This is the first time I’ve tried to deploy this chart, and I kept getting this message:
No tags generated
Starting test...
Starting deploy...
Helm release {package} not installed. Installing...
Error: INSTALLATION FAILED: failed to authorize: failed to fetch anonymous token: unexpected status from GET request to https://ghcr.io/token?scope=repository%3A{owner}%2F{package}%3Apull&scope=repository%3Auser%2Fimage%3Apull&service=ghcr.io: 403 Forbidden
deploying "{package}": install: exit status 1
I thought this might have been an issue with the skaffold file, so I tried running this directly with helm:
$ helm pull oci://ghcr.io/{owner}/{package}
Error: failed to authorize: failed to fetch anonymous token: unexpected status from GET request to https://ghcr.io/token?scope=repository%3A{owner}%2F{package}%3Apull&scope=repository%3Auser%2Fimage%3Apull&service=ghcr.io: 403 Forbidden
Huh, that looks a bit familiar. I spent a little while checking to see whether this was something at the Kubernetes cluster, or if it was just me, and ended up finding this nugget (thanks to a steer from this post)
[Late edit: 2026-02-09] I noticed that I could just ask gh to tell me what my username was… which makes life just a touch easier! 😀 helm registry login command updated!
I love the tee command – it captures stdout [1] and puts it in a file, while then returning that output to stdout for the next process in a pipe to consume, for example:
$ ls -l | tee /tmp/output
total 1
xrwxrwxrw 1 jonspriggs jonspriggs 0 Jul 27 11:16 build.sh
$ cat /tmp/output
total 1
xrwxrwxrw 1 jonspriggs jonspriggs 0 Jul 27 11:16 build.sh
But wait, why is that useful? Well, in a script, you don’t always want to see the content scrolling past, but in the case of a problem, you might need to catch up with the logs afterwards. Alternatively, you might do something like this:
if some_process | tee /tmp/output | grep -q "some text"
then
echo "Found 'some text' - full output:"
cat /tmp/output
fi
This works great for stdout but what about stderr [2]? In this case you could just do:
some_process 2>&1 | tee /tmp/output
But that mashes all of stdout and stderr into the same blob.
In my case, I want to capture all the output (stdout and stderr) of a given process into a file. Only stdout is forwarded to the next process, but I still wanted to have the option to see stderr as well during processing. Enter process substitution.
With this, I run capture_out step-1 do_a_thing and then in /tmp/tmp.sometext/step-1/stdout and /tmp/tmp.sometext/step-1/stderr are the full outputs I need… but wait, I can also do:
if capture_out has_an_error something-wrong | capture_out handler check_output
then
echo "It all went great"
else
echo "Process failure"
echo "--Initial process"
# Use wc -c to check the number of characters in the file
if [ -e "${TEMP_DATA_PATH}/has_an_error/stdout"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/has_an_error/stdout")" ]
then
echo "----stdout:"
cat "${TEMP_DATA_PATH}/has_an_error/stdout"
fi
if [ -e "${TEMP_DATA_PATH}/has_an_error/stderr"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/has_an_error/stderr")" ]
then
echo "----stderr:"
cat "${TEMP_DATA_PATH}/has_an_error/stderr"
fi
echo "--Second stage"
if [ -e "${TEMP_DATA_PATH}/handler/stdout"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/handler/stdout")" ]
then
echo "----stdout:"
cat "${TEMP_DATA_PATH}/handler/stdout"
fi
if [ -e "${TEMP_DATA_PATH}/handler/stderr"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/handler/stderr")" ]
then
echo "----stderr:"
cat "${TEMP_DATA_PATH}/handler/stderr"
fi
fi
This has become part of my normal toolkit now for logging processes. Thanks bash!
Also, thanks to ChatGPT for helping me find this structure that I’d seen before, but couldn’t remember how to do it! (it almost got it right too! Remember kids, don’t *trust* what ChatGPT gives you, use it as a research starting point, test *that* against your own knowledge, test *that* against your environment and test *that* against expected error cases too! Copy & Paste is not the best idea with AI generated code!)
Footnotes
[1] stdout is the name of the normal output text we see in a shell, it’s also sometimes referred to as “file descriptor 1” or “fd1”. You can also output to &1 with >&1 which means “send to fd1”
[2] stderr is the name of the output in a shell when an error occurs. It isn’t caught by things like some_process > /dev/null which makes it useful when you don’t want to see output, just errors. Like stdout, it’s also referred to as “file descriptor 2” or “fd2” and you can output to &2 with >&2 if you want to send stdout to stderr.
In my current role we are using Packer to build images on a Xen Orchestrator environment, use a CI/CD system to install that image into both a Xen Template and an AWS AMI, and then we use Terraform to use that image across our estate. The images we build with Packer have this stanza in it:
But, because Xen doesn’t track when a template is created, instead I needed to do something different. Enter get_xoa_template.sh.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
[ -z "$TEMPLATE_IS" ] && fail "Could not match this template" 4
if [ -n "$DEBUG" ]
then
echo "{\"is\": ${TEMPLATE_IS}}" | tee -a "$DEBUG"
else
echo "{\"is\": ${TEMPLATE_IS}}"
fi
}
[ -n "$(command -v xo-cli)" ] || fail "xo-cli is missing, and is a required dependency for this script. Please install it; \`sudo npm -g install xo-cli\`" 5
This script is invoked from your terraform like this:
variable "template_name" {
default = "SomeLinux-version.iso-"
description = "A regex, partial or full string to match in the template name"
}
variable "poolname" {
default = "MyPool"
}
data "external" "get_xoa_template" {
program = [
"/bin/bash", "${path.module}/get_xoa_template.sh",
"--template", var.template_name,
"--pool", var.poolname
]
}
data "xenorchestra_pool" "pool" {
name_label = var.poolname
}
data "xenorchestra_template" "template" {
name_label = data.external.get_xoa_template.result.is
pool_id = data.xenorchestra_pool.pool.id
}
And that’s how you do it. Oh, and if you need to pin to a specific version? Change the template_name value from the partial or regex version to the full version, like this:
variable "template_name" {
# This assumes your image was minted at midnight on 1970-01-01
default = "SomeLinux-version.iso-19700101000000"
}
In my current project I am often working with Infrastructure as Code (IoC) in the form of Terraform and Terragrunt files. Before I joined the team a decision was made to use SOPS from Mozilla, and this is encrypted with an AWS KMS key. You can only access specific roles using the SAML2AWS credentials, and I won’t be explaining how to set that part up, as that is highly dependant on your SAML provider.
While much of our environment uses AWS, we do have a small presence hosted on-prem, using a hypervisor service. I’ll demonstrate this with Proxmox, as this is something that I also use personally :)
Firstly, make sure you have all of the above tools installed! For one stage, you’ll also require yq to be installed. Ensure you’ve got your shell hook setup for direnv as we’ll need this later too.
Late edit 2023-07-03: There was a bug in v0.22.0 of the terraform which didn’t recognise the environment variables prefixed PROXMOX_VE_ – a workaround by using TF_VAR_PROXMOX_VE and a variable "PROXMOX_VE_" {} block in the Terraform code was put in place for the inital publication of this post. The bug was fixed in 0.23.0 which this post now uses instead, and so as a result the use of TF_VAR_ prefixed variables was removed too.
Set up AWS Vault
AWS KMS
AWS Key Management Service (KMS) is a service which generates and makes available encryption keys, backed by the AWS service. There are *lots* of ways to cut that particular cake, but let’s do this a quick and easy way… terraform
So far, so good… but wait, you’ve authenticated to your SAML access to AWS. Let’s close that shell, and go back in again
$ cd /path/to/demo
direnv: loading /path/to/demo/.envrc
direnv: using sops
$
Ah, now we don’t have our values exported. That’s what we wanted!
What now?!
Configuring the details of the proxmox cluster
We have our .envrc file which provides our credentials (let’s pretend we’re using a shared set of credentials across all the boxes), but now we need to setup access to each of the boxes.
Let’s make our two cluster directories;
mkdir cluster_01
mkdir cluster_02
And in each of these clusters, we need to put an .envrc file with the right IP address in. This needs to check up the tree for any credentials we may have already loaded:
source_env "$(find_up ../.envrc)"
export PROXMOX_VE_ENDPOINT="https://192.0.2.1:8006" # Documentation IP address for the first cluster - change for the second cluster.
The first line works up the tree, looking for a parent .envrc file to inject, and then, with the second line, adds the Proxmox API endpoint to the end of that chain. When we run direnv allow (having logged back into our saml2aws session), we get this:
Then in the cluster_01 directory, create a directory for the code you want to run (e.g. create a VLAN might be called “VLANs/30/“) and put in it this terragrunt.hcl
This assumes you have a terraform directory called terraform-module-network/vlan in a particular place in your tree or even better, a module in your git repo, which uses the input values you’ve provided.
That double slash in the source line isn’t a typo either – this is the point in that tree that Terragrunt will copy into the directory to run terraform from too.
A quick note about includes and provider blocks
The other key thing is that the “include” block loads the values from the first matching terragrunt.hcl file in the parent directories, which in this case is the one which defined the providers block. You can’t include multiple different parent files, and you can’t have multiple generate blocks either.
Running it all together!
Now we have all our depending files, let’s run it!
user@host:~$ cd test
direnv: loading ~/test/.envrc
direnv: using sops
user@host:~/test$ saml2aws login --skip-prompt --quiet ; saml2aws exec -- bash
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test$ cd cluster_01/VLANs/30
direnv: loading ~/test/cluster_01/.envrc
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_ENDPOINT +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test/cluster_01/VLANs/30$ terragrunt apply
data.proxmox_virtual_environment_nodes.available_nodes: Reading...
data.proxmox_virtual_environment_nodes.available_nodes: Read complete after 0s [id=nodes]
Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# proxmox_virtual_environment_network_linux_bridge.this[0] will be created
+ resource "proxmox_virtual_environment_network_linux_bridge" "this" {
+ autostart = true
+ comment = "VLAN30"
+ id = (known after apply)
+ mtu = (known after apply)
+ name = "vmbr30"
+ node_name = "proxmox01"
+ ports = [
+ "enp3s0.30",
]
+ vlan_aware = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
proxmox_virtual_environment_network_linux_bridge.this[0]: Creating...
proxmox_virtual_environment_network_linux_bridge.this[0]: Creation complete after 2s [id=proxmox01:vmbr30]
user@host:~/test/cluster_01/VLANs/30$
I’ve recently been working with a network estate that was a bit hard to get a handle on. It had grown organically, and was a bit tricky to allocate new network segments in. To fix this, I deployed PHPIPAM, which was super easy to setup and configure (I used the docker-compose file on the project’s docker hub page, and put it behind an NGINX server which was pre-configured with a LetsEncrypt TLS/HTTPS certificate).
PHPIPAM is a IP Address Management tool which is self-hostable. I started by setting up the “Sections” (which was the hosting environments the estate is using), and then setup the supernets and subnets in the “Subnets” section.
Already, it was much easier to understand the network topology, but now I needed to get others in to take a look at the outcome. The team I’m working with uses a slightly dated version of Keycloak to provide Single Sign-On. PHPIPAM will use SAML for authentication, which is one of the protocols that Keycloak offers. The documentation failed me a bit at this point, but fortunately a well placed ticket helped me move it along.
Setting up Keycloak
Here’s my walk through
Go to “Realm Settings” in the sidebar and find the “SAML Identity Provider Metadata” (on my system it’s on the “General” tab but it might have changed position on your system). This will be an XML file, and (probably) the largest block of continuous text will be in a section marked “ds:X509Certificate” – copy this text, and you’ll need to use this as the “IDP X.509 public cert” in PHPIPAM.
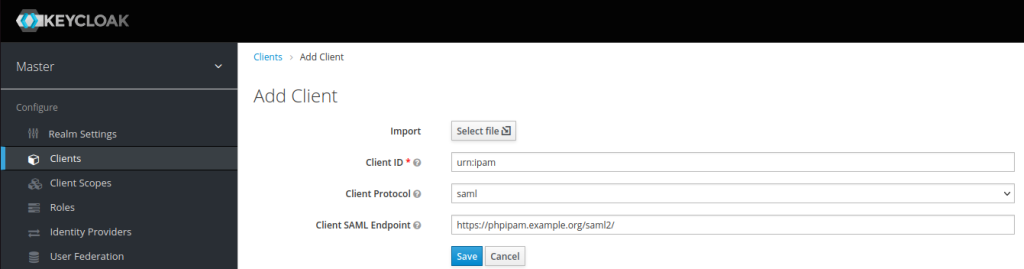
Go to “Clients” in the sidebar and click “Create”. If you want Keycloak to offer access to PHPIPAM as a link, the client ID needs to start “urn:” If you just want to use the PHPIPAM login option, give the client ID whatever you want it to be (I’ve seen some people putting in the URL of the server at this point). Either way, this needs to be unique. The client protocol is “saml” and the client SAML endpoint is the URL that you will be signing into on PHPIPAM – in my case https://phpipam.example.org/saml2/. It should look like this: Click Save to take you to the settings for this client.
If you want Keycloak to offer a sign-in button, set the name of the button and description.
