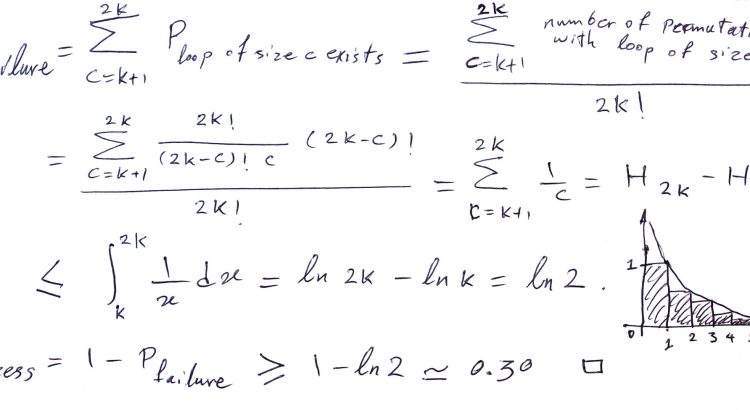I recently was in the situation where I had two github profiles (one work, one personal) that I needed to incorporate in projects.
My work account on this device is my “default”, I use it to push, pull and so on, but the occasional personal activities (like terminate-notice) all should be attributed to my personal account.
To make this happen, I used direnv which reads a .envrcfile in the parents of the directory you’re currently in. I created a directory for my personal projects – ~/Code/Personaland placed a .envrc file which contains:
This means that I have a specific SSH key just for my personal activities (~/.ssh/personal.id_ed25519) and I’ve got my email address defined as two environment variables – AUTHOR (who wrote the code) and COMMITTER (who added it to the tree) – both are required when you’re changing them like this!
Because I don’t ever want it to try to use my SSH Agent, I’ve added the fact that SSH_AUTH_SOCK should be empty.
As an aside, work also require Commit Signing, but I don’t want to use that for my personal projects right now, so I also discovered a new feature as-of 2020 – the environment variables GIT_CONFIG_KEY_x, GIT_CONFIG_VALUE_x and GIT_CONFIG_COUNT=x
By using these, you can override any system, global and repo-level configuration values, like this:
This ensures that I *will not* GPG Sign commits, tags or pushes.
If I accidentally cloned a repo into an unusual location, or on purpose need to make a directory or submodule a personal repo, I just copy the .envrc file into that part of the tree, run direnv allowand hey-presto! I’ve turned that area into a personal repo, without having to remember the .gitconfigstring to mark a new part of my tree as a personal one.
Last week I created a post talking about the new project I’ve started on Github called “Terminate-Notice” (which in hindsight isn’t very accurate – at best it’s ‘spot-instance-responses’ and at worst it’s ‘instance-rebalance-and-actions-responder’ but neither work well)… Anyway, I mentioned how I was creating RPM and DEB packages for my bash scripts and that I hadn’t put it into a repo yet.
Well, now I have, so let’s wander through how I made this work.
I have a the following files in my shell script, which are:
/usr/sbin/terminate-notice (the actual script which will run)
/usr/lib/systemd/system/terminate-notice.service (the SystemD Unit file to start and stop the script)
/usr/share/doc/terminate-notice/LICENSE (the license under which the code is released)
/etc/terminate-notice.conf.d/service.conf (the file which tells the script how to run)
These live in the root directory of my repository.
I also have the .github directory (where the things that make this script work will live), a LICENSE file (so Github knows what license it’s released under) and a README.md file (so people visiting the repo can find out about it).
