I have a pair of Proxmox servers, each with a single ZFS drive attached, with GlusterFS over the top to provide storage to the VMs.
Last week I had a power outage which took both nodes offline. When the power came back on, one node’s system drive had failed entirely and during recovery the second machine refused to restart some of the VMs.
Rather than try to fix things properly, I decided to “Nuke-and-Pave”, a decision I’m now regretting a little!
I re-installed one of the nodes OK, set up the new ZFS drive, set up Gluster and then started transferring the content from the old machine to the new one.
During the file transfer, I saw a couple of messages about failed blocks, and finally got a message from the cluster about how the pool was considered degraded, but as this was largely performed while I was asleep, I didn’t notice until I woke up… when the new node was offline.
I connected a Keyboard and Monitor to the box and saw a kernel panic. I rebooted the node, and during the boot sequence, just after the Systemd service that scanned the ZFS pool, it panicked again.
Unplugging the data drive from the machine and rebooting it, the node came up just fine.
I plugged the drive into my laptop and ran zpool import -d /dev/sdb1 -R /recovery/poolname poolname and my laptop crashed (although, I was running this in GUI mode, so I don’t know if it was a kernel panic or “just” a crash.)
Finally, I ran zpool import -d /dev/sdb1 -o read-only=on -R /recovery/poolname poolname and the drive came up in /recovery/poolname, so I could transfer files off to another drive until I figure out what’s going on!
Once I was done, I ran zfs unmount poolname and was able to detach the disk from the device.
How many times have you seen an instruction in a setup script which says “Now add source <(somescript completion bash) to your ~/.bashrc file” or “Add export SOMEVAR=abc123 to your .bashrc file”?
This is great when it’s one or two lines, but for a big chunk of them? Whew!
Instead, I created this block in mine:
if [ -d ~/.bash_extensions.d ]; then
for extension in ~/.bash_extensions.d/[a-zA-Z0-9]*
do
. "$extension"
done
fi
This dynamically loads all the files in ~/.bash_extensions.d/ which start with a letter or a digit, so it means I can manage when things get loaded in, or removed from my bash shell.
For example, I recently installed the pre-release of Atuin, so my ~/.bash_extensions.d/atuin file looks like this:
I’ve had a couple of issues with brown-outs recently which have interrupted my Proxmox server, and stopped my connected disks from coming back up cleanly (yes, I’m working on that separately!) but it’s left me in a state where several of my containers and virtual machines on the cluster are down.
It’s possible to point-and-click your way around this, but far easier to script it!
A failed state may look like this:
root@proxmox1:~# ha-manager status
quorum OK
master proxmox2 (active, Fri Mar 22 10:40:49 2024)
lrm proxmox1 (active, Fri Mar 22 10:40:52 2024)
lrm proxmox2 (active, Fri Mar 22 10:40:54 2024)
service ct:101 (proxmox1, error)
service ct:102 (proxmox2, error)
service ct:103 (proxmox2, error)
service ct:104 (proxmox1, error)
service ct:105 (proxmox1, error)
service ct:106 (proxmox2, error)
service ct:107 (proxmox2, error)
service ct:108 (proxmox1, error)
service ct:109 (proxmox2, error)
service vm:100 (proxmox2, error)
Once you’ve fixed your issue, you can do this on each node:
for worker in $(ha-manager status | grep "($(hostnamectl hostname), error)" | cut -d\ -f2)
do
echo "Disabling $worker"
ha-manager set $worker --state disabled
until ha-manager status | grep "$worker" | grep -q disabled ; do sleep 1 ; done
echo "Restarting $worker"
ha-manager set $worker --state started
until ha-manager status | grep "$worker" | grep -q started ; do sleep 1 ; done
done
Note that this hasn’t been tested, but a scan over it with those nodes working suggests it should. I guess I’ll be updating this the next time I get a brown-out!
I wrote this post in January 2023, and it’s been languishing in my Drafts folder since then. I’ve had a look through it, and I can’t see any glaring reasons why I didn’t publish it so… it’s published… Enjoy 😁
If you’ve ever built a private subnet in AWS, you know it can be a bit tricky to get updates from the Internet – you end up having a NAT gateway or a self-managed proxy, and you can never be 100% certain that the egress traffic isn’t going somewhere you don’t want it to.
In this case, I wanted to ensure that outbound HTTPS traffic was being blocked if the SNI didn’t explicitly show the DNS name I wanted to permit through, and also, I only wanted specific DNS names to resolve. To do this, I used AWS Network Firewall and Route 53 DNS Firewall.
I’ve written this blog post, and followed along with this, I’ve created a set of terraform files to represent the steps I’ve taken.
