matrix_Bot_Access_Credential %}",
"expected_receive_period_in_days": "365",
"content_type": "json",
"method": "post",
"payload": {
"msgtype": "m.text",
"body": "{{ text }}"
},
"emit_events": "true",
"no_merge": "false",
"output_mode": "clean"
}Note that the “post_url” value contains two “credential” values, like this:
{% credential Personal_Matrix_Notification_Channel %} (this is the Room ID we found earlier) and {% credential Matrix_Bot_Access_Credential %} (this is the Access Token we found earlier).
If you’ve used different names for these values (which are perfectly valid!) then just change these two. The part where it says “{{ text }}” leave there, because we’ll be using that in a later section. Click “Save” (the blue button at the bottom).
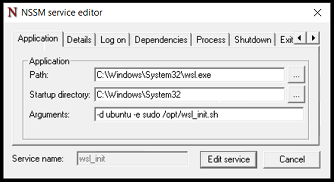
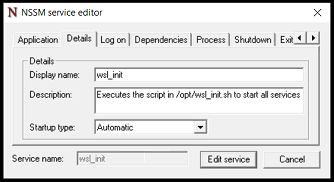
- Create a Webhook Agent. Go to Agents and then “New Agent”. Select “Webhook Agent” from the “Type” field. Give it a name, like “SSH Logged In Notification Agent”. Set “Keep Events” to a reasonable number of days, like 5. In “Receivers” find the Notification agent you created (“Send Matrix Message to Notification Room” was the name I used). Then, in the screenshot, I’ve pressed the “Toggle View” button on the “Options” section, as this is, to me a little clearer.
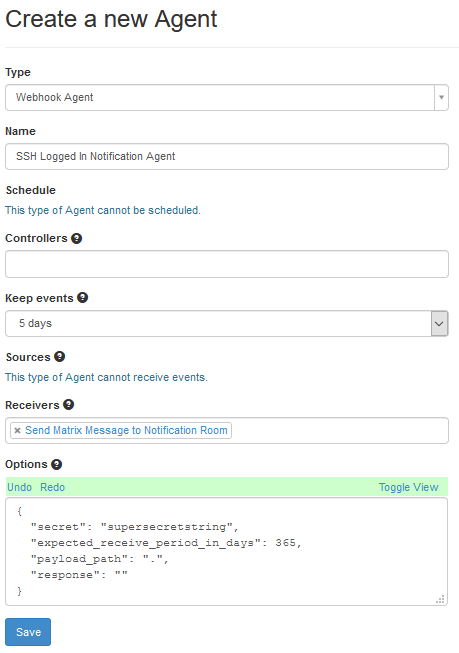
The content of the “options” box is:
{
"secret": "supersecretstring",
"expected_receive_period_in_days": 365,
"payload_path": ".",
"response": ""
}Change the “secret” from “supersecretstring” to something a bit more useful and secure.
The “Expected Receive Period in Days” basically means, if you’ve not had an event cross this item in X number of days, does Huginn think this agent is broken? And the payload path of “.” basically means “pass everything to the next agent”.
Once you’ve completed this step, press “Save” which will take you back to your agents, and then go into the agent again. This will show you a page like this:
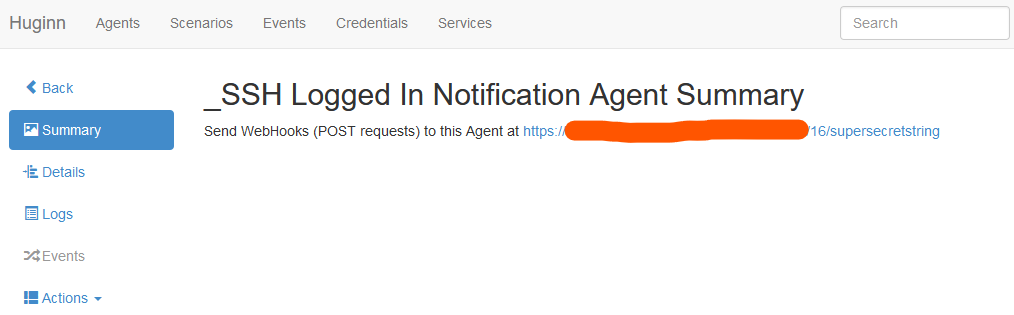
Copy that URL, because you’ll need it later…
On the server you are logging the SSH to
As root, create a file called /etc/ssh/sshrc. This file will be your script that will run every time someone logs in. It must have the file permissions 0644 (u+rw,g+r,o+r), which means that there is a slight risk that the Webhook secret is exposed.
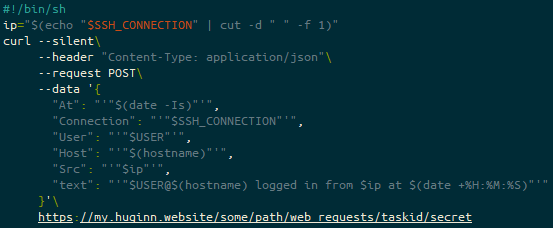
The content of that file is as follows:
#!/bin/sh
ip="$(echo "$SSH_CONNECTION" | cut -d " " -f 1)"
curl --silent\
--header "Content-Type: application/json"\
--request POST\
--data '{
"At": "'"$(date -Is)"'",
"Connection": "'"$SSH_CONNECTION"'",
"User": "'"$USER"'",
"Host": "'"$(hostname)"'",
"Src": "'"$ip"'",
"text": "'"$USER@$(hostname) logged in from $ip at $(date +%H:%M:%S)"'"
}'\
https://my.huginn.website/some/path/web_requests/taskid/secretThe heading line (#!/bin/sh) is more there for shellcheck, as, according to the SSH man page this is executed by /bin/sh either way.
The bulk of these values (At, Connection, User, Host or Src) are not actually used by Huginn, but might be useful for later… the key one is text, which if you recall from the “Send Matrix Message to Notification Room” Huginn agent, we put {{ text }} into the “options” block – that’s this block here!
So what happens when we log in over SSH?
SSH asks the shell in the user’s context to execute /etc/ssh/sshrc before it hands over to the user’s login session. This script calls curl and hands some POST data to the url.
Huginn receives this POST via the “SSH Logged In Notification Agent”, and files it.

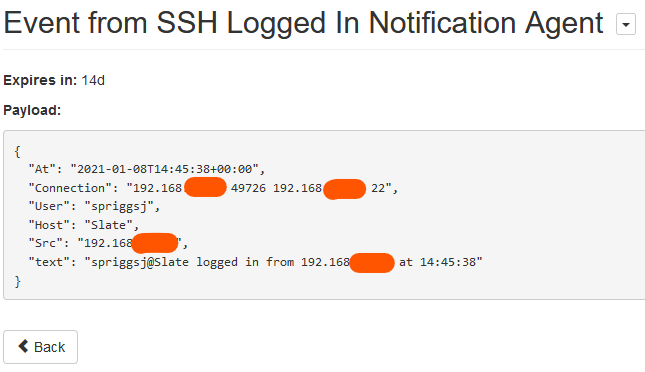
Huginn then hands that off to the “Send Matrix Message to Notification Room”:

Huginn makes a POST to the Matrix.org server, and Matrix sends the finished message to all the attached clients.

Featured image is “Raven” by “Jim Bahn” on Flickr and is released under a CC-BY license.