A bit about Github Actions
Github Actions is a CI/CD pipeline built into Github. It responds to triggers – in our case, pushes (or uploads, in old fashioned terms) to the repository, and then runs commands or actions. The actions which will run are stored in a simple YAML formatted file, referred to as a workflow which contains some setup fields and then the “jobs” (collections of actions) themselves. The structure is as follows:
# The pretty name rendered by Actions to refer to this workflow
name: Workflow Name
# Only run this workflow when the push is an annotated tag starting v
on:
push:
tags:
- 'v*'
# The workflow contains a collection of jobs, each of which has
# some actions (or "steps") to run
jobs:
# This is used to identify the output in other jobs
Unique_Name_For_This_Job:
# This is the pretty name rendered in the Github UI for this job
name: Job Name
# This is the OS that the job will run on - typically
# one of: ubuntu-latest, windows-latest, macos-latest
runs-on: runner-os
# The actual actions to perform
steps:
# This is a YAML list, so note where the hyphens (-) are
# The pretty name of this step
- name: Checkout Code
# The name of the public collection of actions to perform
uses: actions/checkout@v3
# Any variables to pass into this action module
with:
path: "REPO"
# This action will run a shell command
- name: Run a command
run: echo "Hello World"
Build a DEB package
At the simplest point, creating a DEB package is;
Create the directory structure (as above) that will unpack from your package file and put the files in the right places.
Create a DEBIAN/control file which provides enough details for your package manager to handle it.
Run dpkg-deb --build ${PATH_TO_SOURCE} ${OUTPUT_FILENAME}
Assuming the DEBIAN/control file was static and also lived in the repo, and I were just releasing the DEB file, then I could make the above work with the following steps:
name: Create the DEB
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Package
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Copy script files around to stop .github from being added to the package then build the package
run: |
mkdir PKG_SOURCE
cp -Rf REPO/usr REPO/etc REPO/DEBIAN PKG_SOURCE
dpkg-deb --build PKG_SOURCE package.deb
- name: Release the Package
uses: softprops/action-gh-release@v1
with:
files: package.deb
But no, I had to get complicated and ALSO build an RPM file… and put some dynamic stuff in there.
Build an RPM file
RPMs are a little more complex, but not by much. RPM takes a spec file, which starts off looking like the DEBIAN/control file, and adds some “install” instructions. Let’s take a look at that spec file:
The “Name”, “Version”, “Release” and “BuildArch” values in the top of that file define what the resulting filename is (NAME_VERSION-RELEASE.BUILDARCH.rpm).
Notice that there are some “macros” which replace /etc with %{_sysconfdir}, /usr/sbin with %{_sbindir} and so on, which means that, theoretically, this RPM could be installed in an esoteric tree… but most people won’t bother.
The one quirk with this is that %{name} bit there – RPM files need to have all these sources in a directory named after the package name, which in turn is stored in a directory called SOURCES (so SOURCES/my-package for example), and then it copies the files to wherever they need to go. I’ve listed etc/config/file and usr/sbin/script but these could just have easily been file and script for all that the spec file cares.
Once you have the spec file, you run sudo rpmbuild --define "_topdir $(pwd)" -bb file.spec to build the RPM.
So, again, how would that work from a workflow YAML file perspective, assuming a static spec and source tree as described above?
name: Create the DEB
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Package
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Copy script files around to stop .github from being added to the package then build the package
run: |
mkdir -p SOURCES/my-package-name
cp -Rf REPO/usr REPO/etc SOURCES/my-package-name
sudo rpmbuild --define "_topdir $(pwd)" -bb my-package-name.spec
- name: Release the Package
uses: softprops/action-gh-release@v1
with:
files: RPMS/my-package-name_0.0.1-1.noarch.rpm
But again, I want to be fancy (and I want to make resulting packages as simple to repeat as possible)!
So, this is my release.yml as of today:
name: Run the Release
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Packages
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Calculate some variables
run: |
(
echo "GITHUB_REPO_NAME=$(echo "${GITHUB_REPOSITORY}" | cut -d/ -f2)"
echo "VERSION=$(echo "${GITHUB_REF_NAME}" | sed -e 's/^v//')"
echo "DESCRIPTION=A script which polls the AWS Metadata Service looking for an 'instance action', and triggers scripts in response to the termination notice."
echo "DEB_ARCHITECTURE=${ARCHITECTURE:-all}"
echo "RPM_ARCHITECTURE=${ARCHITECTURE:-noarch}"
echo "RELEASE=1"
cd REPO
echo "FIRST_YEAR=$(git log $(git rev-list --max-parents=0 HEAD) --date="format:%Y" --format="format:%ad")"
echo "THIS_COMMIT_YEAR=$(git log HEAD -n1 --date="format:%Y" --format="format:%ad")"
echo "THIS_COMMIT_DATE=$(git log HEAD -n1 --format="format:%as")"
if [ "$FIRST_YEAR" = "$THIS_COMMIT_YEAR" ]
then
echo "YEAR_RANGE=$FIRST_YEAR"
else
echo "YEAR_RANGE=${FIRST_YEAR}-${THIS_COMMIT_YEAR}"
fi
cd ..