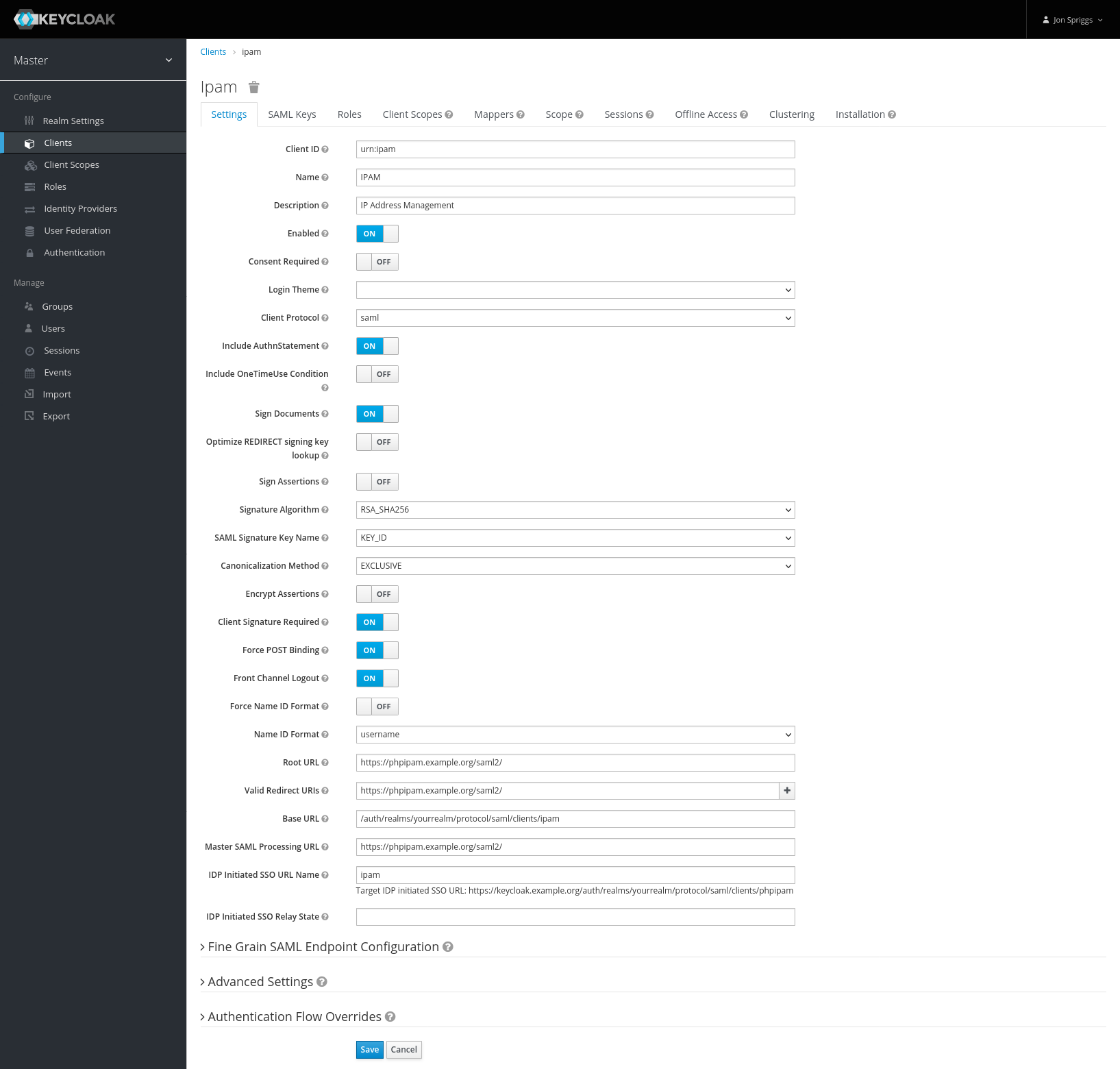
Further down the page is “Root URL” set that to the SAML Endpoint (the one ending /saml2/ from before). Also set the “Valid Redirect URIs” to that too.
Where it says “IDP Initiated SSO URL Name” put a string that will identify the client – I put phpipam, but it can be anything you want. This will populate a URL like this: https://keycloak.example.org/auth/realms/yourrealm/protocol/saml/clients/phpipam, which you’ll need as the “IDP Issuer”, “IDP Login URL” and “IDP Logout URL”. Put everything after the /auth/ in the box marked “Base URL”. It should look like this: Hit Save.
Go to the “SAML Keys” tab. Copy the private key and certificate, these are needed as the “Authn X.509 signing” cert and cert key in PHPIPAM.
Go to the “Mappers” tab. Create each of the following mappers;
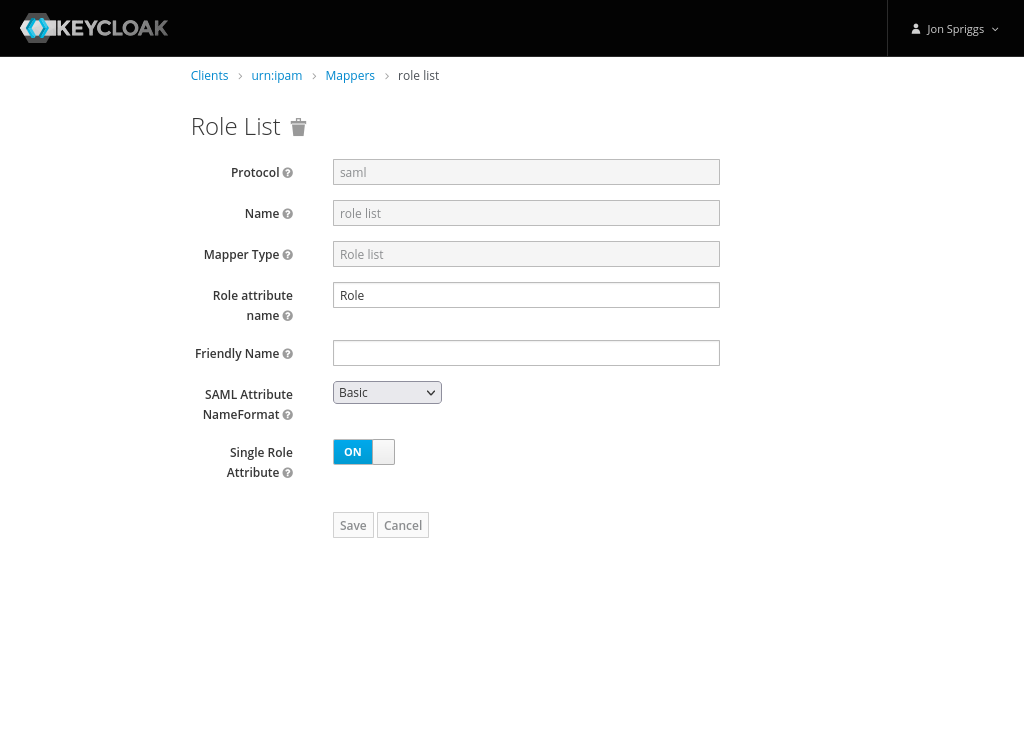
A Role List mapper, with the name of “role list”, Role Attribute Name of “Role”, no friendly name, the SAML Attribute NameFormat set to “Basic” and Single Role Attribute set to on.
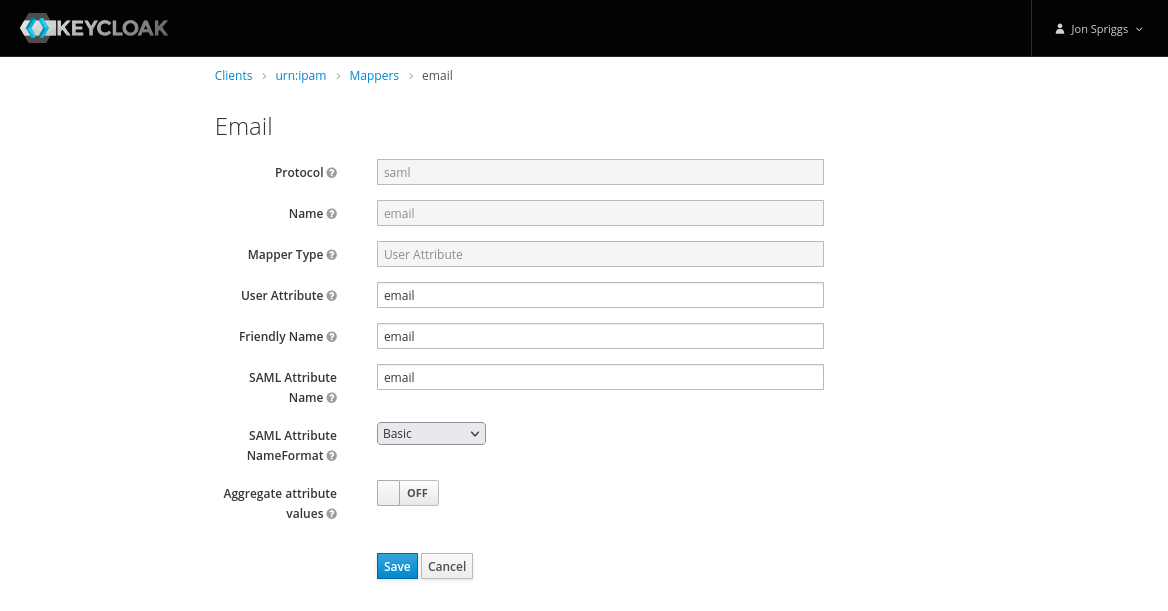
A User Attribute mapper, with the name, User Attribute, Friendly Name and SAML Attribute Name set to “email”, the SAML Attribute NameFormat set to “Basic” and Aggregate Attribute Values set to “off”.
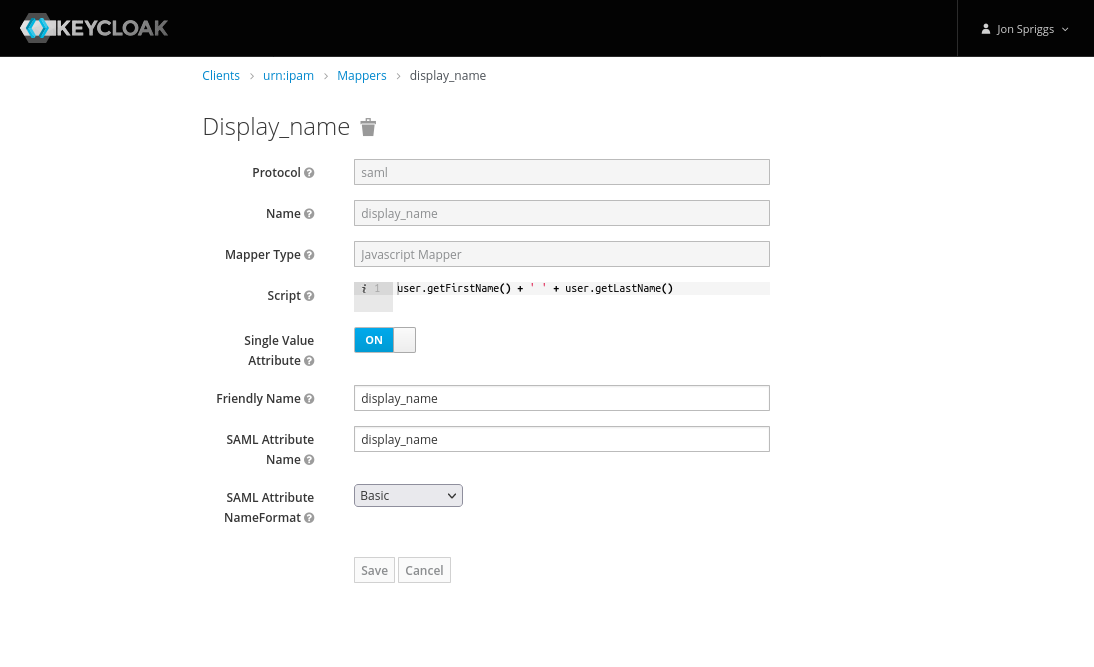
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “display_name” and the SAML Attribute NameFormat set to “Basic”. The Script should be set to this single line: user.getFirstName() + ' ' + user.getLastName().
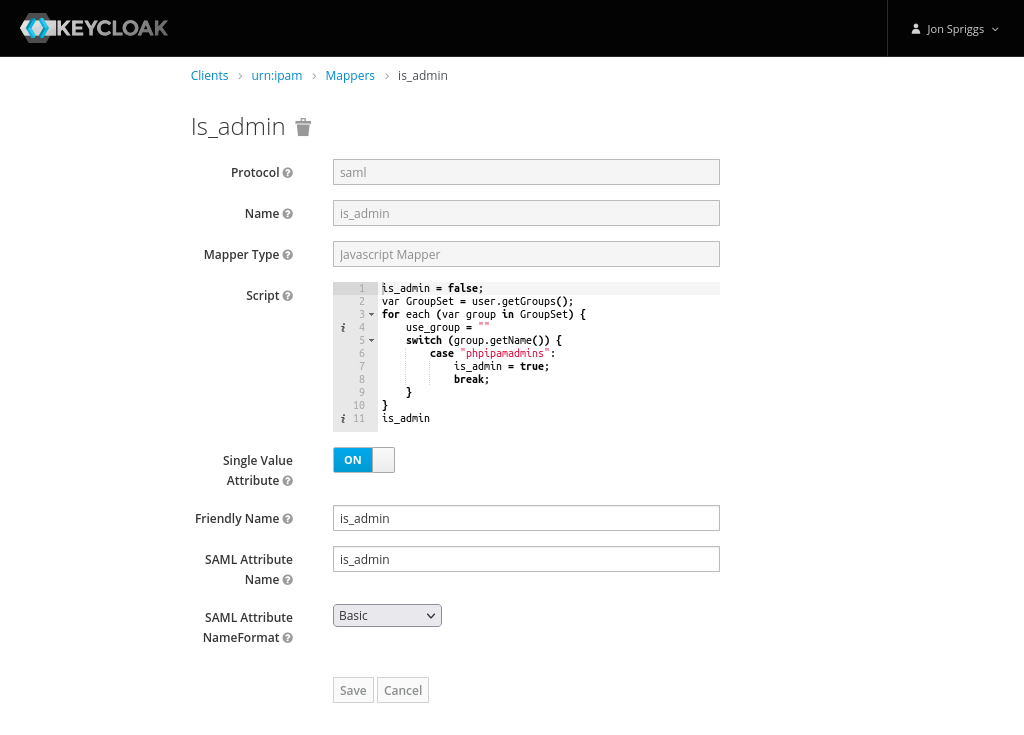
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “is_admin” and the SAML Attribute NameFormat set to “Basic”.
