Late edit: 2020-05-22 – Updated with better search criteria from colleague conversations
I’m building a proof of concept for … well, a product that needs testing on several different Linux and Windows variants on AWS and Azure. I’m building this environment with Terraform, and it’s thrown me a few curve balls, so I thought I’d document the issues I’ve had!
The versions of distributions I have tested are the latest releases of each of these images at-or-near the time of writing. The major version listed is the earliest I have tested, so no assumption is made about previous versions, and later versions, after the time of this post should not assume any of this data is also accurate!
(Fujitsu Staff – please contact me on my work email address for details on how to get the internal AMIs of our builds of these images 😄)
Linux Distributions
On the whole, I tend to be much more confident and knowledgable about Linux distributions. I’ve also done far more installs of each of these!
Almost all of these installs are Free of Charge, with the exception of Red Hat Enterprise Linux, which requires a subscription fee, and this can be “Pay As You Go” or “Bring Your Own License”. These sorts of things are arranged for me, so I don’t know how easy or hard it is to organise these licenses!
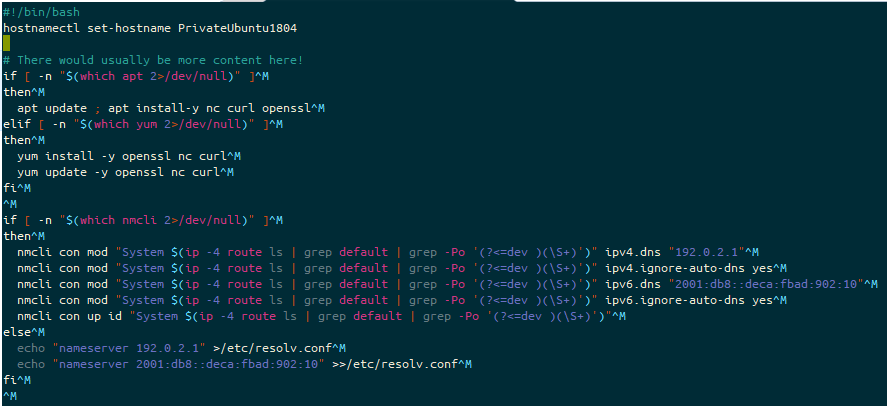
These builds all use cloud-init, via either a cloud-init yaml script, or some shell scripting language (usually accepted to be bash). If this script fails to execute, you will find your user-data file in /var/lib/cloud/instance/scripts/part-001. If this is a shell script then you will be able to execute it by running that script as your root user.
Amazon Linux 2 or Amzn2
Amazon Linux2 is the “preferred” distribution for Amazon Web Services (AWS) (surprisingly enough). It is based on Red Hat Enterprise Linux (RHEL), and many of the instructions you’ll want to run to install software will use RHEL based instructions. This platform is not available outside the AWS ecosystem, as far as I can tell, although you might be able to run it on-prem.
Software packages are limited in this distribution, so any “extra” features require the installation of the “EPEL” repository, by executing the command sudo amazon-linux-extras install epel and then using the yum command to install further packages. I needed nginx for part of my build, and this was only in EPEL.
Amzn2 AMI Lookup
data "aws_ami" "amzn2" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-2.0.*-gp2"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["amazon"] # Canonical
}
Amzn2 User Account
Amazon Linux 2 images under AWS have a default “ec2-user” user account. sudo will allow escalation to Root with no password prompt.
Amzn2 AWS Interface Configuration
The primary interface is called eth0. Network Manager is not installed. To manage the interface, you need to edit /etc/sysconfig/network-scripts/ifcfg-eth0 and apply changes with ifdown eth0 ; ifup eth0.
Amzn2 user-data / Cloud-Init Troubleshooting
I’ve found the output from user-data scripts appearing in /var/log/cloud-init-output.log.
CentOS 7
For starters, AWS doesn’t have an official CentOS8 image, so I’m a bit stymied there! In fact, as far as I can make out, CentOS is only releasing ISOs for builds now, and not any cloud images. There’s an open issue on their bug tracker which seems to suggest that it’s not going to get any priority any time soon! Blimey.
This image may require you to “subscribe” to the image (particularly if you have a “private marketplace”), but this will be requested of you (via a URL provided on screen) when you provision your first machine with this AMI.