) >> $GITHUB_ENV
- name: Make Directory Structure
run: mkdir -p "SOURCES/${GITHUB_REPO_NAME}" SPECS release
- name: Copy script files into SOURCES
run: |
cp -Rf REPO/[a-z]* "SOURCES/${GITHUB_REPO_NAME}"
cp REPO/LICENSE REPO/README.md "SOURCES/${GITHUB_REPO_NAME}/usr/share/doc/${GITHUB_REPO_NAME}/"
if grep -lr '#TAG#' SOURCES
then
sed -i -e "s/#TAG#/${VERSION}/" $(grep -lr '#TAG#' SOURCES)
fi
if grep -lr '#TAG_DATE#' SOURCES
then
sed -i -e "s/#TAG_DATE#/${THIS_COMMIT_YEAR}/" $(grep -lr '#TAG_DATE#' SOURCES)
fi
if grep -lr '#DATE_RANGE#' SOURCES
then
sed -i -e "s/#DATE_RANGE#/${YEAR_RANGE}/" $(grep -lr '#DATE_RANGE#' SOURCES)
fi
if grep -lr '#MAINTAINER#' SOURCES
then
sed -i -e "s/#MAINTAINER#/${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}/" $(grep -lr '#MAINTAINER#' SOURCES)
fi
- name: Create Control File
# Fields from https://www.debian.org/doc/debian-policy/ch-controlfields.html#binary-package-control-files-debian-control
run: |
mkdir -p SOURCES/${GITHUB_REPO_NAME}/DEBIAN
(
echo "Package: ${GITHUB_REPO_NAME}"
echo "Version: ${VERSION}"
echo "Section: ${SECTION:-misc}"
echo "Priority: ${PRIORITY:-optional}"
echo "Architecture: ${DEB_ARCHITECTURE}"
if [ -n "${DEPENDS}" ]
then
echo "Depends: ${DEPENDS}"
fi
echo "Maintainer: ${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}"
echo "Description: ${DESCRIPTION}"
if [ -n "${HOMEPAGE}" ]
then
echo "Homepage: ${HOMEPAGE}"
fi
) | tee SOURCES/${GITHUB_REPO_NAME}/DEBIAN/control
(
echo "Files:"
echo " *"
echo "Copyright: ${YEAR_RANGE} ${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}"
echo "License: MIT"
echo ""
echo "License: MIT"
sed 's/^/ /' "SOURCES/${GITHUB_REPO_NAME}/usr/share/doc/${GITHUB_REPO_NAME}/LICENSE"
) | tee SOURCES/${GITHUB_REPO_NAME}/DEBIAN/copyright
- name: Create Spec File
run: PATH="REPO/.github/scripts:${PATH}" create_spec_file.sh
- name: Build DEB Package
run: dpkg-deb --build SOURCES/${GITHUB_REPO_NAME} "${{ env.GITHUB_REPO_NAME }}_${{ env.VERSION }}_${{ env.DEB_ARCHITECTURE }}.deb"
- name: Build RPM Package
run: sudo rpmbuild --define "_topdir $(pwd)" -bb SPECS/${GITHUB_REPO_NAME}.spec
- name: Confirm builds complete
run: sudo install -m 644 -o runner -g runner $(find . -type f -name *.deb && find . -type f -name *.rpm) release/
- name: Release
uses: softprops/action-gh-release@v1
with:
files: release/*
So this means I can, within reason, drop this workflow (plus a couple of other scripts to generate the slightly more complex RPM file – see the other files in that directory structure) into another package to release it.
OH WAIT, I DID! (for the terminate-notice-slack repo, for example!) All I actually needed to do there was to change the description line, and off it went!
So, this is all well and good, but how can I distribute these? Enter Repositories.
Making a Repository
Honestly, I took most of the work here from two fantastic blog posts for creating an RPM repo and a DEB repo.