The Setup
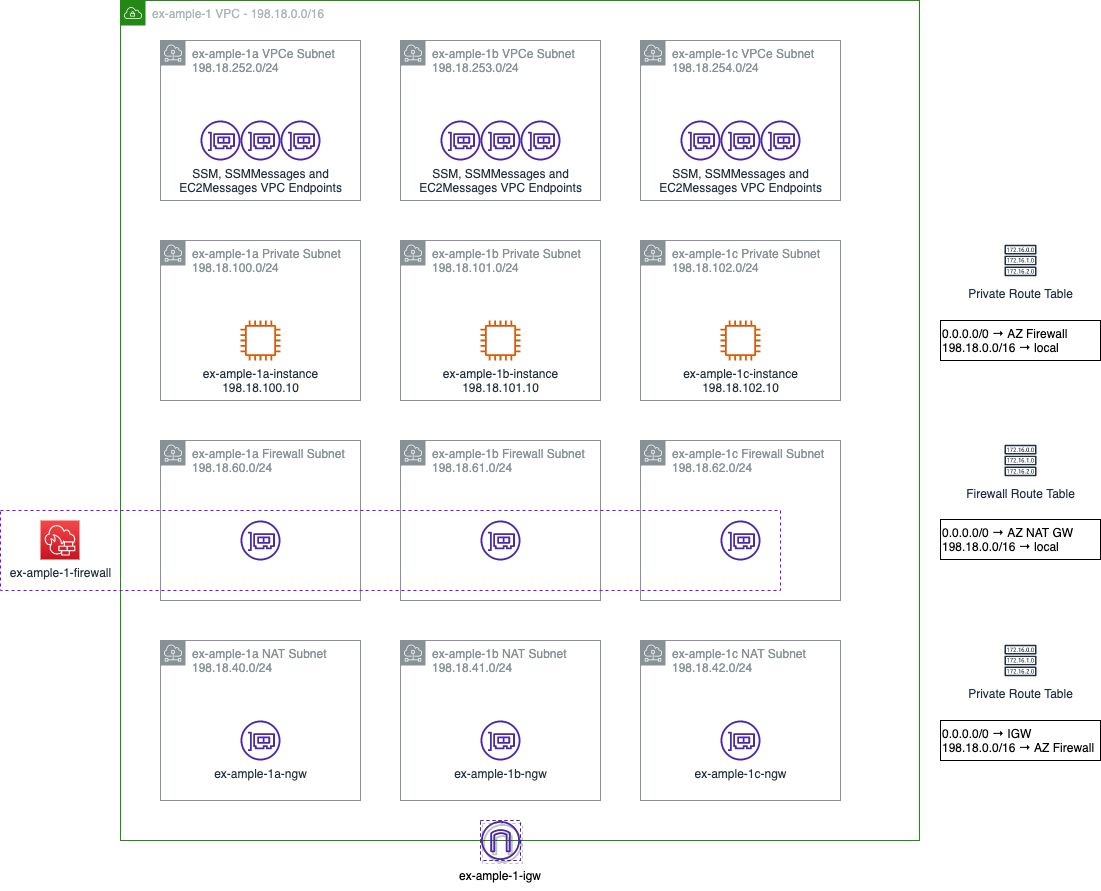
Let’s start this story from a simple VPC with three private subnets for my compute resources, and three private subnets for the VPC Endpoints for Systems Manager (SSM).
Here’s our network diagram, with the three subnets containing the VPC Endpoints at the top, and the three instances at the bottom.
At this point, none of those instances can reach anything outside the network, with the exception of the SSM environment. So, we can’t install any packages, we can’t get data from outside the network or anything similar.
Getting Protected Internet Access
In order to get internet access, we need to add 4 things;
An internet gateway
A NAT gateway in each AZ
Which needs three new subnets
And three Elastic IP addresses
Route tables in all the subnets
To clarify, a NAT gateway acts like a DSL router. It hides the source IP address of outbound traffic behind a single, public IP address (using an Elastic IP from AWS), and routes any return traffic back to wherever that traffic came from. To reduce inter-AZ data transfer rates, I’m putting one in each AZ, but if there’s not a lot of outbound traffic or the outbound traffic isn’t critical enough to require resiliency, this could all be centralised to a single NAT gateway. To put a NAT gateway in each AZ, you need a subnet in each AZ, and to get out to the internet (by whatever means you have), you need an internet gateway and route tables for how to reach the NAT and internet gateways.
We also should probably add, at this point, four additional things.
The Network Firewall
Subnets for the Firewall interfaces
Stateless Policy
Stateful Policy
The Network Firewall acts like a single appliance, and uses a Gateway Load Balancer to present an interface into each of the availability zones. It has a stateless policy (which is very fast, but needs to address both inbound and outbound traffic flows) to do IP and Port based filtering (referred to as “Layer 3” filtering) and then specific traffic can be passed into a stateful policy (which is slower) to do packet and flow inspection.
In this case, I only want outbound HTTPS traffic to be passed, so my stateless rule group is quite simple;
VPC range on any port → Internet on TCP/443; pass to Stateful rule groups
Internet on TCP/443 → VPC range on any port; pass to Stateful rule groups
I have two stateful rule groups, one is defined to just allow access out to example.com and any relevant subdomains, using the “Domain List” stateful policy item. The other allows access to example.org and any relevant subdomains, using a Suricata stateful policy item, to show the more flexible alternative route. (Suricata has lots more filters than just the SNI value, you can check for specific SSH versions, Kerberos CNAMEs, SNMP versions, etc. You can also add per-rule logging this way, which you can’t with the Domain List route).
These are added to the firewall policy, which also defines that if a rule doesn’t match a stateless rule group, or an established flow doesn’t match a stateful rule group, then it should be dropped.
New network diagram with more subnets and objects, but essentially, as described in the paragraphs above. Traffic flows from the instances either down towards the internet, or up towards the VPCe.
So far, so good… but why let our users even try to resolve the DNS name of a host they’re not permitted to reach. Let’s turn on DNS Firewalling too.
Turning on Route 53 DNS Firewall
You’ll notice that in the AWS Network Firewall, I didn’t let DNS out of the network. This is because, by default, AWS enables Route 53 as it’s local resolver. This lives on the “.2” address of the VPC, so in my example environment, this would be 198.18.0.2. Because it’s a local resolver, it won’t cross the Firewall exiting to the internet. You can also make Route 53 use your own DNS servers for specific DNS resolution (for example, if you’re running an Active Directory service inside your network).
Any Network Security Response team members you have working with you would appreciate it if you’d turn on DNS Logging at this point, so I’ll do it too!
In March 2021, AWS announced “Route 53 DNS Firewall”, which allow this DNS resolver to rewrite responses, or even to completely deny the existence of a DNS record. With this in mind, I’m going to add some custom DNS rules.