The script should be as follows:
is_admin = false;
var GroupSet = user.getGroups();
for each (var group in GroupSet) {
use_group = ""
switch (group.getName()) {
case "phpipamadmins":
is_admin = true;
break;
}
}
is_admin
Create one more mapper item:
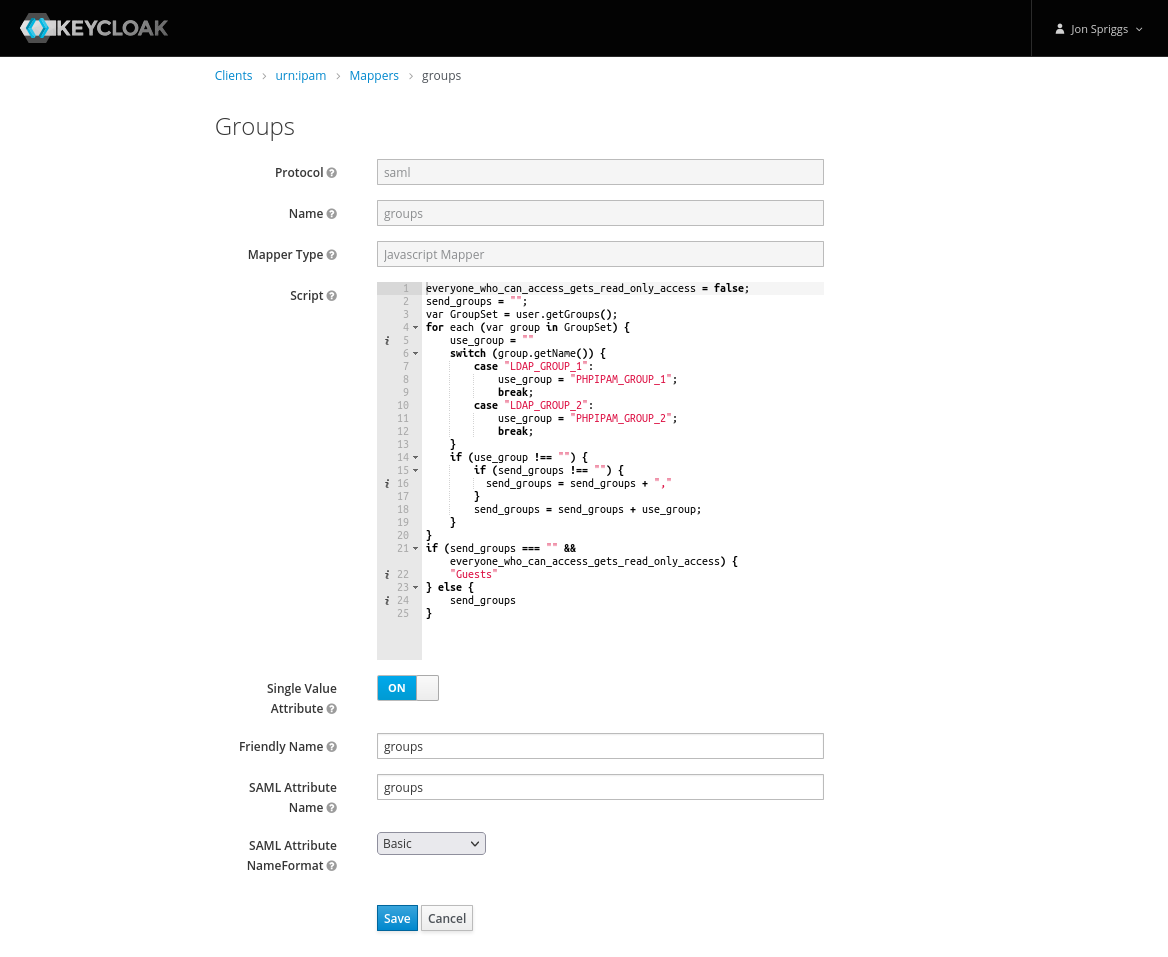
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “groups” and the SAML Attribute NameFormat set to “Basic”. The script should be as follows:
everyone_who_can_access_gets_read_only_access = false;
send_groups = "";
var GroupSet = user.getGroups();
for each (var group in GroupSet) {
use_group = ""
switch (group.getName()) {
case "LDAP_GROUP_1":
use_group = "IPAM_GROUP_1";
break;
case "LDAP_GROUP_2":
use_group = "IPAM_GROUP_2";
break;
}
if (use_group !== "") {
if (send_groups !== "") {
send_groups = send_groups + ","
}
send_groups = send_groups + use_group;
}
}
if (send_groups === "" && everyone_who_can_access_gets_read_only_access) {
"Guests"
} else {
send_groups
}
For context, the groups listed there, LDAP_GROUP_1 might be “Customer 1 Support Staff” or “ITSupport” or “Networks”, and the IPAM_GROUP_1 might be “Customer 1” or “WAN Links” or “DC Patching” – depending on the roles and functions of the teams. In my case they relate to other roles assigned to the staff member and the name of the role those people will perform in PHP IPAM. Likewise in the is_admin mapper, I’ve mentioned a group called “phpipamadmins” but this could be any relevant role that might grant someone admin access to PHPIPAM.
Late Update (2023-06-07): I’ve figured out how to enable modules now too. Create a Javascript mapper as per above, but named “modules” and have this script in it:
// Current modules as at 2023-06-07
// Some default values are set here.
noaccess = 0;
readonly = 1;
readwrite = 2;
readwriteadmin = 3;
unsetperm = -1;
var modules = {
"*": readonly, "vlan": unsetperm, "l2dom": unsetperm,
"devices": unsetperm, "racks": unsetperm, "circuits": unsetperm,
"nat": unsetperm, "locations": noaccess, "routing": unsetperm,
"pdns": unsetperm, "customers": unsetperm
}
function updateModules(modules, new_value, list_of_modules) {
for (var module in list_of_modules) {
modules[module] = new_value;
}
return modules;
}
var GroupSet = user.getGroups();
for (var group in GroupSet) {
switch (group.getName()) {
case "LDAP_ROLE_3":
modules = updateModules(modules, readwriteadmin, [
'racks', 'devices', 'nat', 'routing'
]);
break;
}
}
var moduleList = '';
for (var key in modules) {
if (modules.hasOwnProperty(key) && modules[key] !==-1) {
if (moduleList !== '') {
moduleList += ',';
}
moduleList += key + ':' + modules[key];
}
}
moduleList;
OK, that’s Keycloak sorted. Let’s move on to PHPIPAM.
Setting up PHPIPAM
In the administration menu, select “Authentication Methods” and then “Create New” and select “Create new SAML2 authentication”.
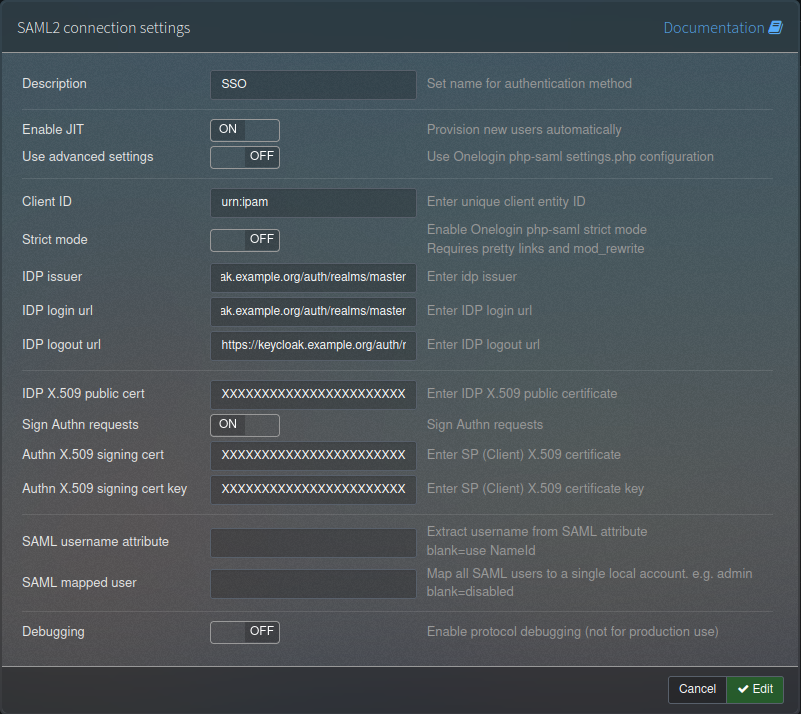
In the description field, give it a relevant name, I chose SSO, but you could call it any SSO system name. Set “Enable JIT” to “on”, leave “Use advanced settings” as “off”. In Client ID put the Client ID you defined in Keycloak, probably starting urn: or https://. Leave “Strict mode” off. Next is the IDP Issuer, IDP Login URL and IDP Logout URL, which should all be set to the same URL – the “IDP Initiated SSO URL Name” from step 4 of the Keycloak side (that was set to something like https://keycloak.example.org/auth/realms/yourrealm/protocol/saml/clients/phpipam).
After that is the certificate section – first the IDP X.509 public cert that we got in step 1, then the “Sign Authn requests” should be set to “On” and the Authn X.509 signing cert and cert key are the private key and certificate we retrieved in step 5 above. Leave “SAML username attribute” and “SAML mapped user” blank and “Debugging” set to “Off”. It should look like this:
Hit save.
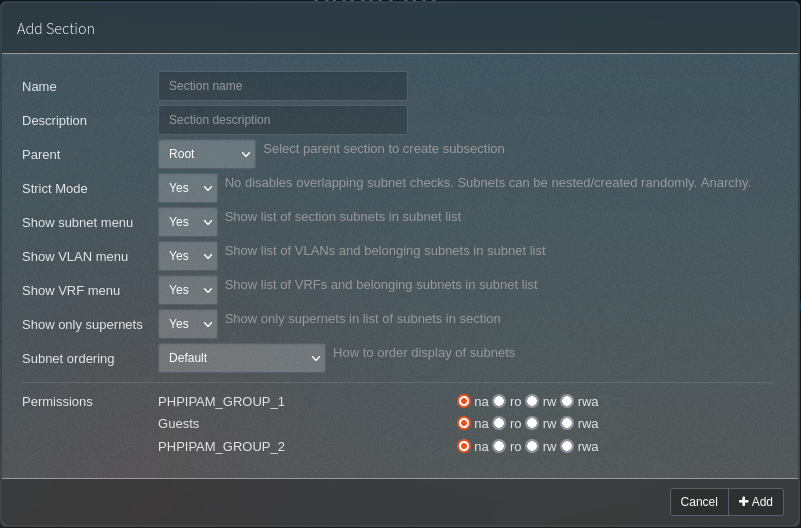
Next, any groups you specified in the groups mapper need to be defined. This is in Administration -> Groups. Create the group name and set a description.
Lastly, you need to configure the sections to define whigh groups have access. Each defined group gets given four radio buttons; “na” (no access), “ro” (read only), “rw” (read write) and “rwa” (read, write and administrate).
Try logging in. It should just work!
Debugging
If it doesn’t, and checking all of the above doesn’t help, I’ve tried adding some code into the PHP file in app/saml2/index.php, currently on line 149, above where it says:
**REMEMBER THIS IS JUST FOR TESTING PURPOSES AND SHOULD BE REMOVED ASAP**
In here is an array called _attributes which will show you what has been returned from the Keycloak server when someone tries to log in. In my case, I got this:
I’m working on another toy project to understand a piece of software a little better, and to make it work, I needed to install dnsmasq inside an Ubuntu-based virtual machine. The problem with this is that Ubuntu already runs systemd-resolved to perform DNS lookups, and Debian likes to start server services as soon as it’s installed them. So how do we work around this? Well, actually, it’s pretty simple.
Thanks to this blog post from 2013, I found out that if you create an executable script called /usr/sbin/policy-rc.d with the content:
exit 101
This will stop all services in the dpkg/apt process from running on install, so I was able to do this:
Don’t do this! Turns out I was doing this wrong. The below code is only needed if you’ve got things wrong, and you should instead be using keep_vm = "on_success". The more you know, eh?
If you’ve got a command in your packer script that looks like this:
This will force packer to execute a command which is pushed into the background, returning a return code (RC) of 0, which the system will interpret as a successful result. 5 seconds later the machine will shut itself down by itself.
You’re probably in the install image which hasn’t been chrooted into.
You see, when AlmaLinux 9 does it’s install from ISO, it formats the disk and mounts it to /mnt/sysroot and then copies files to it. Once it’s done, the rest of the packer scripts can be run… but commands are run in the install environment, not the chroot container, so, to transfer files in, or to execute commands that will have actions in the target environment, format them like this:
I’ve just finished what felt like the worlds longest work instruction, and it made me think… I’ve got these great tools at my disposal for when I’m writing documentation – perhaps not everyone knows about them!?
So here are the main ones!
Open Broadcaster Software (OBS) Studio
OBS Studio is a screen recording application, most commonly used by eSports players and gamers to stream content to streaming platforms like Twitch. While it’s really easy to do stuff like “lower third” bars (like this)
It’s also really *really* easy to just record a screen, which makes it easy to just “set and forget” and then run through the tasks. In the past, I’ve been on highly-technical in-person training courses and run OBS while I’ve been in a room, just to make sure I didn’t miss any details when I went back over my notes later!
Clicking “Start Recording” in the bottom third of that screen starts writing the content of that screen into (by default) a MKV file in your home directory (on Linux), or into your Videos directory on Windows. I don’t recall where it went on OS X!
This means after the task is done, I can play it back with…
VideoLan Client (VLC)
VLC is (or, at least, was) the defacto video player for anyone who consumes media on their computer. In my case, I only really use it now for playing back files I’ve recorded with OBS, but it’s a great player.