First you need to create a GPG key.
To do this, I created the following pgp-key.batch file outside my repositories tree
%echo Generating an example PGP key
Key-Type: RSA
Key-Length: 4096
Name-Real: YOUR_ORG_NAME
Name-Email: your_org_name@users.noreply.github.com
Expire-Date: 0
%no-ask-passphrase
%no-protection
%commit
Store the public.asc file to one side (you’ll need it later) and keep the private.asc safe because we need to put that into Github.
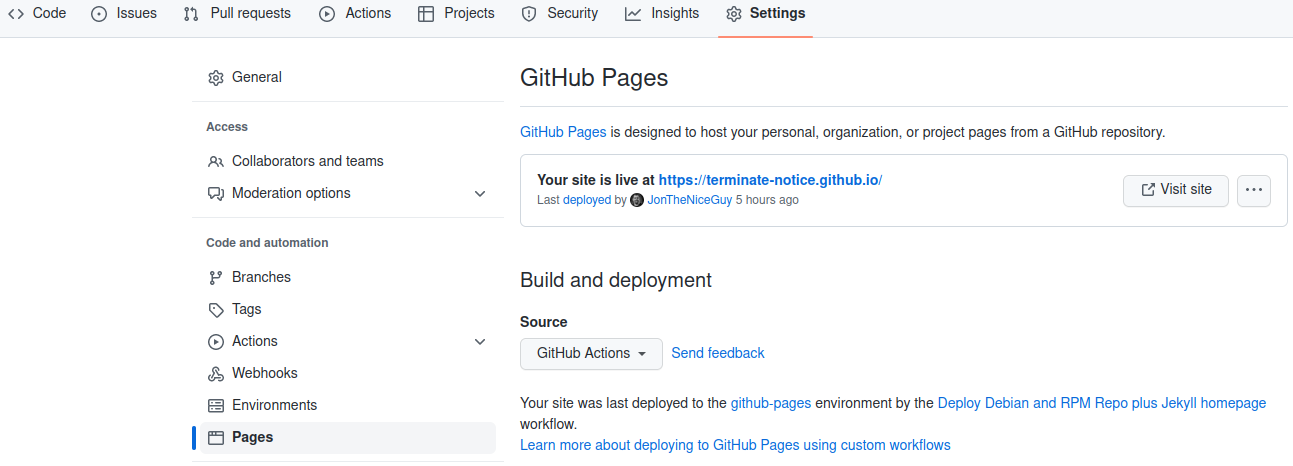
Creating Github Pages
Create a new Git repository in your organisation called your-org.github.io. This marks the repository as being a Github Pages repository. Just to make that more explicit, in the settings for the repository, go to the pages section. (Note that yes, the text around this may differ, but are accurate as of 2023-03-28 in EN-GB localisation.)
Under “Source” select “GitHub Actions”.
Clone this repository to your local machine, and copy public.asc into the root of the tree with a sensible name, ending .asc.
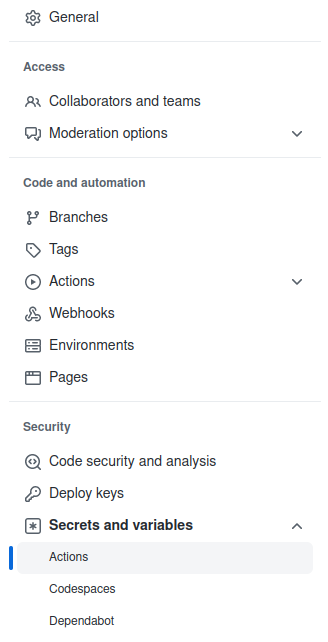
In the Github settings, find “Secrets and variables” under “Security” and pick “Actions”.