The first thing I want to do is to only permit traffic to my specific list of DNS names – example.org, example.com and their subdomains. DNS quite likes to terminate DNS names with a dot, signifying it shouldn’t try to resolve any higher up the chain, so I’m going to make a “permitted domains” DNS list;
And then build a DNS Firewall Policy which allows access to the “permitted domains”, “VPCe” lists, but blocks resolution of any “default deny” entries.
So there we have it. While the network is not “secure” (there’s still a few gaps here) it’s certainly MUCH more secure than it was, and it certainly would take a lot more work for anyone with malicious intent to get your content out.
Feel free to have a poke around, and leave comments below if this has helped or is of interest!
I keep trundling back to a collection of WordPress plugins that I really love. And sometimes I want to contribute patches to the plugin.
I don’t want to develop against this server (that would be crazy… huh… right… no one does that… *cough*) but instead, I want a nice, fresh and new WordPress instance to just check that it works the way I was expecting.
So, I created a little Vagrant environment, just for testing WordPress plugins. I clone the repository for the plugin, and create a “TestingEnvironment” directory in there.
I then create the following Vagrantfile.
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/jammy64"
# This will create an IP address in the range 192.168.64.0/24 (usually)
config.vm.network "private_network", type: "dhcp"
# This loads the git repo for the plugin into /tmp/git_repo
config.vm.synced_folder "../", "/tmp/git_repo"
# If you've got vagrant-cachier, this will speed up apt update/install operations
if Vagrant.has_plugin?("vagrant-cachier")
config.cache.scope = :box
end
config.vm.provision "shell", inline: <<-SHELL
# Install Dependencies
apt-get update
apt-get install -y apache2 libapache2-mod-fcgid php-fpm mysql-server php-mysql git
# Set up Apache
a2enmod proxy_fcgi setenvif
a2enconf "$(basename "$(ls /etc/apache2/conf-available/php*)" .conf)"
systemctl restart apache2
rm -f /var/www/html/index.html
# Set up WordPress
bash /vagrant/root_install_wordpress.sh
SHELL
end
Next, let’s create that root_install_wordpress.sh file.
#! /bin/bash
# Allow us to run commands as www-data
chsh -s /bin/bash www-data
# Let www-data access files in the web-root.
chown -R www-data:www-data /var/www
# Install wp-cli system-wide
curl -s -S -O https://raw.githubusercontent.com/wp-cli/builds/gh-pages/phar/wp-cli.phar
mv wp-cli.phar /usr/local/bin/wp
chmod +x /usr/local/bin/wp
# Slightly based on
# https://www.a2hosting.co.uk/kb/developer-corner/mysql/managing-mysql-databases-and-users-from-the-command-line
echo "CREATE DATABASE wp;" | mysql -u root
echo "CREATE USER 'wp'@'localhost' IDENTIFIED BY 'wp';" | mysql -u root
echo "GRANT ALL PRIVILEGES ON wp.* TO 'wp'@'localhost';" | mysql -u root
echo "FLUSH PRIVILEGES;" | mysql -u root
# Execute the generic install script
su - www-data -c bash -c /vagrant/user_install_wordpress.sh
# Install any plugins with this script
su - www-data -c bash -c /vagrant/customise_wordpress.sh
# Log the path to access
echo "URL: http://$(sh /vagrant/get_ip.sh) User: admin Password: password"
Now we have our dependencies installed and our database created, let’s get WordPress installed with user_install_wordpress.sh.
#! /bin/bash
# Largely based on https://d9.hosting/blog/wp-cli-install-wordpress-from-the-command-line/
cd /var/www/html
# Install the latest WP into this directory
wp core download --locale=en_GB
# Configure the database with the credentials set up in root_install_wordpress.sh
wp config create --dbname=wp --dbuser=wp --dbpass=wp --locale=en_GB
# Skip the first-run-wizard
wp core install --url="http://$(sh /vagrant/get_ip.sh)" --title=Test --admin_user=admin --admin_password=password --admin_email=example@example.com --skip-email
# Setup basic permalinks
wp option update permalink_structure ""
# Flush the rewrite schema based on the permalink structure
wp rewrite structure ""
Excellent. This gives us a working WordPress environment. Now we need to add our customisation – the plugin we’re deploying. In this case, I’ve been tweaking the “presenter” plugin so here’s the customise_wordpress.sh code:
Actually, that /tmp/git_repo path is a call-back to this line in the Vagrantfile: config.vm.synced_folder "../", "/tmp/git_repo".
And there you have it; a vanilla WordPress install, with the plugin installed and ready to test. It only took 4 years to write up a blog post for it!
As an alternative, you could instead put the plugin you’re working with in a subdirectory of the Vagrantfile and supporting files, then you’d just need to change that git clone /tmp/git_repo line to git clone /vagrant/MyPlugin – but then you can’t offer this to the plugin repo as a PR, can you? 😀
Tale as old as time, the compute instance type you want to use in AWS is highly contested (or worse yet, not as available in every availability zone in your region)! You plead with your TAM or AM “Please let us have more of that instance type” only to be told “well, we can put in a request, but… haven’t you thought about using a range of instance types”?
And yes, I’ve been on both sides of that conversation, sadly.