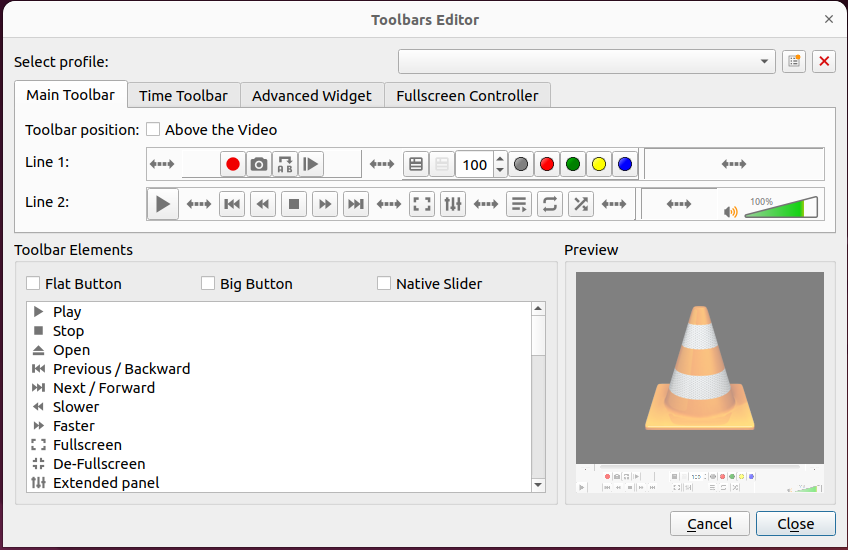
I only really make one key change to VLC, which is; adding the playback speed buttons. Different platforms do it differently, but on Linux and Windows at least, go to Tools -> Customise Interface and you’re presented with a screen like this:
I drag the “Slower” and “Faster” buttons to either side of the stop button, and will typically play videos back at 3x or even 8x speed to get to the areas I want, and then slow it down, sometimes, to 0.5x speed to get specific frames I’m looking for.
Once I get that frame, I’ll use a…
Screen Snipping Tool
On Windows this is the built-in snipping tool, found by pressing Windows+Shift+S. On Ubuntu, I’ve installed the package gnome-screenshot and the Gnome Extension Screenshot Tool.
With Snipping Tool you can draw circles around things and make annotations with a pen, but in extreme cases, I rely on the …
GNU Image Manipulation Program (GIMP).
GIMP, aside from being a badly named project (notably because most people over a certain age know about that scene from Pulp Fiction) is a FANTASTIC image editor. I use it for all sorts of editing, cropping and resizing, but I particularly love the layers menu on the side.
A couple of years ago my son wanted to give all his friends “membership cards” for a club he’d made. These were created in GIMP and just required him to clone a layer from the block on the right, hide the previous layer, and change the text in the clone.
This also means that if you want to easily highlight specific areas of the screen it’s only a few clicks to do it. Now, that said, it’s not as straightforward as Paint, and for anything beyond easy tweaks it will take a bit of experience, but it works.
This is all well and good, but sometimes you just need details from a terminal, where I’d use…
Asciinema
I use Asciinema (just a pip, apt or rpm away) when I’m working on something on a command line that I want to play back as a video, and the main reason is that I can adjust my output really quickly and easily!
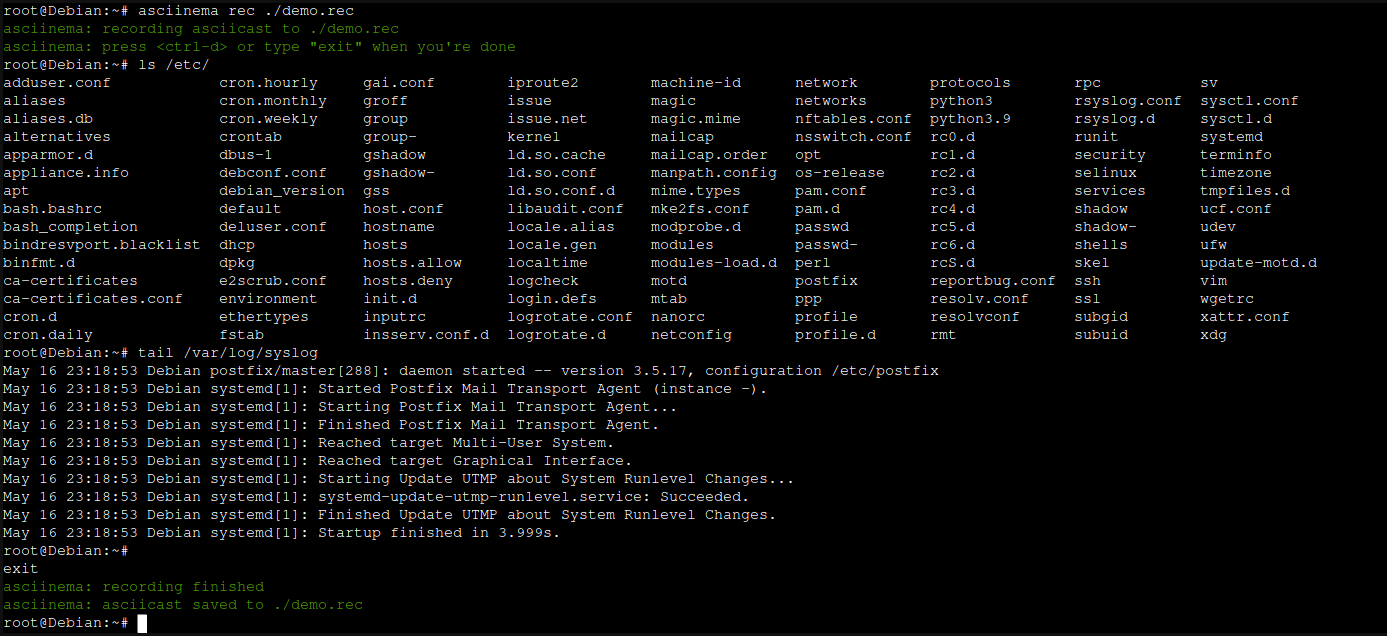
Consider this screen of data:
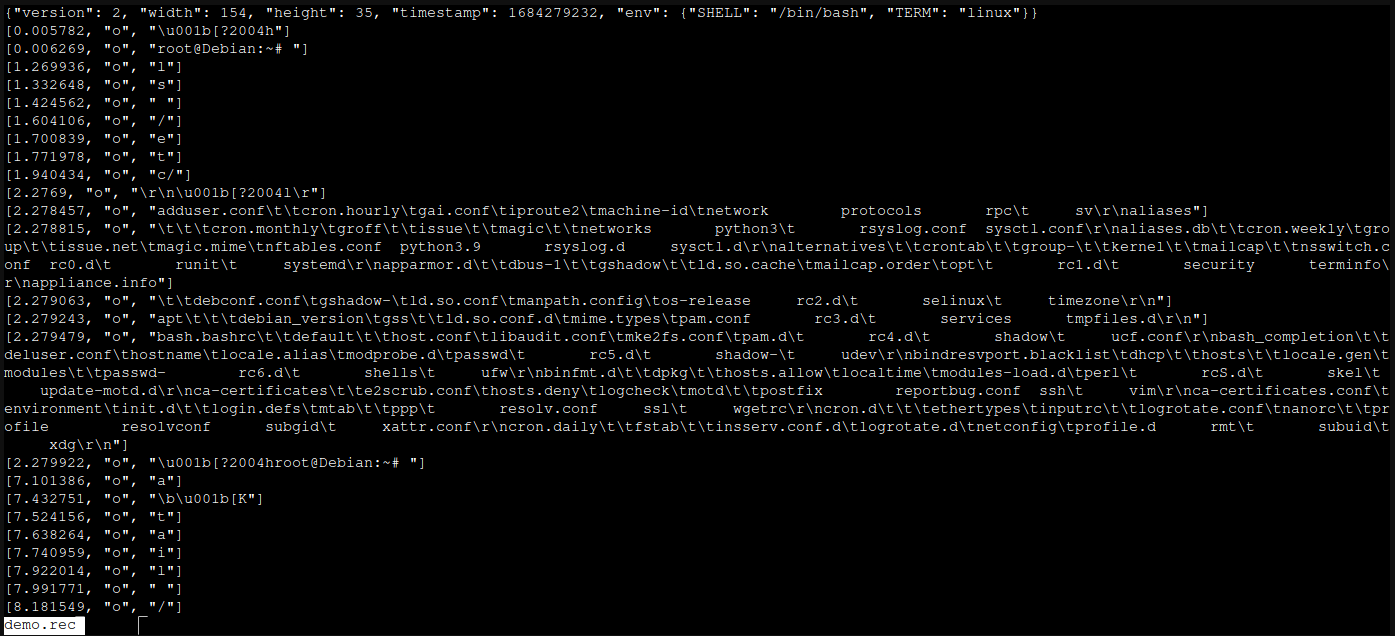
I “recorded” that using asciinema rec ./demo.rec and ended it with ctrl+d. That created a file called demo.rec, which looks like this:
Each line is prefixed with a timestamp, it then has a stream action (mostly o for “output”, but you can add m for “marker” or i for “input” in there if you wanted to be clever ;) ) and then the text which will be rendered when it’s played back (more about that in a tic). This means that if you make a drastic typo, you can fix it in this file, or if you want to redact a password that you never meant to type, you can do!
But, and here’s the next awesome thing, you can also ask it to play back ignoring any gaps longer than X amount of fractions of a second, so if you went off to make a coffee in the middle of doing a recording, playback won’t show it.
And then, playing it back… well, you can just run asciinema play demo.rec but that’s a bit boring… but you can link to it, like this demo I created a while ago or even embed it in your own site
Rendering it all
And the last thing I use? Whatever writing tool I have to hand! I typically write on my blog if it’s for public consumption (like this), but I’ve used private Github and gitlab repos, Visual Studio Code to create markdown files, Google Docs, Microsoft Word, LibreOffice Writer and even slide decks if it’s the right tool for the job.
But the most important thing is that you get your documentation OUT THERE! It’s so frustrating only having half a story… like this one:
Featured image is “Tools” by “Paul Downey” on Flickr and is released under a CC-BY license.
That said, If you’re thinking of getting started with Proxmox though it’s well worth a read. If you’ve *used* Proxmox, and think I’m doing something wrong here, let me know in the comments!
Context
In the various podcasts I listen to, I’ve been hearing over and over again about Proxmox, and how it’s a great system for building and running virtual machines. In a former life, I’d use a combination of VMWare ESXi servers or desktop machines running Vagrant and Virtualbox to build out small labs and build environments, and at home I’d previously used a i3 ex-demo machine that was resold to staff at a reduced price. Unfortunately, the power supply went pop one evening on that, and all my home-lab experiments died.
When I changed to my most recent job, I had a small cash windfall at the same time, and decided to rebuild my home lab. I bought two Dell Optiplex 3040M i5 with 16GB RAM and two 3TB external USB3 hard drives to provide storage. These were selected because of the small size which meant they would fit in the small comms rack I had fitted when I got my house wired with CAT6 networking cables last year. These were patched into the UniFi USW-Pro-24 which was fitted as part of the networking build.
(Yes, it’s a bit of a mess, but it’s also not been in there very long, so needs a bit of a clean-up!)