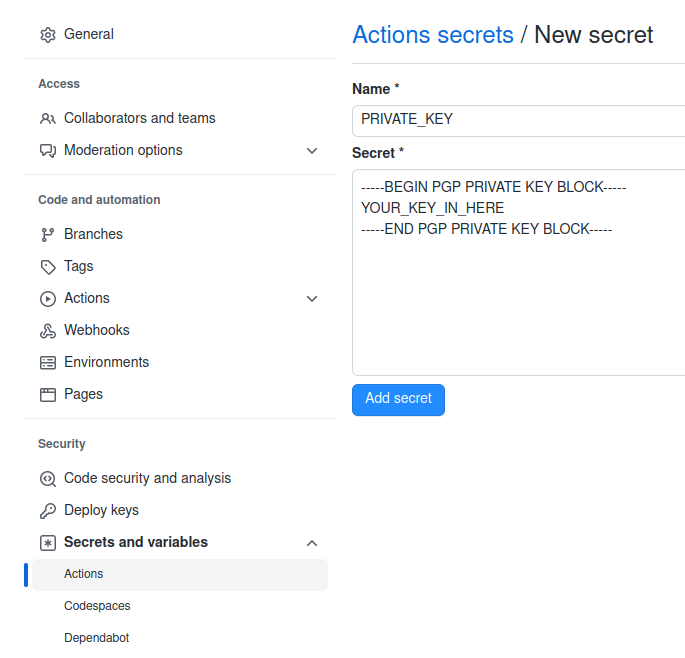
Select “New repository secret” and call it “PRIVATE_KEY”.
Now you can use this to sign things (and you will sign *SO MUCH* stuff)
Building the HTML front to your repo (I’m using Jekyll)
I’ve elected to use Jekyll because I know it, and it’s quite easy, but you should pick what works for you. My workflow for deploying these repos into the website rely on Jekyll because Github built that integration, but you’ll likely find other tools for things like Eleventy or Hugo.
Put a file called _config.yml into the root directory, and fill it with relevant content:
title: your-org
email: email_address@example.org
description: >-
This project does stuff.
baseurl: ""
url: "https://your-org.github.io"
github_username: your-org
# Build settings
theme: minima
plugins:
- jekyll-feed
exclude:
- tools/
- doc/
Naturally, make “your-org” “email_address@example.org” and the descriptions more relevant to your environment.
Next, create an index.md file with whatever is relevant for your org, but it must start with something like:
---
layout: home
title: YOUR-ORG Website
---
Here is the content for the front page.
Building the repo behind your static content
We’re back to working with Github Actions workflow files, so let’s pop that open.
I’ve basically changed the “stock” Jekyll static site Github Actions file and added every step that starts [REPO] to make the repository stuff fit in around the steps that start [JEKYLL] which build and deploy the Jekyll based site.
The key part to all this though is the step Build DEB and RPM repos which calls a script that downloads all the RPM and DEB files from the various other repository build stages and does some actions to them. Now yes, I could have put all of this into the workflow.yml file, but I think it would have made it all a bit more confusing! So, let’s work through those steps!
Making an RPM Repo
To build a RPM repo you get and sign each of the RPM packages you want to offer. You do this with this command:
Then, once you have all your RPM files signed, you then run a command called createrepo_c (available in Debian archives – Github Actions doesn’t have a RedHat based distro available at this time, so I didn’t look for the RPM equivalent). This creates the repository metadata, and finally you sign that file, like this:
gpg --detach-sign --armor repodata/repomd.xml
Making a DEB Repo
To build a DEB repo you get each of the DEB packages you want to offer in a directory called pool/main (you can also call “main” something else – for example “contrib”, “extras” and so on).
Once you have all your files, you create another directory called dists/stable/main/binary-all into which we’ll run a command dpkg-scanpackages to create the list of the available packages. Yes, “main” could also be called “contrib”, “extras” and “stable” could be called “testing” or “preprod” or the name of your software release (like “jaunty”, “focal” or “warty”). The “all” after the word “binary” is the architecture in question.
dpkg-scanpackages creates an index of the packages in that directory including the version number, maintainer and the cryptographic hashes of the DEB files.
We zip (using gzip and bzip2) the Packages file it creates to improve the download speeds of these files, and then make a Release file. This in turn has the cryptographic hashes of each of the Packages and zipped Packages files, which in turn is then signed with GPG.
Ugh, that was MESSY
Making the repository available to your distributions
RPM repos have it quite easy here – there’s a simple file, that looks like this:
The distribution user simply downloads this file, puts it into /etc/yum.sources.d/org-name.repo and now all the packages are available for download. Woohoo!