Like with Amzn2, CentOS7 does not have nginx installed, and like Amzn2, installation of the EPEL library is not a difficult task. CentOS7 bundles a file to install the EPEL, installed by running yum install epel-release. After this is installed, you have the “full” range of software in EPEL available to you.
CentOS AMI Lookup
data "aws_ami" "centos7" {
most_recent = true
filter {
name = "name"
values = ["CentOS Linux 7*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["aws-marketplace"]
}
CentOS User Account
CentOS7 images under AWS have a default “centos” user account. sudo will allow escalation to Root with no password prompt.
CentOS AWS Interface Configuration
The primary interface is called eth0. Network Manager is not installed. To manage the interface, you need to edit /etc/sysconfig/network-scripts/ifcfg-eth0 and apply changes with ifdown eth0 ; ifup eth0.
CentOS Cloud-Init Troubleshooting
I’ve run several different user-data located bash scripts against this system, and the logs from these scripts are appearing in the default syslog file (/var/log/syslog) or by running journalctl -xefu cloud-init. They do not appear in /var/log/cloud-init-output.log.
Red Hat Enterprise Linux (RHEL) 7 and 8
Red Hat has both RHEL7 and RHEL8 images in the AWS market place. The Proof Of Value (POV) I was building was only looking at RHEL7, so I didn’t extensively test RHEL8.
Like Amzn2 and CentOS7, RHEL7 needs EPEL installing to have additional packages installed. Unlike Amzn2 and CentOS7, you need to obtain the EPEL package from the Fedora Project. Do this by executing these two commands:
wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum install epel-release-latest-7.noarch.rpm
After this is installed, you’ll have access to the broader range of software that you’re likely to require. Again, I needed nginx, and this was not available to me with the stock install.
RHEL7 AMI Lookup
data "aws_ami" "rhel7" {
most_recent = true
filter {
name = "name"
values = ["RHEL-7*GA*Hourly*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["309956199498"] # Red Hat
}
RHEL8 AMI Lookup
data "aws_ami" "rhel8" {
most_recent = true
filter {
name = "name"
values = ["RHEL-8*HVM-*Hourly*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["309956199498"] # Red Hat
}
RHEL User Accounts
RHEL7 and RHEL8 images under AWS have a default “ec2-user” user account. sudo will allow escalation to Root with no password prompt.
RHEL AWS Interface Configuration
The primary interface is called eth0. Network Manager is installed, and the eth0 interface has a profile called “System eth0” associated to it.
RHEL Cloud-Init Troubleshooting
In RHEL7, as per CentOS7, logs from user-data scripts are appear in the general syslog file (in this case, /var/log/messages) or by running journalctl -xefu cloud-init. They do not appear in /var/log/cloud-init-output.log.
In RHEL8, logs from user-data scrips now appear in /var/log/cloud-init-output.log.
Ubuntu 18.04
At the time of writing this, the vendor, who’s product I was testing, categorically stated that the newest Ubuntu LTS, Ubuntu 20.04 (Focal Fossa) would not be supported until some time after our testing was complete. As such, I spent no time at all researching or planning to use this image.
Ubuntu is the only non-RPM based distribution in this test, instead being based on the Debian project’s DEB packages. As such, it’s range of packages is much wider. That said, for the project I was working on, I required a later version of nginx than was available in the Ubuntu Repositories, so I had to use the nginx Personal Package Archive (PPA). To do this, I found the official PPA for the nginx project, and followed the instructions there. Generally speaking, this would potentially risk any support from the distribution vendor, as it’s not certified or supported by the project… but I needed that version, so I had to do it!
Ubuntu 18.04 AMI Lookup
data "aws_ami" "ubuntu1804" {
most_recent = true
filter {
name = "name"
values = ["*ubuntu*18.04*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["099720109477"] # Canonical
}
Ubuntu 18.04 User Accounts
Ubuntu 18.04 images under AWS have a default “ubuntu” user account. sudo will allow escalation to Root with no password prompt.
Ubuntu 18.04 AWS Interface Configuration
The primary interface is called eth0. Network Manager is not installed, and instead Ubuntu uses Netplan to manage interfaces. The file to manage the interface defaults is /etc/netplan/50-cloud-init.yaml. If you struggle with this method, you may wish to install ifupdown and define your configuration in /etc/network/interfaces.