The Install
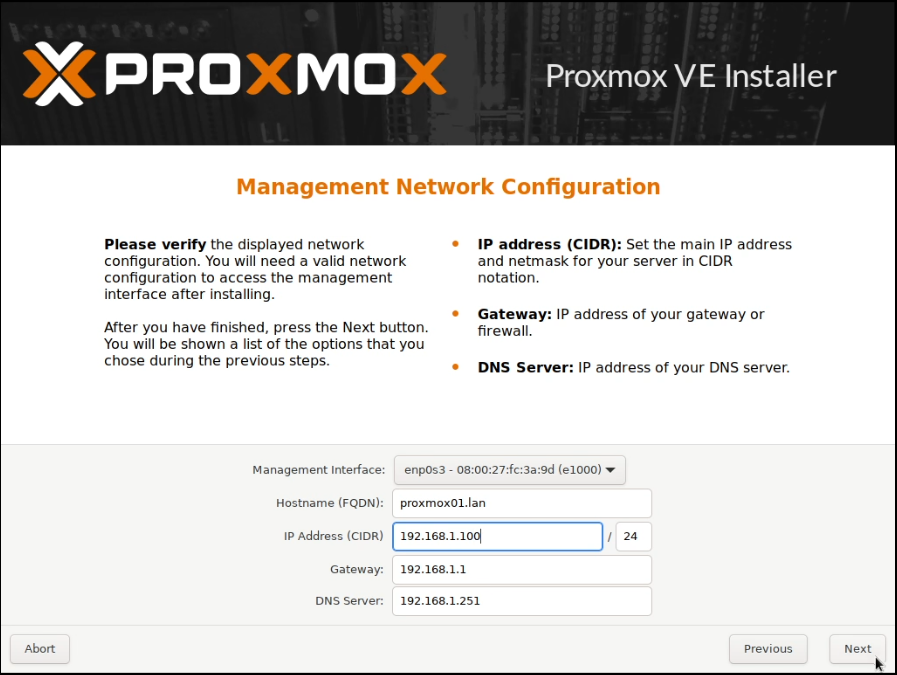
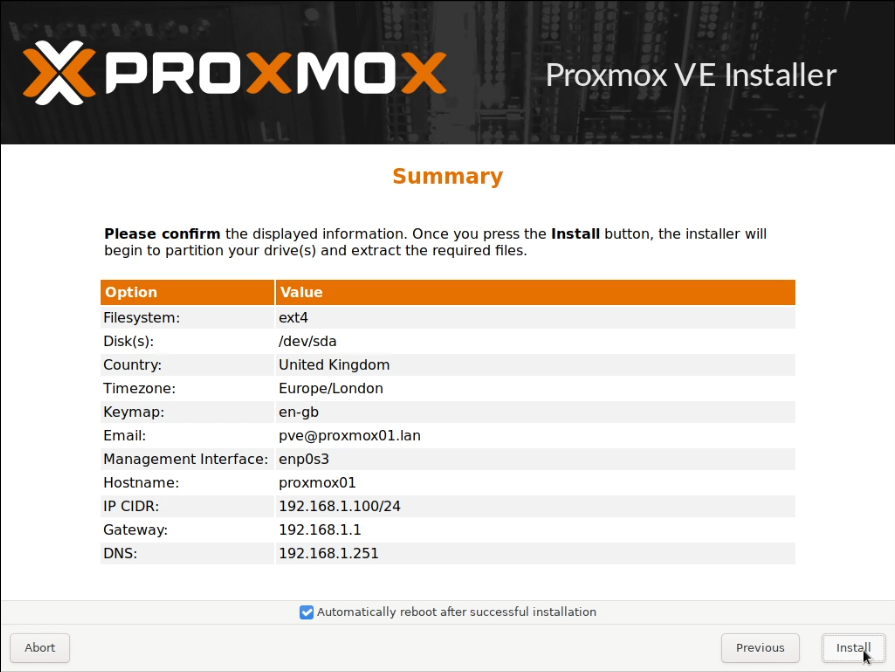
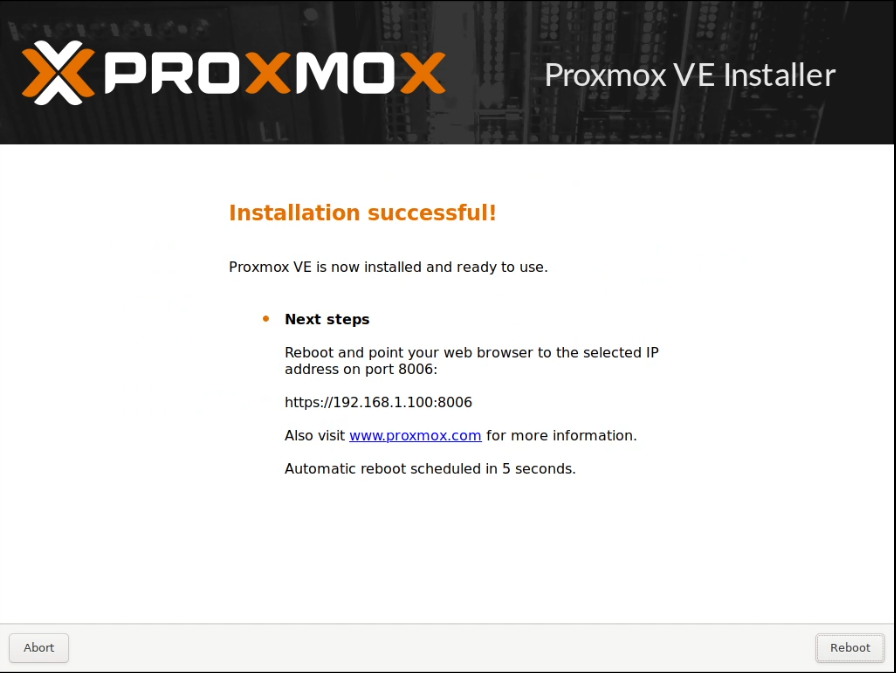
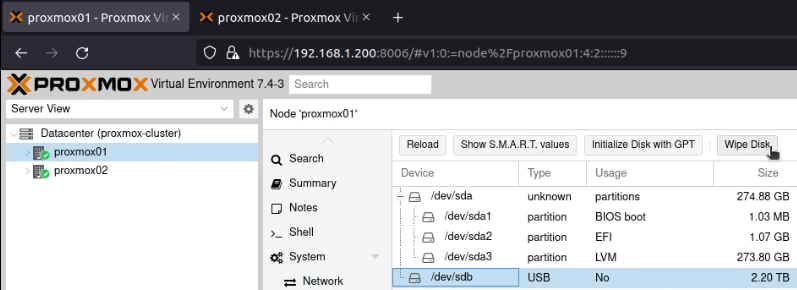
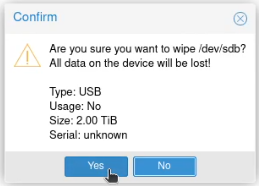
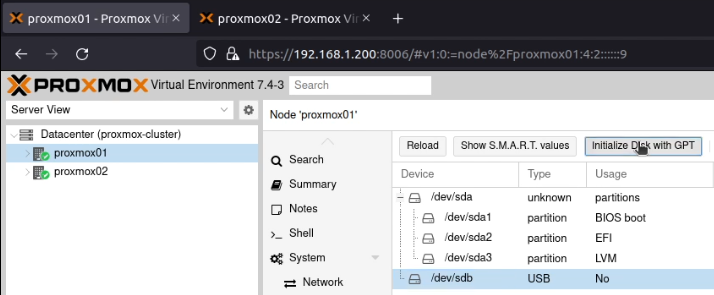
I allocated two static IP addresses for these hosts, and performed a standard installation of Proxmox using a USB stick with the multi-image-installer Ventoy on it.
Some screenshots follow:
Note that these screenshots were built on one pass, and have been rebuilt with new IPs that are used later.
As I don’t have an enterprise subscription, I ran these commands to use tteck’sPost PVE Install script to change the repositories.
wget https://raw.githubusercontent.com/tteck/Proxmox/main/misc/post-pve-install.sh
# Run the following to confirm the download looks OK and non-corrupted
less post-pve-install.sh
bash post-pve-install.sh
This results in the following (time-lapse) output, which is a series of options asking you to approve making changes to the system.
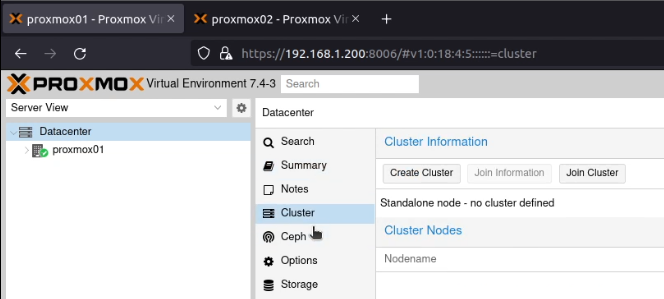
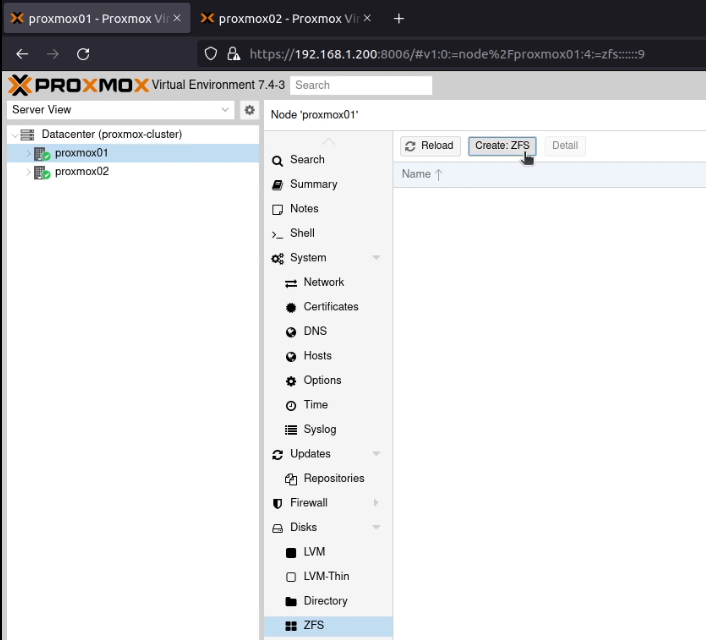
After signing into both Proxmox nodes, I went to my first node (proxmox01), selected “Datacenter” and then “Cluster”.
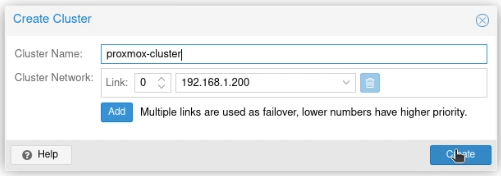
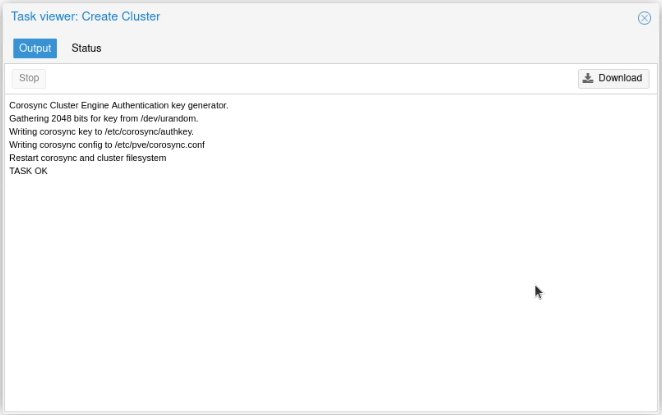
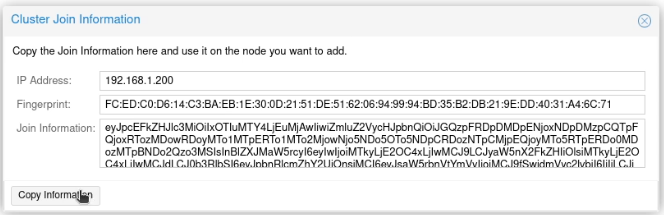
I clicked on “Create Cluster”, and created a cluster, called (unimaginatively) proxmox-cluster.
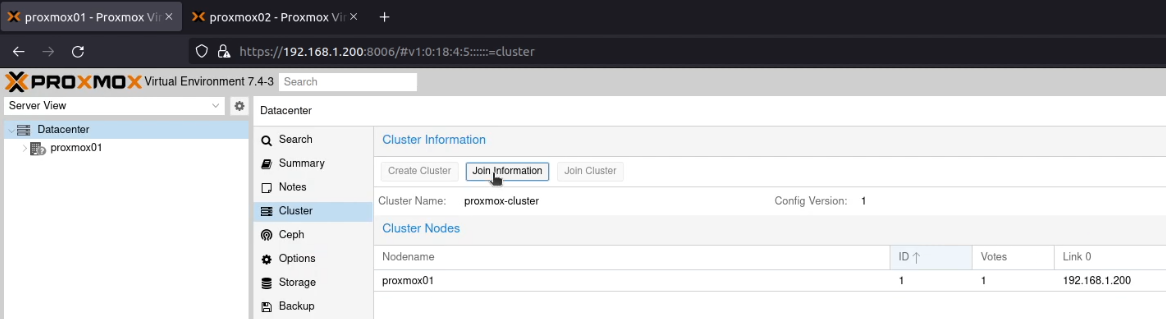
I clicked “Join Information”.
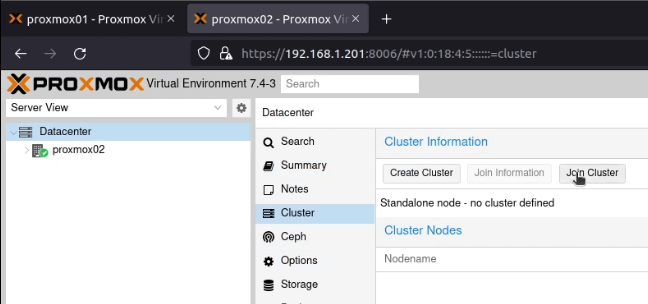
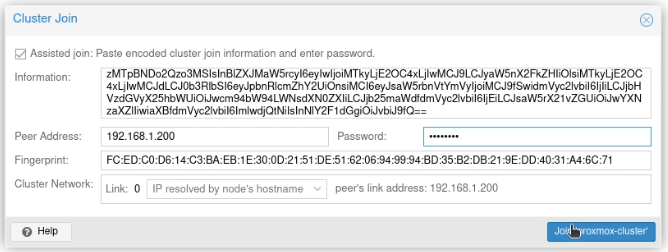
Next, on proxmox02 on the same screen, I clicked on “Join Cluster” and then pasted that information into the dialogue box. I entered the root password, and clicked “Join ‘proxmox-cluster'”.
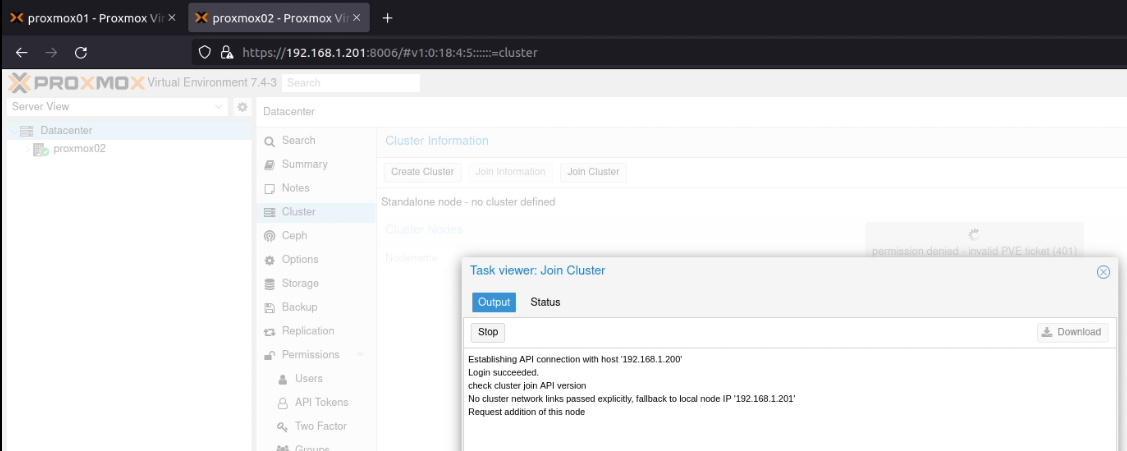
When this finished running, if either screen has hung, check whether one of the screens is showing an error like permission denied - invalid PVE ticket (401), like this (hidden just behind the “Task Viewer: Join Cluster” dialogue box):
Or /etc/pve/nodes/NODENAME/pve-ssl.pem' does not exist! (500):
Refresh your browsers, and you’ll probably find that the joining node will present a new TLS certificate:
Accept the certificate to resume the process.