DEB repos are a little harder.
First, download the public key – https://org-name.github.io/public.asc and put it in /etc/apt/keyrings/org-name.asc. Next, create file in /etc/apt/sources.list.d/org-name.list with this line in:
deb [arch=all signed-by=/etc/apt/keyrings/org-name.asc] https://org-name.github.io/deb stable main
And now they can install whatever packages they want too!
Doing this the simple way
Of course, this is all well-and-good, but if you’ve got a simple script you want to package, please don’t hesitate to use the .github directory I’m using for terminate-notice, which is available in the -skeleton repo and then to make it into a repo, you can reuse the .github directory in the terminate-notice.github.io repo to start your adventure.
I’m using Vagrant to test out some scripts, and I really need to stop myself from destroying my caching proxy that I’m running in the test.
To do that, I’ve got this Vagrantfile:
Vagrant.configure("2") do |config|
config.vm.define "caching-proxy" do |this|
this.trigger.before :destroy do |trigger|
trigger.info = "This machine is currently prevented from being destroyed. Please remove the trigger to be able to destroy it.
trigger.abort = 1
end
this.vm.box = "ubuntu/jammy64"
# etc
end
config.vm.define "normalnode" do |this|
this.vm.box = "ubuntu/jammy64"
end
end
Now when I try to run vagrant destroy caching-proxy I get:
==> caching-proxy: Running action triggers before destroy ...
==> caching-proxy: Running trigger...
==> caching-proxy: This machine is currently prevented from being destroyed. Please remove the trigger to destroy it.
==> caching-proxy: Vagrant has been configured to abort. Terminating now...
Running vagrant destroy normalnode I get:
normalnode: Are you sure you want to destroy the 'normalnode' VM? [y/N] y
==> normalnode: Forcing shutdown of VM...
==> normalnode: Destroying VM and associated drives...
During some debugging of an issue with our AWS Spot Instances at work, a colleague noticed that we weren’t responding to the Instance Actions that AWS sends when it’s due to shut down a spot instance.
I’m working on a new project, and I am using Multipass on an Ubuntu machine to provision some virtual machines on my local machine using cloudinit files. All good so far!
I wanted to expose one of the services I’ve created to the bridged network (so I can run avahi-daemon), and did this by running multipass launch -n vm01 --network enp3s0 when, what should I see but: launch failed: The bridging feature is not implemented on this backend. OH NO!
Over the last year, the team I was in had a routine that every week we’d have a briefing-come-good-news meeting. About a third of the way through the year the routine changed and it would be fronted by a presentation on a subject of interest to that team member. It was loosely encouraged to be relevant to the job, but it wasn’t a formal requirement.
For whatever reason, my slot got bumped (I think it was the day of the Queen’s funeral, but I’m not sure), and then I rescheduled myself for December… and the meeting was cancelled as we were having an in-person meetup. Bah.
For some of my projects, I run a Dynamic DNS server service attached to one of the less-standard DNS Names I own, and use that to connect to the web pages I’m spinning up. In a recent demo, I noticed that the terraform “changes” log where it shows what things are being updated showed the credentials I was using, because I was using “simple” authentication, like this:
For context, that would ask the DDNS service running at ddns.example.org to create a DNS record for web.ddns.example.org with an A record of 192.0.2.1.
While this is fine for my personal projects, any time this goes past, anyone who spots that update line would see the credentials I use for this service. Not great.
I had a quick look at the other options I had for authentication, and noticed that the DDNS server I’m running also supports the DynDNS update mechanism. In that case, we need to construct things a little differently!
So now, we change the URL to include the /nic/ path fragment, we use different names for the variables and we’re using Basic Authentication which is a request header. It’s a little frustrating that the http data source doesn’t also have a query type or a path constructor we could have used, but…
In this context the request header of “Authorization” is a string starting “Basic” but then with a Base64 encoded value of the username (which for this DDNS service, can be anything, so I’ve set it as the word “user”), then a colon and then the password. By setting the ddns_secret variable as being “sensitive”, if I use terraform console, and ask it for the value of data.http.ddns_web I get
Note that if your DDNS service has a particular username requirement, this can also be entered, in the same way, by changing the string “user” to something like ${var.ddns_user}.