The commented terraform
# This is your legacy instance_type variable. Ideally we'd have
# a warning we could raise at this point, telling you not to use
# this variable, but... it's not ready yet.
variable "instance_type" {
description = "The legacy single-instance size, e.g. t3.nano. Please migrate to instance_types ASAP. If you specify instance_types, this value will be ignored."
type = string
default = null
}
# This is your new instance_types value. If you don't already have
# some sort of legacy use of the instance_type variable, then don't
# bother with that variable or the locals block below!
variable "instance_types" {
description = "A list of instance sizes, e.g. [t2.nano, t3.nano] and so on."
type = list(string)
default = null
}
# Use only this locals block (and the value further down) if you
# have some legacy autoscaling groups which might use individual
# instance_type sizes.
locals {
# This means if var.instance_types is not defined, then use it,
# otherwise create a new list with the single instance_type
# value in it!
instance_types = var.instance_types != null ? var.instance_types : [ var.instance_type ]
}
resource "aws_launch_template" "this" {
# The prefix for the launch template name
# default "my_autoscaling_group"
name_prefix = var.name
# The AMI to use. Calculated outside this process.
image_id = data.aws_ami.this.id
# This block ensures that any new instances are created
# before deleting old ones.
lifecycle {
create_before_destroy = true
}
# This block defines the disk size of the root disk in GB
block_device_mappings {
device_name = data.aws_ami.centos.root_device_name
ebs {
volume_size = var.disksize # default "10"
volume_type = var.disktype # default "gp2"
}
}
# Security Groups to assign to the instance. Alternatively
# create a network_interfaces{} block with your
# security_groups = [ var.security_group ] in it.
vpc_security_group_ids = [ var.security_group ]
# Any on-boot customizations to make.
user_data = var.userdata
}
resource "aws_autoscaling_group" "this" {
# The name of the Autoscaling Group in the Web UI
# default "my_autoscaling_group"
name = var.name
# The list of subnets into which the ASG should be deployed.
vpc_zone_identifier = var.private_subnets
# The smallest and largest number of instances the ASG should scale between
min_size = var.min_rep
max_size = var.max_rep
mixed_instances_policy {
launch_template {
# Use this template to launch all the instances
launch_template_specification {
launch_template_id = aws_launch_template.this.id
version = "$Latest"
}
# This loop can either use the calculated value "local.instance_types"
# or, if you have no legacy use of this module, remove the locals{}
# and the variable "instance_type" {} block above, and replace the
# for_each and instance_type values (defined as "local.instance_types")
# with "var.instance_types".
#
# Loop through the whole list of instance types and create a
# set of "override" values (the values are defined in the content{}
# block).
dynamic "override" {
for_each = local.instance_types
content {
instance_type = local.instance_types[override.key]
}
}
}
instances_distribution {
# If we "enable spot", then make it 100% spot.
on_demand_percentage_above_base_capacity = var.enable_spot ? 0 : 100
spot_allocation_strategy = var.spot_allocation_strategy
spot_max_price = "" # Empty string is "on-demand price"
}
}
}
So what is all this then?
This is two Terraform resources; an aws_launch_template and an aws_autoscaling_group. These two resources define what should be launched by the autoscaling group, and then the settings for the autoscaling group.
You will need to work out what instance types you want to use (e.g. “must have 16 cores and 32 GB RAM, have an x86_64 architecture and allow up to 15 Gigabit/second throughput”)
When might you use this pattern?
If you have been seeing messages like “There is no Spot capacity available that matches your request.” or “We currently do not have sufficient <size> capacity in the Availability Zone you requested.” then you need to consider diversifying the fleet that you’re requesting for your autoscaling group. To do that, you need to specify more instance types. To achieve this, I’d use the above code to replace (something like) one of the code samples below.
Then this new method is a much better idea :) Even more so if you had two launch templates to support spot and non-spot instance types!
Hat-tip to former colleague Paul Moran who opened my eyes to defining your fleet of variable instance types, as well as to my former customer (deliberately unnamed) and my current employer who both stumbled into the same documentation issue. Without Paul’s advice with my prior customer’s issue I’d never have known what I was looking for this time around!
I have a small server running Docker for services at home. There are several services which will want to use HTTP, but I can’t have them all sharing the same port without a reverse proxy to manage how to route the traffic to the containers!
This is my guide to how I got Traefik set up to serve HTTP and HTTPS traffic.
The existing setup for one service
Currently, I have phpIPAM which has the following docker-compose.yml file:
The moment I want to bind another service to TCP/80, I get an error because we’ve already used TCP/80 for phpIPAM. Enter Traefik. Let’s stop the docker container with docker compose down and build our Traefik setup.
Traefik Setup
I always store my docker compose files in /opt/docker/<servicename>, so let’s create a directory for traefik; sudo mkdir -p /opt/docker/traefik
The (“dynamic”) configuration file
Next we need to create a configuration file called traefik.yaml
# Ensure all logs are sent to stdout for `docker compose logs`
accessLog: {}
log: {}
# Enable docker provider but don't switch it on by default
providers:
docker:
exposedByDefault: false
# Select this as the docker network to connect from traefik to containers
# This is defined in the docker-compose.yaml file
network: web
# Enable the API and Dashboard on TCP/8080
api:
dashboard: true
insecure: true
debug: true
# Listen on both HTTP and HTTPS
entryPoints:
http:
address: ":80"
http: {}
https:
address: ":443"
http:
tls: {}
With the configuration file like this, we’ll serve HTTPS traffic with a self-signed TLS certificate on TCP/443 and plain HTTP on TCP/80. We have a dashboard on TCP/8080 served over HTTP, so make sure you don’t expose *that* to the public internet!
The Docker-Compose File
Next we need the docker-compose file for Traefik, so let’s create docker-compose.yaml
There are a few parts here which aren’t spelled out on the Traefik quickstart! Firstly, if you don’t define a network, it’ll create one using the docker-compose file path, so probably traefik_traefik or traefik_default, which is not what we want! So, we’ll create one called “web” (but you can call it whatever you want. On other deployments, I’ve used the name “traefik” but I found it tedious to remember how to spell that each time). This network needs to be “attachable” so that other containers can use it later.
You then attach that network to the traefik service, and expose the ports we need (80, 443 and 8080).