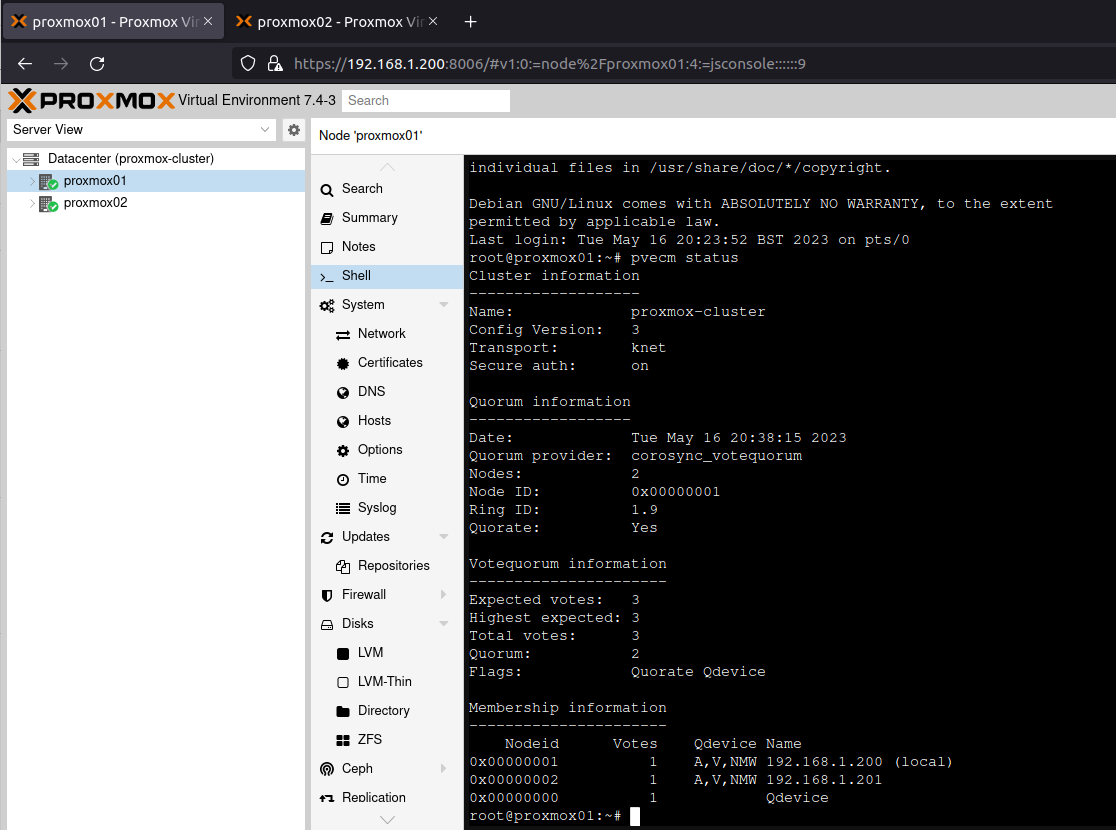
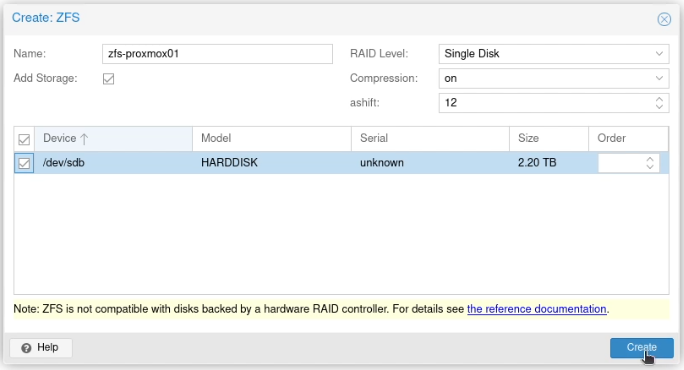
To ensure I had HA quorum, which requires three nodes, I added an unused Raspberry Pi 3 running Raspberry Pi OS.
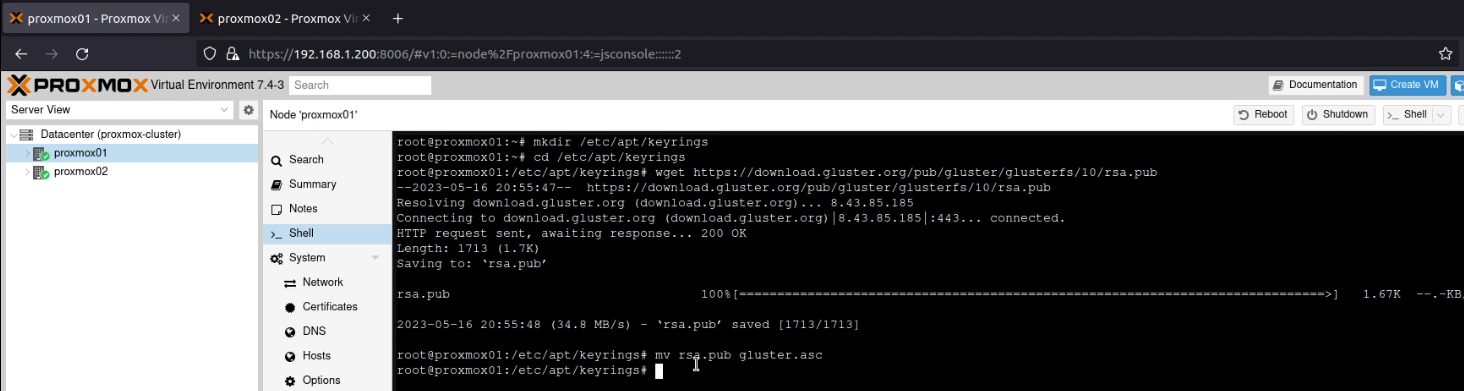
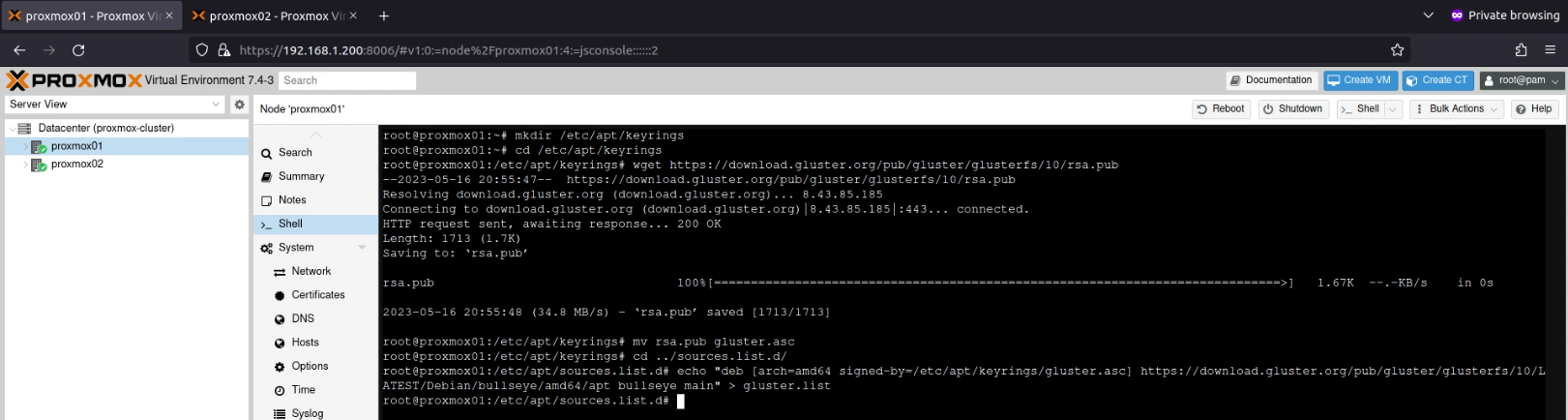
mkdir /etc/apt/keyrings
cd /etc/apt/keyrings
wget https://download.gluster.org/pub/gluster/glusterfs/10/rsa.pub
mv rsa.pub gluster.asc
Next I created a new repository entry in /etc/apt/sources.list.d/gluster.listwhich contained the line:
deb [arch=amd64 signed-by=/etc/apt/keyrings/gluster.asc] https://download.gluster.org/pub/gluster/glusterfs/10/LATEST/Debian/bullseye/amd64/apt bullseye main
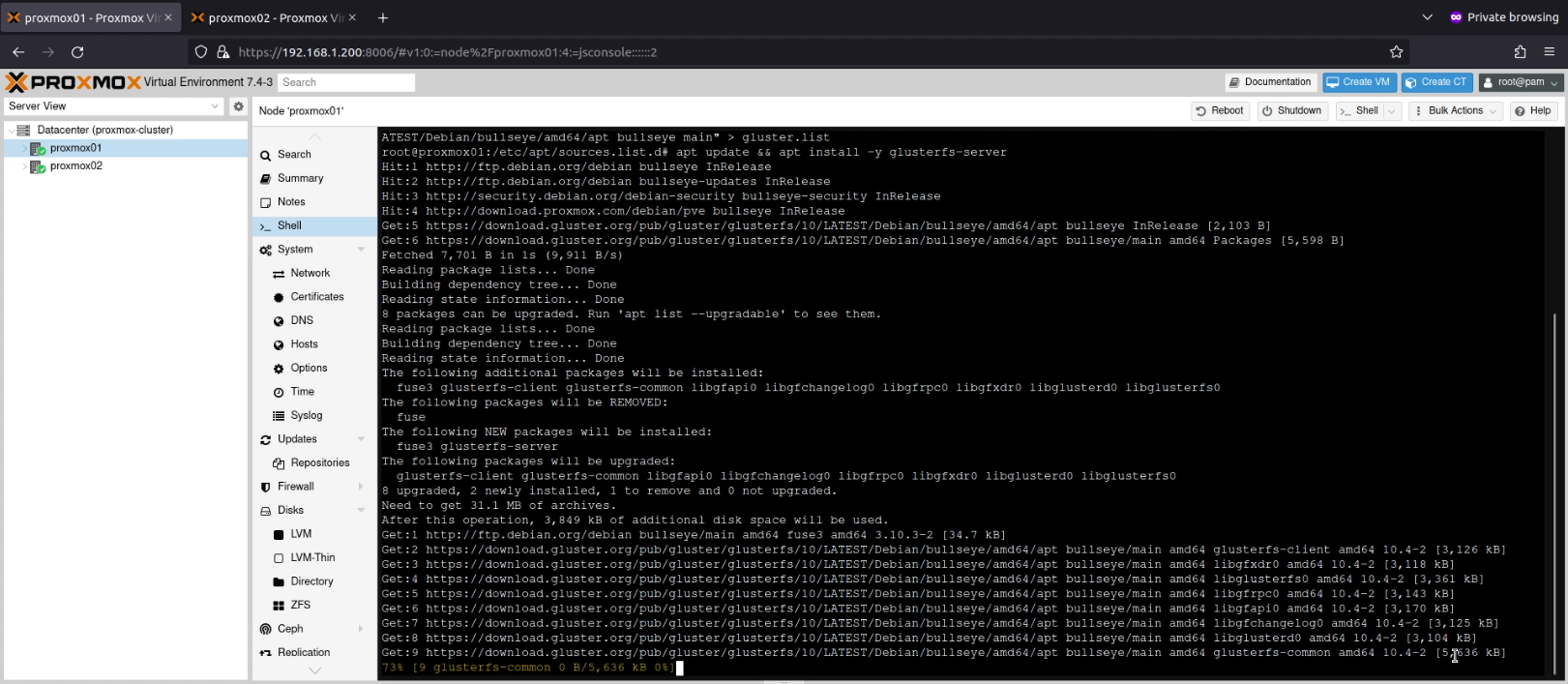
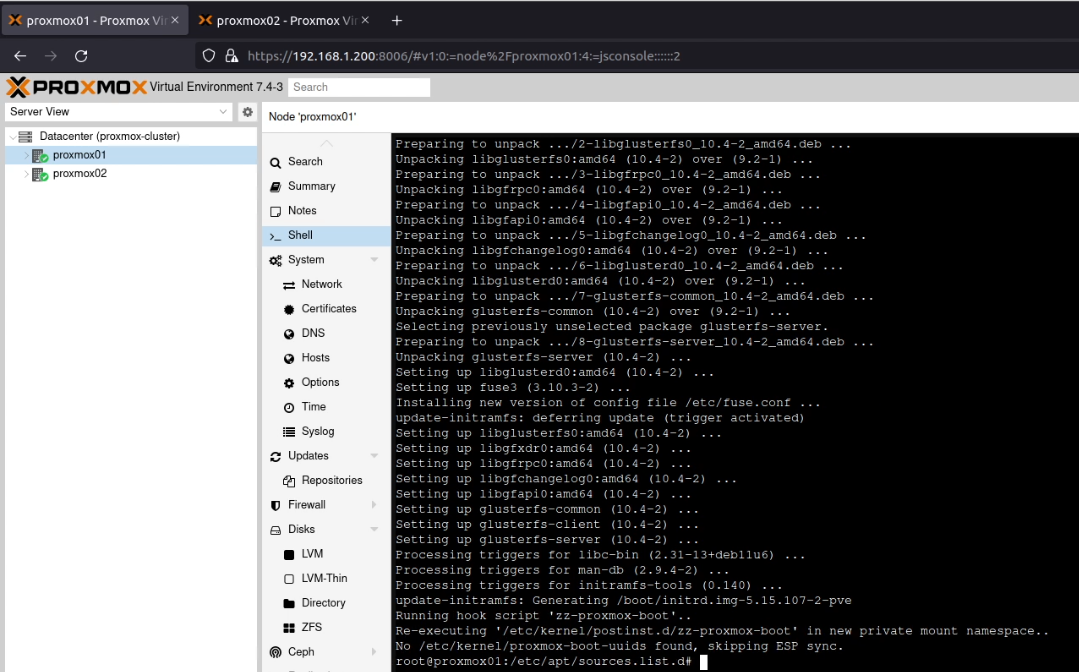
I next ran apt update && apt install -y glusterfs-serverwhich installed the Gluster service.