Outside of work, I attended my first technical event since the 2020 lockdown. A Barcamp is a community run conference where the attendees propose the talks they want to present. In past years, I have attended with an intention to speak, and in some cases present several talks.
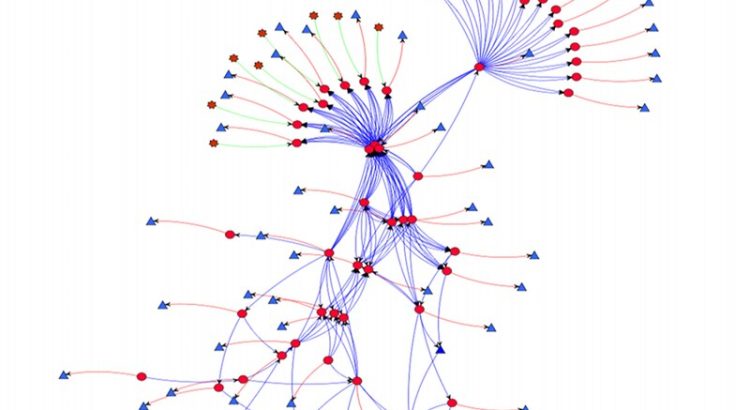
This a a picture of “the grid” – the cards on the far left are the rooms in which talks occur, the cards on the top row are time slots in which talks were to be delivered, and the rest of the cards were proposed talks. This picture by Martin Rue on Twitter and used with his kind permission.
The first talk I attended was a talk by Patrick Hurley who was asking people to propose ideas to that would benefit people in the north of England. These will be written up into a book and used as inspiration for projects big and small. Well worth a look! 100ideasnorth.org
I missed the next slot, as I was making my way around groups of people I’d not spoken to for a while, but then my next talk of interest was “I’m an AWS Engineer… Ask me Anything (we’re hiring)” by Martin. I didn’t know anyone else from AWS was going to be there, so I went, if only to introduce myself and say hi… Well, one thing lead to another, and then I found myself joining Martin answering questions from my perspective in a different part of the organisation. I loved this session, and I’m really glad to have caught up with Martin, if only because he was such a lovely man and so enthusiastic about everything he was talking about!
After that, I went to the talk about Living in Japan by Fran. This was a quick ad-hoc talk, but totally adorable because it was just completely heartfelt and had loads of questions that were answered with fab anecdotes about life at a ladies-only university outside Tokyo… the questions were really good too!
Over lunch and slot 5, I put together a talk about my boardgame collection, and agreed to co-host a talk about working at AWS with Martin again.
I also found myself in a small talk, hosted by Harper, the 8 year old daughter of one of the attendees, who was very keen to present her first talk. It was a beautiful and well delivered talk about the elements of a pen, her favourite pen and what each element is for. She also fielded questions from the audience with a lot of confidence and spoke with great authority. She was fab, and I made a point of letting everyone I saw know about her talk!
I went to a talk in Slot 6 called “Dude, where’s my meetup” – a slightly confused talk which seemed to be asking “what happened to all the groups that met up in Manchester”, while also not being clear whether it was asking “and who’s going to run them again now we’re all meeting back up” or “why haven’t they restarted” or “what is replacing them” or even “why aren’t the groups which have restarted making more noise about themselves to make them found”… I plugged the North West UK Tech Community and encouraged groups to register themselves on there, and individuals to help clean out older groups that have closed.
I gave my talk on the Board Game spreadsheet I have created, and got a great couple of ideas on categorising the games we have, and whether expansions should be games in their own right, or not. Several people took links away, and I picked up this great alternative version that I could be reusing!
Next up was the conversation with the audience about working at AWS. Lots of really good questions again, and Martin and I developed quite a good raport. I think we’ll be trying to do things like these talks again!
After that session, I spoke to one of the audience members from the AWS session about being recruited by AWS, and then to another person about how they were using AWS. I really enjoyed being part of a conversation about how other people see AWS – I know it’s a lot of my day job, but it was just a nice reassurance that it’s not just something I can do inside my working hours!
Then we had the wrap-up, and there were lots of claps and cheers for the organising team and for anyone who spoke at the event. Great work everyone!