And then start the container with docker compose up -d
alpine-docker:/opt/docker/traefik# docker compose up -d
[+] Running 2/2
✔ Network web Created 0.2s
✔ Container traefik-traefik-1 Started 1.7s
alpine-docker:/opt/docker/traefik#
Adding Traefik to phpIPAM
Going back to phpIPAM, So that Traefik can reach the containers, and so that the container can reach it’s database, we need two network statements now; the first is the “external” network for the traefik connection which we called “web“. The second is the inter-container network so that the “web” service can reach the “db” service, and so that the “cron” service can reach the “db” service. So we need to add that to the start of /opt/docker/phpipam/docker-compose.yaml, like this;
We then need to add both networks that to the “web” container, like this:
services:
web:
image: phpipam/phpipam-www:latest
networks:
- ipam
- web
# ...... and the rest of the config
Remove the “ports” block and replace it with an expose block like this:
services:
web:
# ...... The rest of the config for this service
## Don't bind to port 80 - we use traefik now
# ports:
# - "80:80"
## Do expose port 80 for Traefik to use
expose:
- 80
# ...... and the rest of the config
And just the inter-container network to the “cron” and “db” containers, like this:
cron:
image: phpipam/phpipam-cron:latest
networks:
- ipam
# ...... and the rest of the config
db:
image: mariadb:latest
networks:
- ipam
# ...... and the rest of the config
There’s one other set of changes we need to make in the “web” service, which are to enable Traefik to know that this is a container to look at, and to work out what traffic to send to it, and that’s to add labels, like this:
services:
web:
# ...... The rest of the config for this service
labels:
- traefik.enable=true
- traefik.http.routers.phpipam.rule=Host(`phpipam.homenet`)
# ...... and the rest of the config
Right, now we run docker compose up -d
alpine-docker:/opt/docker/phpipam# docker compose up -d
[+] Running 4/4
✔ Network ipam Created 0.4s
✔ Container phpipam-db-1 Started 1.4s
✔ Container phpipam-cron-1 Started 2.1s
✔ Container phpipam-web-1 Started 2.6s
alpine-docker:/opt/docker/phpipam#
If you notice, this doesn’t show to the web network being created (because it was already created by Traefik) but does bring up the container.
Checking to make sure it’s working
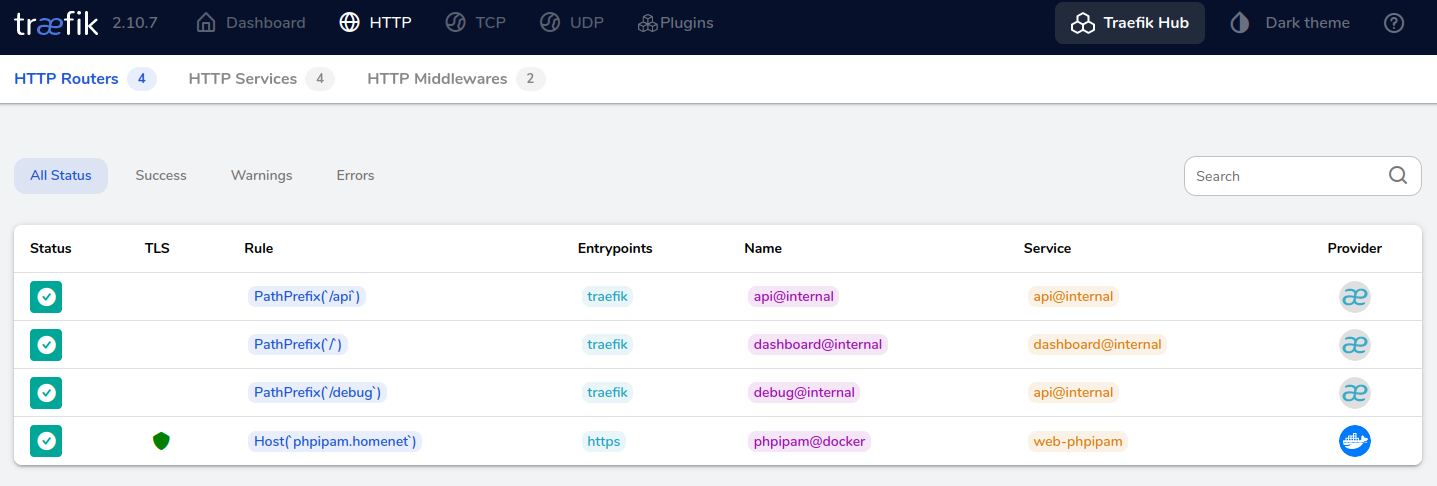
If we head to the Traefik dashboard (http://your-docker-server:8080) you’ll see the phpipam service identified there… yey!
Better TLS with Lets Encrypt
So, at home I actually have a DNS suffix that is a real DNS name. For the sake of the rest of this documentation, assume it’s homenet.sprig.gs (but it isn’t 😁).
This DNS space is hosted by Digital Ocean, so I can use a DNS Challenge with Lets Encrypt to provide hostnames which are not publically accessible. If you’re hosting with someone else, then that’s probably also available – check the Traefik documentation for your specific variables. The table on that page (as of 2023-12-30) shows the environment variables you need to pass to Traefik to get LetsEncrypt working.