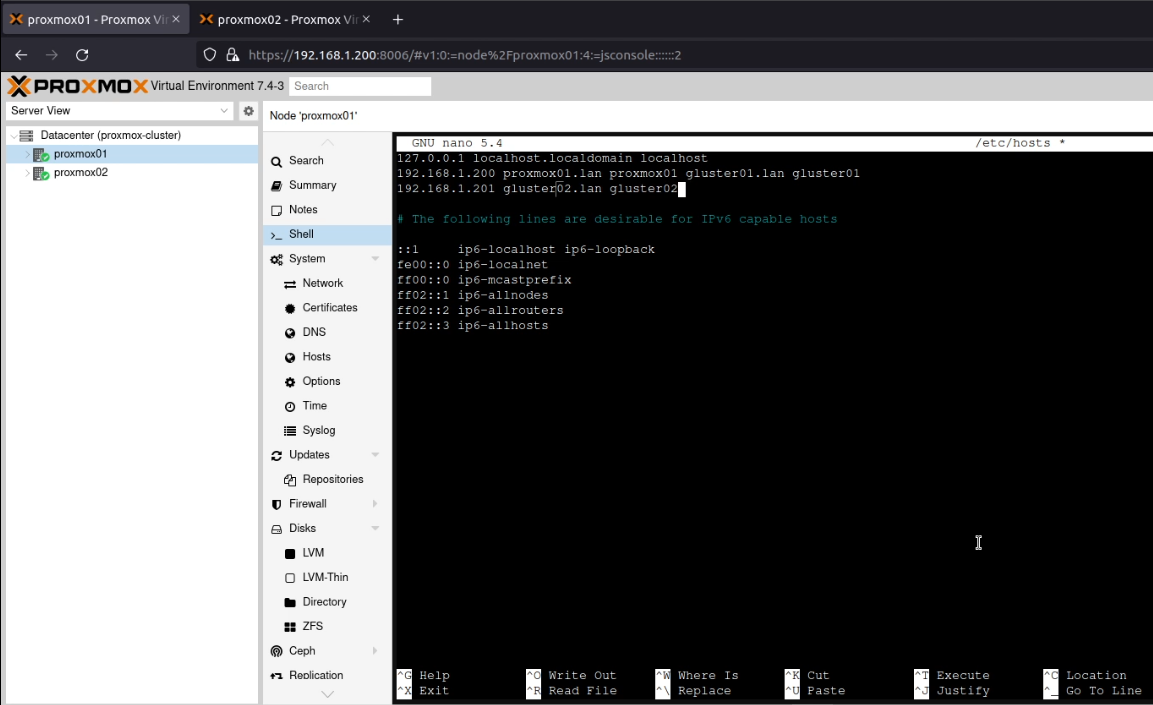
Following the YouTube link above, I created an entry for gluster01 and gluster02 in /etc/hosts which pointed to the IP address of proxmox01 and proxmox02 respectively.
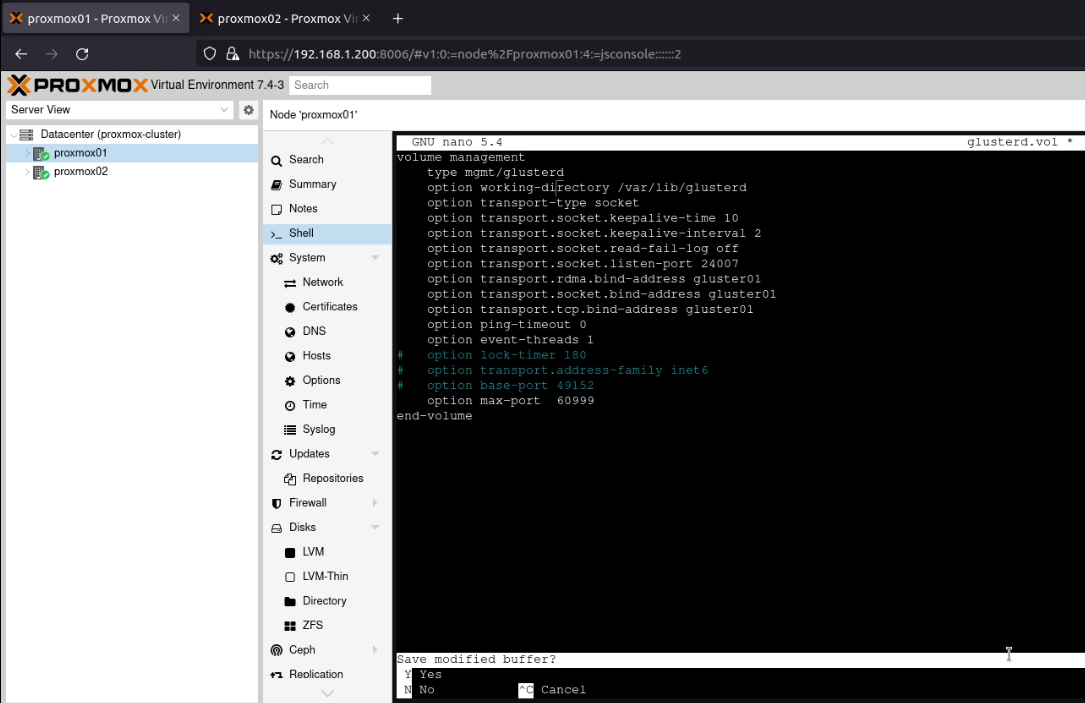
Next, I edited /etc/glusterfs/glusterd.volso it contained this content:
Note that this content above is for proxmox01. For proxmox02 I replaced “gluster01” with “gluster02”. I then ran systemctl enable --now glusterdwhich started the Gluster service.
Once this is done, you must run gluster probe gluster02from proxmox01 (or vice versa), otherwise, when you run the next command, you get this message:
volume create: gluster-volume: failed: Host gluster02 is not in 'Peer in Cluster' state
(This takes some backing out… ugh)
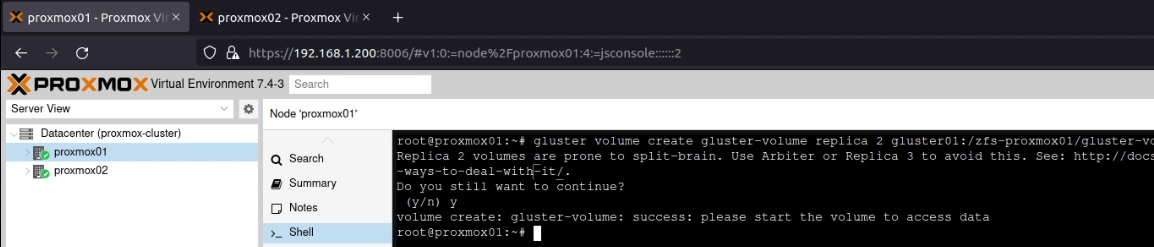
On proxmox01, I created the volume using this command:
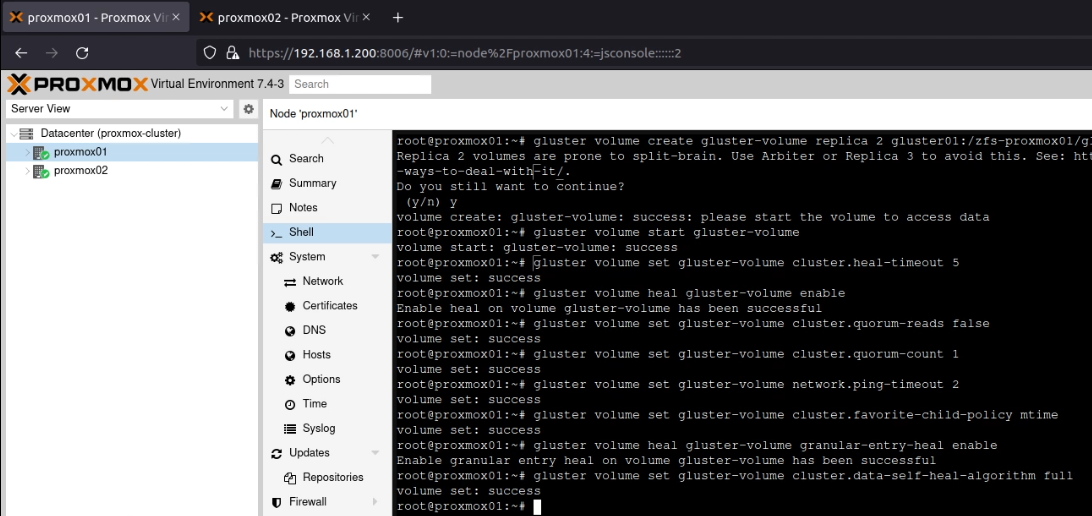
As you can see in the above screenshot, this warned about split brain situations. However, as this is for my home lab, I accepted the risk here. Following the YouTube video again, I ran these commands to “avoid [a] split-brain situation”:
gluster volume start gluster-volume
gluster volume set gluster-volume cluster.heal-timeout 5
gluster volume heal gluster-volume enable
gluster volume set gluster-volume cluster.quorum-reads false
gluster volume set gluster-volume cluster.quorum-count 1
gluster volume set gluster-volume network.ping-timeout 2
gluster volume set gluster-volume cluster.favorite-child-policy mtime
gluster volume heal gluster-volume granular-entry-heal enable
gluster volume set gluster-volume cluster.data-self-heal-algorithm full
I created /gluster-volume on both proxmox01 and proxmox02, and then added this line to /etc/fstab(yes, I know it should really have been a systemd mount unit) on proxmox01:
On both systems, I ensured that /gluster-volume was created, and then ran mount -a.
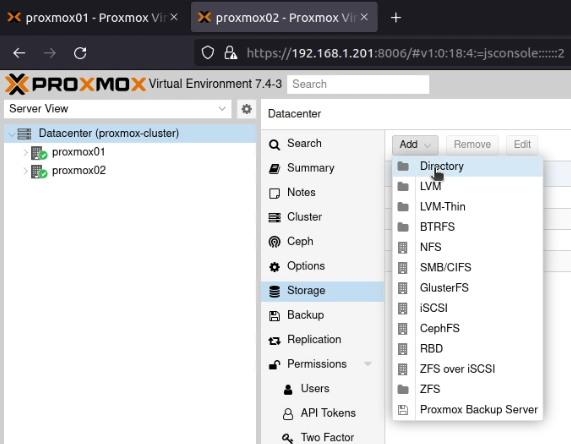
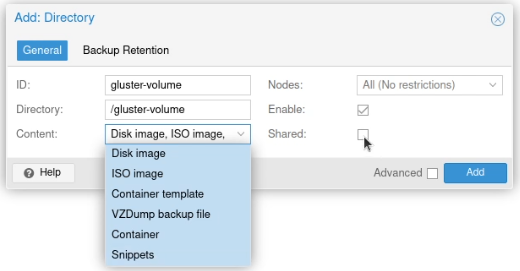
In the Proxmox UI, I went to the “Datacenter” and selected “Storage”, then “Add” and selected “Directory”.
I set the ID to “gluster-volume”, the directory to “/gluster-volume”, ticked the “Shared” box and selected all the content types (it looks like a list box, but it’s actually a multi-select box).
(I forgot to click “Shared” before I selected all the items under “Content” here.)
I clicked Add and it was available on both systems then.
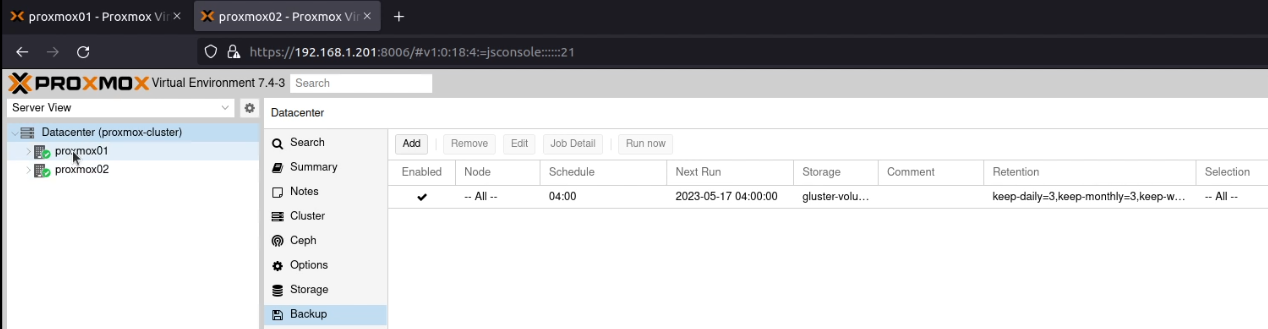
Backups
This one saved me from having to rebuild my Home Assistant system last week! Go into “Datacenter” and select the “Backup” option.
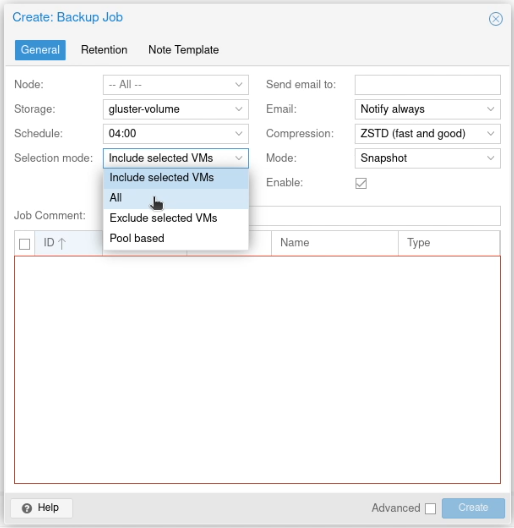
Click the “Add” button, select the storage you’ve just configured (gluster-volume) and a schedule (I picked daily at 04:00) and choose “Selection Mode” of “All”.
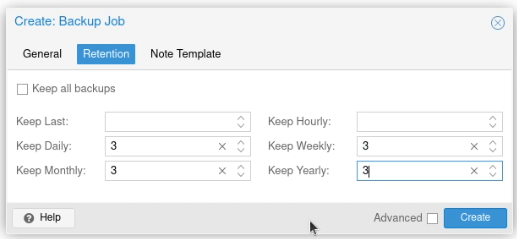
On the retention tab, I entered the number 3 for “Keep Daily”, “Keep Weekly”, “Keep Monthly” and “Keep Yearly”. Your retention needs are likely to be different to mine!
