I’m starting to write some documentation, and I realised that I’ve not documented how I write with Markdown. So, let’s make some notes here :) This is largely drawn from the CommonMark Markdown Cheat Sheet, as well as my own experiences.
I’ll use the terms “Markdown” and “Commonmark” interchangeably, but really I’m talking about the “Commonmark” implementation of Markdown, as Markdown is just a “way of doing things”, whereas Commonmark is a specification to standardise how Markdown is done.
Late edit, 2020-06-24: My colleague, Simon Partridge, who writes the “Tech Snippets” round up of interesting content, pointed me to a Markdown Tutorial that he recommends. I’ve added two “Late Edit” comments below, in the Lists section and a new section called “Soft Breaks”, featuring stuff I’d not come across before that was on the Markdown Tutorial. It’s well worth a look! Dave Lee, the producer on the podcast I co-host, podcaster in his own right, and all-round-lovely-guy, also noted that the Walt Disney quote I included below wasn’t quite formatted right. I’ve fixed this, and added another example for clarity.
Normal text
This is normal text, you might know it in HTML as “paragraph” mode, or <p>some text</p>.
In your word processor, this is the default styled text that you start with.
In Markdown and Commonmark, line lengths don’t matter, you can just keep writing and writing and writing, or you can type 40 characters, and put a single new line in, and it’ll keep the text on the same line, like this:
In your word processor, this is the default styled
text that you start with.
In Markdown and Commonmark, line lengths don't matter, you can just keep writing and writing and writing or you can type 40 characters and put a single new line in, and it'll keep the text on the same line, like this:Links
While a single page of text is often useful, some people find it easier to connect to other documents. In HTML, you would do this by writing something like this: <a hrеf="http://example.com">Link</a>. In Markdown, you use this format:
You might want to put your [link](http://example.com) in here for later.
This link is in-line for ease of understanding.This makes it very easy to read in-line where a link is pointing to. It’s also possible to make those links listed elsewhere in the document, by writing something like this:
You might want to put your [link][1] in here for later.
Some documents include links elsewhere in their structure, which is easier
for moving links around your document, while keeping the formatting
structure.
[1]: (http://example.com)Links can be to absolute URLs (http://example.com/some/page.html), or relative URLs (some/page.html) and can include anchor points (http://example.com/some/page.html#heading-1). They can also link to other protocols, like email (mailto:person@example.org) or ftp (ftp://user:password@192.0.2.1/some/directory/).
Images
Much like the link layout, in HTML an image is inserted with a special tag, in that case, <img src="http://example.com/some/image.png" alt="Some Image">. An image can have an “Alt Tag”, which is text that a screen reader (for people with partial or complete vision loss) can read out. To put an image into a Markdown document, you use the link-style formatting, but add an exclamation mark before it, like this:

![Some other image][1]
[1]: (relative/paths/work/too.png)If you want to mix Images and Links, you do that like this:
[](my_link.html)Note that here it looks a little complicated, as you’ve got the image identifier (![]()) inside the link identifier ([]()). Again, you could also use some non-inline URLs to clarify that a little, like this:
[![Click here to send an email][email]](mailto:someone@example.net?subject=Enquiry)
[email]: http://example.org/assets/email.pngHeadings
You can prefix text with the # symbol and a space to make it a “top level heading”, like my heading for this blog post “Writing with Commonmark/Markdown formatting”, like this:
# Writing with Commonmark/Markdown formattingSubsequent level headings, from 2 (e.g. “Headings” above) to 6 are written like this:
## Headings
### Now also at level 3
#### And level 4
##### And so on
###### Until level 6
### You can also jump back up levels, if you need toTypically, you include a line space before and after the heading, just to make it clearer that this is a heading. It’s also possible to use the equals underlining and hyphen underlining to turn a single top level and second level heading, like this:
# Heading 1
is the same as
Heading 1
=========## Heading 2
is the same as
Heading 2
---------I’ve not really seen that structure before, but it seems less clear than the symbol-prefix method… I guess it’s just codifying some early practices.
Another benefit to the headings is that they automatically get turned into “anchor tags”, so you can refer to those points elsewhere in your document, like this:
Refer to [our sales literature for more details](#sales-literature).
## Sales Literature
Note that the anchor tag in this case is any heading tag (level 1 to 6), turned into lower case, and replacing any spaces with hyphens and removing any other characters.
Emphasis
Aside from the above, you can also use some punctuation to indicate emphasis, like this:
This is *bold* text. As is _this_.
This text is **italicised** instead. This is __too__.
This text is ***both*** bold and italicised. ___Also___ here.
So is __*this*__ and **_this_** and _**this**_ and *__this__*.Lists (ordered and unordered)
An ordered list looks like this:
1. Go to the shops
1. Open the door
2. Walk in
3. Select products
4. Pay for products
1. Use debit or credit card
2. Enter PIN
5. Open the door
6. Exit
2. Go homeand so on. An unordered list looks like this:
* Eggs
* Dairy
* Milk
* Cheese
* Meat
* Pork
* Ham
* Bacon
* BeefBoth of these can be rendered in Markdown using this format:
1. Go to the shops
1. Open the door
2. Walk in
3. Select products
* Eggs
* Dairy
* Milk
2. Go homeNotice that you can nest ordered and unordered lists. You need to provide four spaces when indenting from one level to the next.
If you’re not sure what the numbering will be, you can replace each of the numbers (1., 2., 3. and so on) with a single number, 1. Also, * for the unordered list can be replaced with -. So, the above example could look like this:
1. Go to the shops
1. Open the door
1. Walk in
1. Select products
- Eggs
- Dairy
* Milk
1. Go homeThis all depends on what writing style you prefer.
Late Edit: 2020-06-24 If you want to include a more content under the same list item, you can add a new line and indent it by at least one space (and usually to the same indenting level as the bullet point), like this:
1. Go to the shops
I've found going to Smiths, on the high street best.