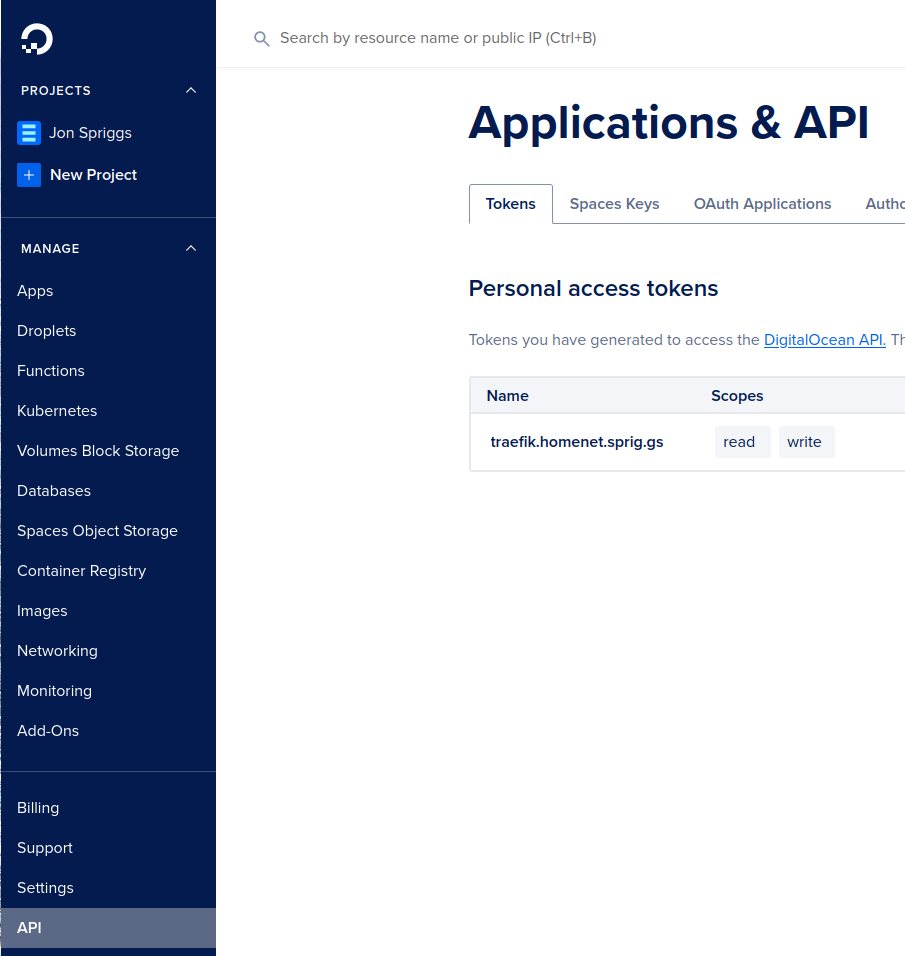
As you can see here, I just need to add the value DO_AUTH_TOKEN, which is an API key. I went to the Digital Ocean console, and navigated to the API panel, and added a new “Personal Access Token”, like this:
Notice that the API key needed to provide both “Read” and “Write” capabilities, and has been given a name so I can clearly see it’s purpose.
Changing the traefik docker-compose.yaml file
In /opt/docker/traefik/docker-compose.yaml we need to add that new environment variable; DO_AUTH_TOKEN, like this:
services:
traefik:
# ...... The rest of the config for this service
environment:
DO_AUTH_TOKEN: dop_v1_decafbad1234567890abcdef....1234567890
# ...... and the rest of the config
Changing the traefik.yaml file
In /opt/docker/traefik/traefik.yaml we need to tell it to use Let’s Encrypt. Add this block to the end of the file:
Obviously change the email address to a valid one for you! I hit a few issues with the value specified in the documentation for delayBeforeCheck, as their value of “0” wasn’t long enough for the DNS value to be propogated around the network – 1 minute is enough though!
I also had to add the resolvers, as my local network has a caching DNS server, so I’d never have seen the updates! You may be able to remove both those values from your files.
Now you’ve made all the changes to the Traefik service, restart it with docker compose down ; docker compose up -d
Changing the services to use Lets Encrypt
We need to add one final label to the /opt/docker/phpipam/docker-compose.yaml file, which is this one:
services:
web:
# ...... The rest of the config for this service
labels:
- traefik.http.routers.phpipam.tls.certresolver=letsencrypt
# ...... and the rest of the config
Also, update your .rule=Host(`hostname`) to use the actual DNS name you want to be able to use, then restart the docker container.
phpIPAM doesn’t like trusting proxies, unless explicitly told to, so I also had add an environment variable IPAM_TRUST_X_FORWARDED=true to the /opt/docker/phpipam/docker-compose.yaml file too, because phpIPAM tried to write the HTTP scheme for any links which came up, based on what protocol it thought it was running – not what the proxy was telling it it was being accessed as!
Debugging any issues
If you have it all setup as per the above, and it isn’t working, go into /opt/docker/traefik/traefik.yaml and change the stanza which says log: {} to:
log:
level: DEBUG
Be aware though, this adds a LOT to your logs! (But you won’t see why your ACME requests have failed without it). Change it back to log: {} once you have it working again.