If you end up needing to restore one of these backups, you need a different tool depending on whether it’s a LXC container or a QEMU virtual machine. For a container, you’d run:
vmid=199
pct restore $vmid /path/to/backup-file
For a virtual machine, you’d run:
vmid=199
qmrestore /path/to/backup-file $vmid
…and yes, you can replace the vmid=199 \n $vmidwith just the number for the VMID like this:
If you need to point the storage at a different device (perhaps Gluster broke, or your external drive) you’d add --storage storage-label(e.g. --storage local-lvm)
Networking
The biggest benefit for me of a home lab is being able to build things on their own VLAN. A VLAN allows a single network interface to carry traffic for multiple logical networks, in such a way that other ports on the switch which aren’t configured to carry that logical network can’t access that traffic.
For example, I’ve configured my switch to have a new VLAN on it, VLAN 30. This VLAN is exposed to the two Proxmox servers (which can access all the VLANs) and also the port to my laptop. This means that I can run virtual machines on VLAN 30 which can’t be accessed by any other machine on my network.
There are two ways to do this, the “easy way” and the “explicit way”. Both ways produce the same end state, it’s just down to which makes more logical sense in your head.
In both routes, you must create the VLANs on your switch first – I’m just addressing the way of configuring Proxmox to pass this traffic to your network switch.
Note that these VLAN tagged interfaces also don’t have a DHCP server or Internet gateway (unless you create one), so any addresses will need to be manually configured in any installation screens.
The easy way
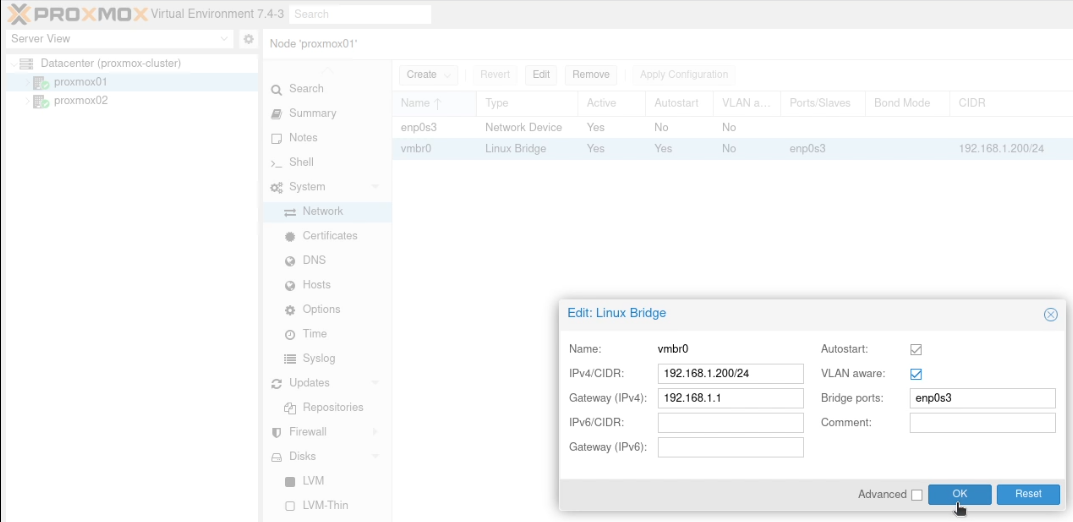
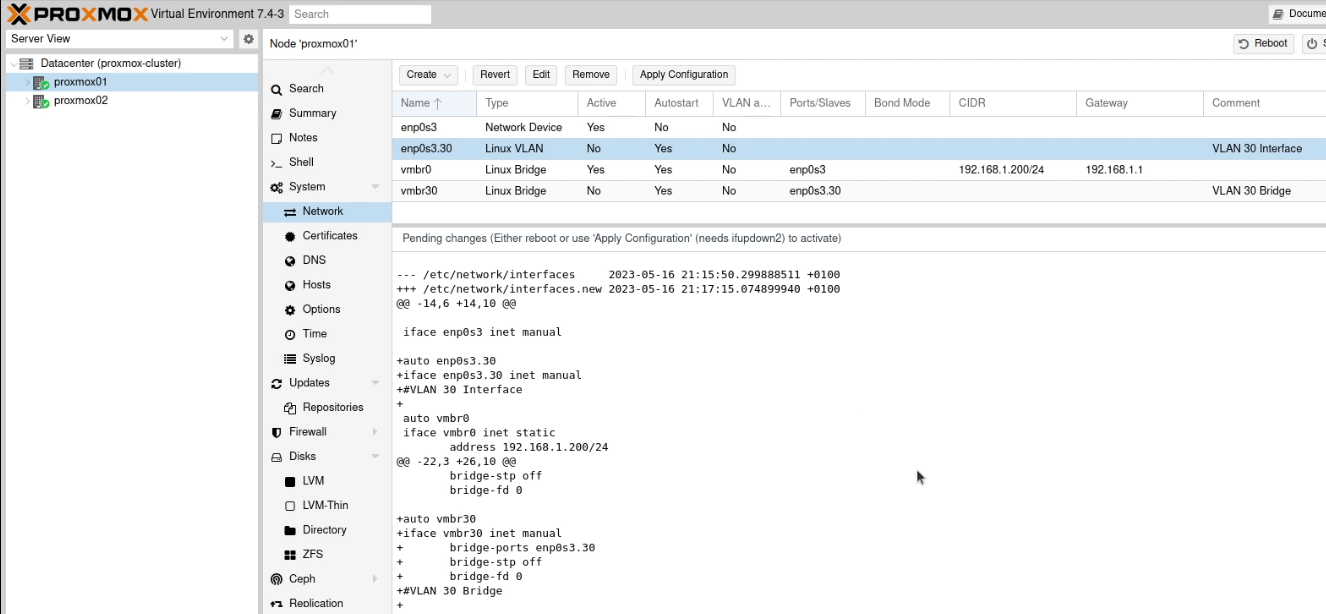
Go into the individual nodes and select the Network option in the sidebar (nested under “System”). You’ll need to perform these actions on both nodes.
Click on the “Linux Bridge” line which is aligned to your “trunked” network interface. For me, as I have a single network interface (enp2s0) I have a single Linux Bridge (vmbr0). Click “Edit” and tick the “VLAN aware” box and click “OK”.
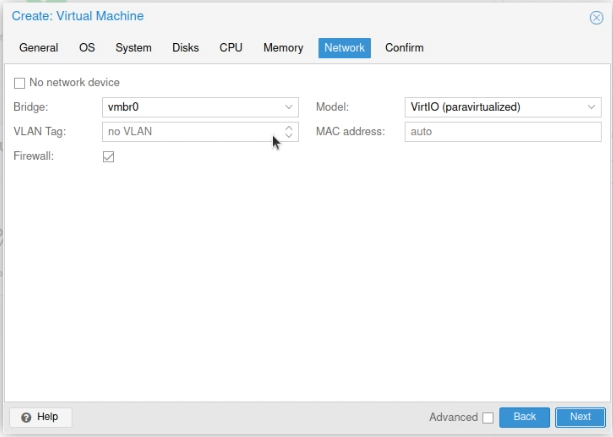
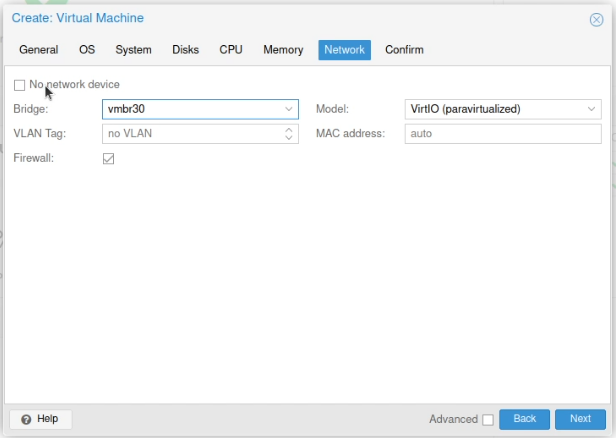
When you now create your virtual machines, on the hardware option in the sidebar, find the network interface and enter the VLAN tag you want to assign.
(This screenshot shows no VLAN tag added, but it’s fairly clear where you’d put that tag in there)
The explicit way
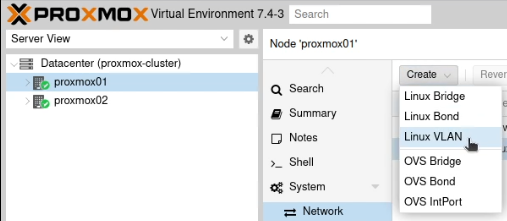
Go into the individual nodes and select the Network option in the sidebar. You’ll need to perform all the steps in the section on both nodes!
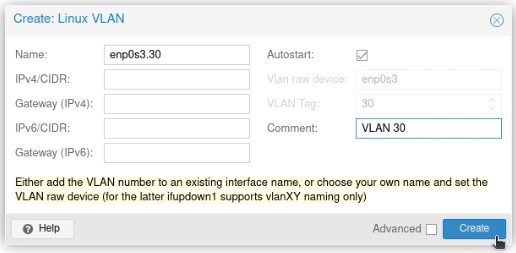
Create a new “Linux VLAN” object.
Call it by the name of the interface (e.g. enp2s0) followed by a dot and then the VLAN tag, like this enp2s0.30. Click Create.
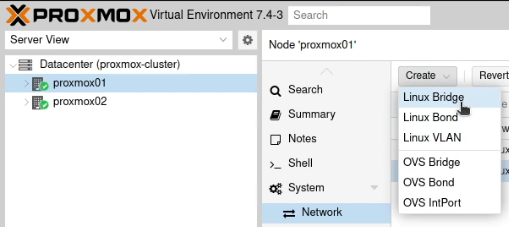
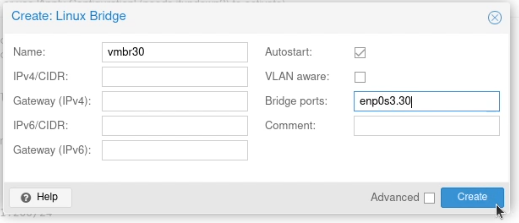
Next create a new “Linux Bridge”.
Call it vmbr and then the VLAN tag, like this vmbr30. Set the ports to the VLAN you just created (enp2s0.30)
(I should note that I added the comment between writing this guide and taking these screen shots)
When you create your virtual machines select this bridge for accessing that VLAN.
Making machines run in “HA”
If you haven’t already done the part with the QDevice under clustering, go back there and run those steps! You need quorum to do this right!
YOU MUST HAVE THE SAME NETWORK AND STORAGE CONFIGURATION FOR HIGH AVAILABILITY AND MIGRATIONS. This means every VM which you want to migrate from proxmox01 to proxmox02 must use the same network interface and storage device, no matter which host it’s connected to.
If you’re connecting enp2s0 to VLAN 55 by using a VLAN Bridge called vmbr55, then both nodes need this VLAN Bridge available. Alternatively, if you’re using a VLAN tag on vmbr0, that’s fine, but both nodes need to have vmbr0 set to be “VLAN aware”.
If you’re using a disk on gluster-volume, this must be shared across the cluster
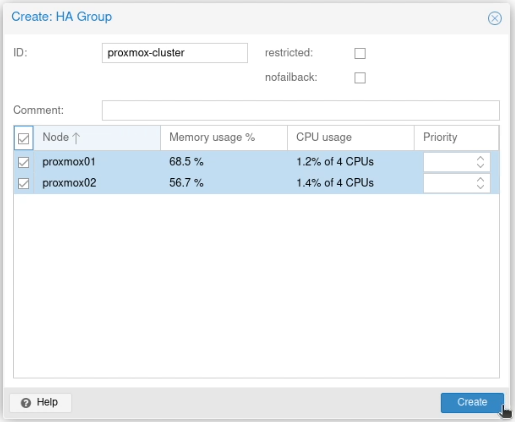
Go to “Datacenter” and select “Groups” which is nested under “HA” in the sidebar.
Create a new group (again, unimaginatively, I went with “proxmox”). Select both nodes and press Create.
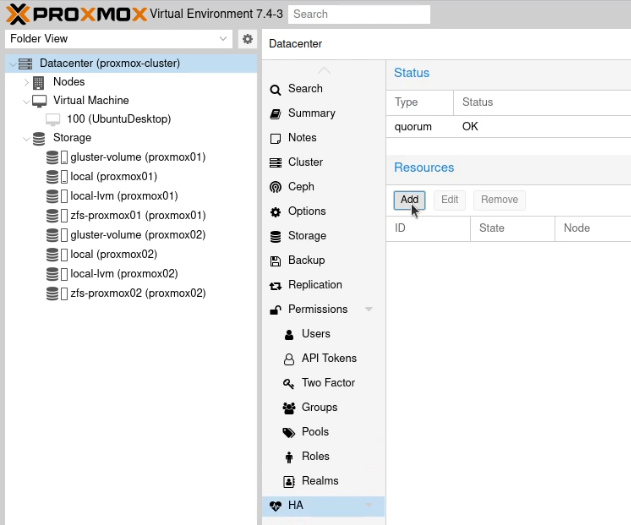
Now go to the “HA” option in the sidebar and verify you have quorum, although it doesn’t matter which is the master.
Under resources on that page, click “Add”.
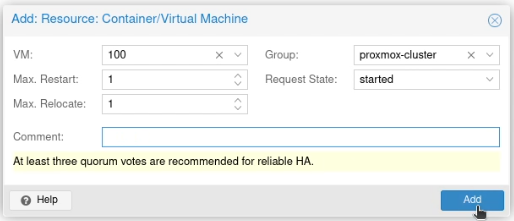
In the VM box, select the ID for the container or virtual machine you want to be highly available and click Add.
This will restart that machine or container in HA mode.
The wrap up!
So, after all of this, there’s still no virtual machines running (well, that Ubuntu Desktop is created but not running yet!) and I’ve not even started playing around with Terraform yet… but I’m feeling really positive about Proxmox. It’s close enough to the proprietary solutions I’ve used at work in the past that I’m reasonably comfortable with it, but it’s open enough to mess around under the surface. I’m looking forward to doing more experiments!
The featured image is of the comms rack in my garage showing how bad my wiring is when I can’t get to the back of a rack!! It’s released under a CC-0 license.