Ubuntu 18.04 Cloud-Init Troubleshooting
In Ubuntu 18.04, logs from user-data scrips appear in /var/log/cloud-init-output.log.
Windows
This section is far more likely to have it’s data consolidated here!
Windows has a common “standard” username – Administrator, and a common way of creating a password (this is generated on-boot, and the password is transferred to the AWS Metadata Service, which it is retrieved and decrypted with the SSH key you’ve used to build the “authentication” to the box) which Terraform handles quite nicely.
The network device is referred to as “AWS PV Network Device #0”. It can be managed with powershell, netsh (although apparently Microsoft are rumbling about demising this script), or from the GUI.
Windows 2012R2
This version is very old now, and should be compared to Windows 7 in terms of age. It is only supported by Microsoft with an extended maintenance package!
Windows 2012R2 AMI Lookup
data "aws_ami" "w2012r2" {
most_recent = true
filter {
name = "name"
values = ["Windows_Server-2012-R2_RTM-English-64Bit-Base*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["801119661308"] # AWS
}
Windows 2012R2 Cloud-Init Troubleshooting
Logs from the Metadata Service can be found in C:\Program Files\Amazon\Ec2ConfigService\Logs\Ec2ConfigLog.txt. You can also find the userdata script in C:\Program Files\Amazon\Ec2ConfigService\Scripts\UserScript.ps1. This can be launched and debugged using PowerShell ISE, which is in the “Start” menu.
Windows 2016
This version is reasonably old now, and should be compared to Windows 8 in terms of age. It is supported until 2022 in “mainline” support.
Windows 2016 AMI Lookup
data "aws_ami" "w2016" {
most_recent = true
filter {
name = "name"
values = ["Windows_Server-2016-English-Full-Base*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["801119661308"] # AWS
}
Windows 2016 Cloud-Init Troubleshooting
The metadata service has moved from Windows 2016 and onwards. Logs are stored in a partially hidden directory tree, so you may need to click in the “Address” bar of the Explorer window and type in part of this path. The path to these files is: C:\ProgramData\Amazon\EC2-Windows\Launch\Log. I say “files” as there are two parts to this file – an “Ec2Launch.log” file which reports on the boot process, and “UserdataExecution.log” which shows the output from the userdata script.
Unlike with the Windows 2012R2 version, you can’t get hold of the actual userdata script on the filesystem, you need to browse to a special path in the metadata service (actually, technically, you can do this with any of the metadata services – OpenStack, Azure, and so on) which is: http://169.254.169.254/latest/user-data/
This will contain userdata between a <powershell> and </powershell> pair of tags. This would need to be copied out of this URL and pasted into a new file on your local machine to determine why issues are occurring. Again, I would recommend using PowerShell ISE from the Start Menu to debug your code.
Windows 2019
This version is the most recent released version of Windows Server, and should be compared to Windows 10 in terms of age.
Windows 2019 AMI Lookup
data "aws_ami" "w2019" {
most_recent = true
filter {
name = "name"
values = ["Windows_Server-2019-English-Full-Base*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["801119661308"] # AWS
}
Windows 2019 Cloud-Init Troubleshooting
Functionally, the same as Windows 2016, but to recap, the metadata service has moved from Windows 2016 and onwards. Logs are stored in a partially hidden directory tree, so you may need to click in the “Address” bar of the Explorer window and type in part of this path. The path to these files is: C:\ProgramData\Amazon\EC2-Windows\Launch\Log. I say “files” as there are two parts to this file – an “Ec2Launch.log” file which reports on the boot process, and “UserdataExecution.log” which shows the output from the userdata script.
Unlike with the Windows 2012R2 version, you can’t get hold of the actual userdata script on the filesystem, you need to browse to a special path in the metadata service (actually, technically, you can do this with any of the metadata services – OpenStack, Azure, and so on) which is: http://169.254.169.254/latest/user-data/
This will contain userdata between a <powershell> and </powershell> pair of tags. This would need to be copied out of this URL and pasted into a new file on your local machine to determine why issues are occurring. Again, I would recommend using PowerShell ISE from the Start Menu to debug your code.
Featured image is “Field Notes – Sweet Tooth” by “The Marmot” on Flickr and is released under a CC-BY license.