Adding your next service
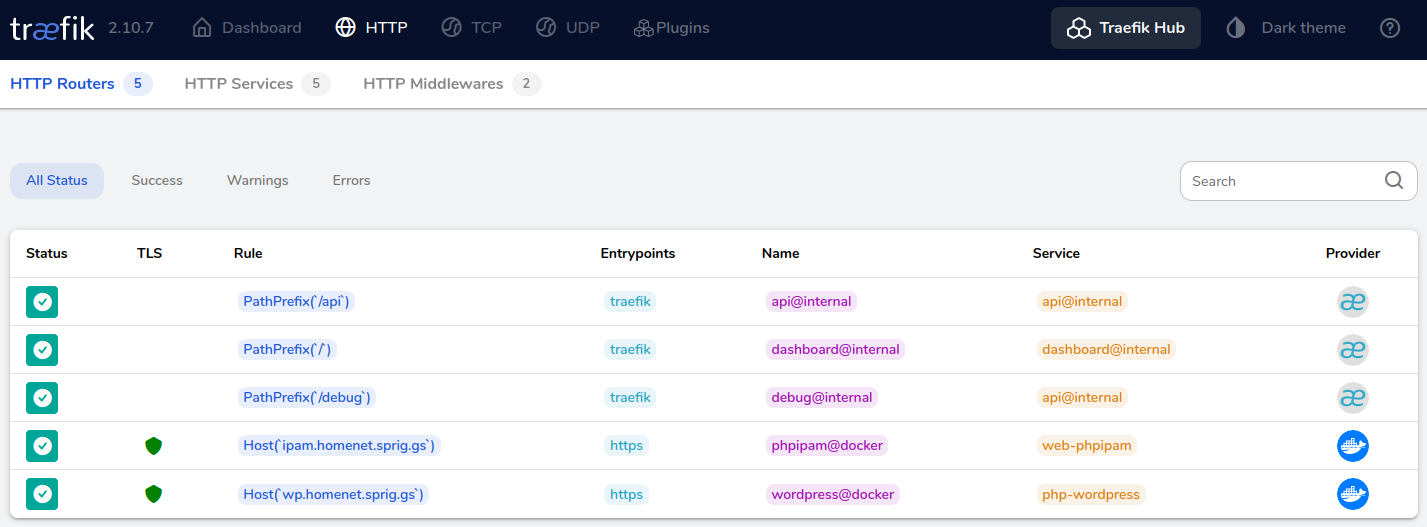
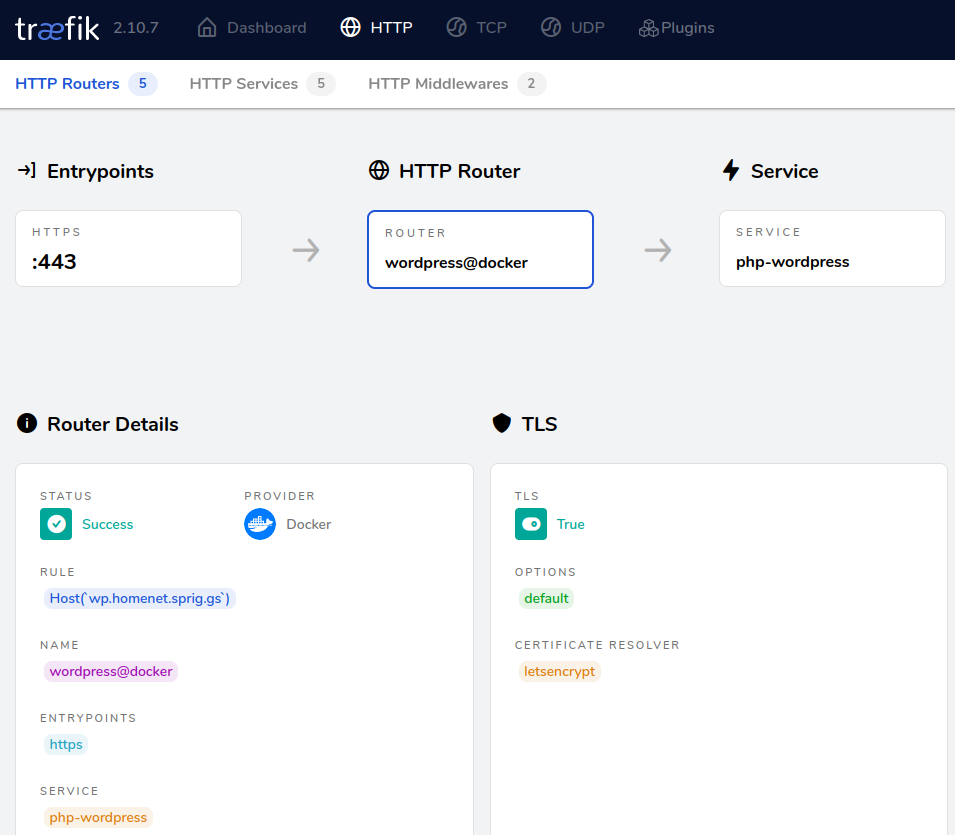
I now want to add that second service to my home network – WordPress. Here’s /opt/docker/wordpress/docker-compose.yaml for that service;
alpine-docker:/opt/docker/wordpress# docker compose up -d
[+] Running 3/3
✔ Network wordpress Created 0.2s
✔ Container wordpress-mariadb-1 Started 3.0s
✔ Container wordpress-php-1 Started 3.8s
alpine-docker:/opt/docker/wordpress#
Tada!
One final comment – I never did work out how to make connections forceably upgrade from HTTP to HTTPS, so instead, I shut down port 80 in Traefik, and instead run this container.
At work last week, I finally solved an issue by writing some code, and I wanted to explain why I wrote it.
At it’s core, Kubernetes is an orchestrator which runs “Container Images”, which are structured filesystem snapshots, taken after running individual commands against a base system. These container images are stored in a container registry, and the most well known of these is the Docker registry, known as Docker Hub.
A registry can be public, meaning you don’t need credentials to get any images from it, or private. Some also offer a mixed-mode where you can make a certain number of requests without requiring authentication, but if you need more than that amount of requests, you need to provide credentials.
During the build-out of a new cluster, I discovered that the ECR (Elastic Container Registry) from AWS requires a new type of authentication – the Kubelet Credential Provider, which required the following changes:
In /etc/sysconfig/kubelet you provide these two switches; --image-credential-provider-bin-dir /usr/local/bin/image-credential-provider and --image-credential-provider-config /etc/kubernetes/image-credential-provider-config.json.
In /etc/kubernetes/image-credential-provider-config.json you provide a list of registries and the credential provider to use, which looks like this:
I will confess I made heavy use of ChatGPT to get a steer on certain aspects of how to write the code, but all the code is generic and there’s nothing proprietary in this code.