1. Open the door
Use the handle on the edge of the door.
1. Walk in
1. Select products
Look for items with the best dates. The items you need are as follows:
- Eggs
- Dairy
* MilkSoft Breaks (Late edit, 2020-06-24)
A soft break, written in HTML as <br>, is signalled in Markdown with two spaces, like this (spaces replaced with . characters):
It.was.a.dark.day..
Bob.had.died.a.sad.death..
All.alone.in.his.fish.tankThis would be rendered like this (italicised to differentiate from the rest of this post):
It was a dark day
Bob had died a sad death
All alone in his fish tank
Quoting text
The way to get started is to quit talking and begin doing.
Walt Disney
People sometimes like to quote other people. In Markdown, we do this by following a long email convention, proceeding the quote with a “chevron” symbol – >, like this:
> The way to get started is to quit talking and begin doing.
>
> [*Walt Disney*](https://blog.hubspot.com/sales/famous-quotes)Note that this could also have been written like this:
As Walt Disney once said:
The way to get started is to quit talking and begin doing.
As [Walt Disney](https://blog.hubspot.com/sales/famous-quotes) once said:
> The way to get started is to quit talking and begin doing.Embedding code
This one I use all the time. Backticks (`) help you embed code, while three backticks (```) start a block of code, like this:
Also, `*` for the unordered list can be replaced with `-`.
```
> The way to get started is to quit talking and begin doing.
[Walt Disney](https://blog.hubspot.com/sales/famous-quotes)
```Some interpretations of Markdown (notably “Github Flavoured Markdown”) let you signal what type of code you’ve written by adding the language after the first set of three backticks, like this:
```bash
#!/bin/bash
echo "$1"
exit
```If three backticks don’t work for you, you can instead add four spaces before each line of your code, like this:
#!/bin/bash
echo "$1"
exitRaw HTML
Sometimes you just can’t do with Markdown what you want to achieve. I’ve notably found this with trying to incorporate several images and figure references in an ordered list, but in those cases, you can always use “raw HTML”. Here’s a list (from the Commonmark Spec as of version 0.29, dated 2019-04-06) of what tags are available to you:
address, article, aside, base, basefont, blockquote, body, caption, center, col, colgroup, dd, details, dialog, dir, div, dl, dt, fieldset, figcaption, figure, footer, form, frame, frameset, h1, h2, h3, h4, h5, h6, head, header, hr, html, iframe, legend, li, link, main, menu, menuitem, nav, noframes, ol, optgroup, option, p, param, section, source, summary, table, tbody, td, tfoot, th, thead, title, tr, track, ul
Given this, here’s what I tend to do:
1. Here's something to do with the following image<br>
<br>
*Figure 1 - Some image that is relevant*<br>Since looking into this further, this is now what I intend to do:
1. Here's something to do with the following image
<figure>
<figcaption>*Figure 1 - Some image that is relevant*</figcaption>
</figure>Tables
Not all Markdown flavours incorporate these, but some do. Trial-and-error is your friend here!
Github Flavoured Markdown supports tables, as do several other Markdown interpreters, but it’s explicitly not in Commonmark.
These are very basic tables, but will work for several cases. In this case, you MUST have a heading row (in my case, the first column has no name, but the second, third and fourth have the text “column” and then the alignment the subsequent rows follow), then a line which indicates the alignment of the row, either left (|---|), right (|--:|) or centre (|:-:|). All subsequent lines must contain all the columns specified. You can’t merge columns or rows, without resorting to HTML table definitions.
| | Column Left | Column Right | Column Centre |
|------|-------------|-------------:|:-------------:|
| row1 | 1 | 1 | 1 |
| row2 | 2 | 2 | 2 |
| row3 | 3 | 3 | 3 |In this case, you’ll get the following:
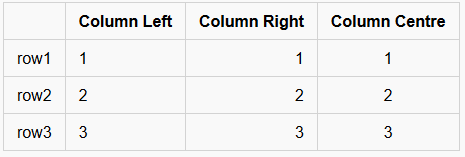
Note that different flavours disagree on whether the alignment of the text inside the rows matters, so while the above text works out OK, the following would also produce exactly the same result:
| | Column Left | Column Right | Column Centre |
|------|-------------|-------------:|:-------------:|
| row1 | 1 | 1 | 1 |
| row2 | 2 | 2 | 2 |
| row3 | 3 | 3 | 3 |As would this:
| | Column Left | Column Right | Column Centre |
|-|-|-:|:-:|
| row1 | 1 | 1 | 1 |
| row2 | 2 | 2 | 2 |
| row3 | 3 | 3 | 3 |Personally, I’d probably use the longer format divider line to match up to the column heads, but use the shorter format for the rows.
Using Markdown
- In projects on Github and Gitlab, any file suffixed
.mdwill usually be rendered as a Markdown file. Editing a Markdown file in Github at least will allow you to use the “preview” tab to see the changes. You can also include some Markdown in issues and pull/merge requests. It is not recommended for git logs, and IIRC won’t render it there either. - Visual Studio Code will preview Markdown, and has a “linting” extension, called “
markdownlint“, that will help identify common issues with Markdown. - WordPress’ “Gutenberg” block editor supports using markdown, both for importing content, and for using it to shortcut things like bold, italics, headings and links (in fact, I wrote rather a lot of this using it!).
- Popular blogging platform Ghost and static site creation tool Jekyll both use Markdown extensively.
Alternatives
- Naturally, Plain Text is an option :)
- You might also consider “Restructured Text” (RST) which are popular with open source projects for their documentation.
Featured image is “html tattoo” by “webmove” on Flickr and is released under a CC-BY license.