Using the Generic Credential Provider
Follow the steps above – change your Kubernetes environment to ensure you have the kubelet configuration changes and the JSON credential provider configuration put in the relevant parts of your tree. Set the “matchImages” values to include the registry in question – for dockerhub, I’d probably use ["docker.io", "*.docker.io"]
Download the generic-credential-provider script from Github, put it in the right path in your worker node’s filesystem (if you followed my notes above it’ll be in /usr/local/bin/image-credential-provider/generic-credential-provider but this is *your* system we’re talking about, not mine! You know your build better than I do!)
Create the /etc/kubernetes/registries directory – this can be changed by editing the script to use a new path, and for testing purposes there is a flag --credroot /some/new/path but that doesn’t work for the kubelet configuration file.
Create a credential file, for example, /etc/kubernetes/registries/example.org.json which contains this string: {"username":"token_username","password":"token_password"}. [Yes, it’s a plaintext credential. Make sure it’s scoped for only image downloads. No, this still isn’t very good. But how else would you do this?! (Pull requests are welcomed!)] You can add a duration value into that JSON dictionary, to change the default timeout from 5 minutes. Technically, the default is actually set in /etc/kubernetes/image-credential-provider-config.json but I wanted to have my own per-credential, and as these values are coming from the filesystem, and therefore has very little performance liability, I didn’t want to have a large delay in the cache.
You should also see an entry in your syslog service showing a line that says “Credential request fulfilled for your.registry.example.com” and if you pass it a check that it fails, it should say “Failed to fulfill credential request for failure.example.org“.
Late edit 2025-12-04: I had cause today to revisit this. While this may help you to build your own Credential Provider, it doesn’t provide enough detail to test why an image isn’t pulling. For that I wrote and later asked Claude to enhance a script to pull images. That’s here: pullImage Functions
If this helped you, please consider buying me a drink to say thanks!
I recently got talking to a colleague about how people prefer to work and how they prefer to be contacted. It’s obvious in an office – if Bob isn’t there, then he’s not around, but when some of the team is remote, some are hybrid working, then it’s a lot harder.
There are three things I’ve found are really useful to know when trying to reach someone, and I’ve written this up in a simple page stored on our internal wiki;
What’s your baseline – where do you live and when are you usually in the office.
What are your usual working hours – how accurate is your calendar for non-meetings? do you have fixed meetings that happen every week, or a school run that you typically do? Do you need to be away from your desk at certain times for religious reasons?
What’s the best way to contact you – if you’ve got a choice of tools (like Slack Hangouts or Google Meet) which would you rather use, and why. Is it best to drop in a 15 minute appointment, or just call you?
Once you’ve got these three items, in something everyone can access, add it to your directory profile, bio on slack, your email signature (for internal emails) and so on.
From here to the end of the post is a mildly sanitised version of my internally posted profile. I hope it’s useful to you!
Baseline
I am based in the UK, using the Europe/London time zone. I am remote based with very infrequent visits to the London office.
Typical Working Hours Patterns
I work from Monday to Friday, normally starting at X and finishing at X. During school term times, I will be out of the office between 3:00PM and 3:45PM to do school drop-off and pick ups. On Monday to Thursday, I am in a stand-up from X until Y. I will typically take my lunch break between X and Y. On Friday I have a weekly one-to-one which starts at X and finishes at Y. I will then take lunch until 1:00PM.
During school holidays, the start and end times will need to be a bit more flexible, and drop-off and pick-up slots will vary based on day-to-day activities.
I will keep my calendar up-to-date accordingly.
Contact Preference
I prefer being contacted by Slack mention or DM, however, I will often follow-up with a request for a DM chat or call, especially if I have been typing a lot during the day, or am trying to resolve an issue which I expect will require a lot of interaction.
I am happy to use Google Meetings, Slack Huddles, Microsoft Teams or Amazon Chime, all of which I have tested and work on my computer. I personally prefer to use Microsoft Teams because the presenter can allow participants to interact with the presenter’s screen or Slack Huddles because that allows participants to draw on the presenters screen, and because I can see more of your screen by default.
Today I ran terragrunt apply against a IaC directory, and got this response:
╷
│ Error: Backend initialization required: please run "terraform init"
│
│ Reason: Backend configuration block has changed
│
│ The "backend" is the interface that Terraform uses to store state,
│ perform operations, etc. If this message is showing up, it means that the
│ Terraform configuration you're using is using a custom configuration for
│ the Terraform backend.
│
│ Changes to backend configurations require reinitialization. This allows
│ Terraform to set up the new configuration, copy existing state, etc. Please
│ run
│ "terraform init" with either the "-reconfigure" or "-migrate-state" flags
│ to
│ use the current configuration.
│
│ If the change reason above is incorrect, please verify your configuration
│ hasn't changed and try again. At this point, no changes to your existing
│ configuration or state have been made.
╵
ERRO[0000] Hit multiple errors:
Hit multiple errors:
exit status 1
But wait, I hear you say, Terragrunt runs terraform init for you… so what gives?
Well, in this case, the terragrunt.hcl has a dependency block, and one of those dependencies has not run properly, so… let’s fix it
Right, so for some reason the dependency won’t run. Change into that directory, and run terragrunt apply --terragrunt-source-update. Hopefully, you’ll get something like this:
Initializing the backend...
Successfully configured the backend "example"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- Reusing previous version of example/example from the dependency lock file
- Installing example/example v1.0.0...
- Installed example/example v1.0.0 (signed by Example)
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
example_module.this: Refreshing state... [id=an-example]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration
and found no differences, so no changes are needed.
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Outputs:
output_1 = {"some_key": "some_value"}
output_2 = "some_string"
You may find yourself having to traverse several different dependencies until you get to the one which is missing… and then it should work :)
Featured image is “Jenga” by “Mara Tr.” on Flickr and is released under a CC-BY license.