Afterwards, I went to the pub with some people who used to go to Geekup (and it was glorious!) and then made my way home.
All in all, a great day, and I’m looking forward to the next one!
Yep, they let me back on! And so, following the last recording (probably around November-ish), we recorded the chat that became Episode 53 of the It’s a Chat podcast. Much like the last episode, we talk about things which are connected to The Matrix: Reloaded (and get about 1/3rd of the way through the film), and talk about other stuff as well. I talk a fair amount about the Animatrix and we briefly discuss the game (that I don’t think any of us played).
I reference a series of books which I read, that I referred to as “Sand” but instead actually meant the first book, called “Wool” of the series “Silo“, which I rated 3/5 on Goodreads.
I also draw a conclusion that Agent Smith is actually rickrolling us, four years before rickrolling was a thing.
Featured image is “Matrix” by “Jordi nll” on Flickr and is released under a CC-BY-SA license.
I’ve been working on my Decision Records open source project for a few months now, and I’ve finally settled on the cross-platform language Rust to create my script. As a result, I’ve got a build process which lets me build for Windows, Mac OS and Linux. I’m currently building a single, unsigned binary for each platform, and I wanted to make it so that Github Actions would build and release these three files for me. Most of the guidance which is currently out there points to some unmaintained actions, originally released by GitHub… but now they point to a 3rd party “release” action as their recommended alternative, so I thought I’d explain how I’m using it to release on several platforms at once.
Although I can go into detail about the release file I’m using for Rust-Decision-Records, I’m instead going to provide a much more simplistic view, based on my (finally working) initial test run.
GitHub Actions
GitHub have a built-in Continuous Integration, Continuous Deployment/Delivery (CI/CD) system, called GitHub Actions. You can have several activities it performs, and these are executed by way of instructions in .github/workflows/<somefile>.yml. I’ll be using .github/workflows/build.yml in this example. If you have multiple GitHub Action files you wanted to invoke (perhaps around issue management, unit testing and so on), these can be stored in separate .yml files.
The build.yml actions file will perform several tasks, separated out into two separate activities, a “Create Release” stage, and a “Build Release” stage. The Build stage will use a “Matrix” to execute builds on the three platforms at the same time – Linux AMD64, Windows and Mac OS.
The actual build steps? In this case, it’ll just be writing a single-line text file, stating the release it’s using.
So, let’s get started.
Create Release
A GitHub Release is typically linked to a specific “tagged” commit. To trigger the release feature, every time a commit is tagged with a string starting “v” (like v1.0.0), this will trigger the release process. So, let’s add those lines to the top of the file:
name: Create Release
on:
push:
tags:
- 'v*'
You could just as easily use the filter pattern ‘v[0-9]+.[0-9]+.[0-9]+’ if you wanted to use proper Semantic Versioning, but this is a simple demo, right? 😉
Next we need the actual action we want to start with. This is at the same level as the “on” and “name” tags in that YML file, like this:
So, this is the actual “create release” job. I don’t think it matters what OS it runs on, but ubuntu-latest is the one I’ve seen used most often.
In this, you instruct it to create a simple release, using the text in the annotated tag you pushed as the release notes.
This is using a third-party release action, softprops/action-gh-release, which has not been vetted by me, but is explicitly linked from GitHub’s own action.
If you check the release at this point, (that is, without any other code working) you’d get just the source code as a zip and a .tgz file. BUT WE WANT MORE! So let’s build this mutha!
Build Release
Like with the create_release job, we have a few fields of instructions before we get to the actual actions it’ll take. Let’s have a look at them first. These instructions are at the same level as the jobs:\n create_release: line in the previous block, and I’ll have the entire file listed below.
So this section gives this job an ID (build_release) and a name (Build Release), so far, so exactly the same as the previous block. Next we say “You need to have finished the previous action (create_release) before proceeding” with the needs: create_release line.
But the real sting here is the strategy:\n matrix: block. This says “run these activities with several runners” (in this case, an unspecified Ubuntu, Mac OS and Windows release (each just “latest”). The include block asks the runners to add some template variables to the tasks we’re about to run – specifically release_suffix.
The last line in this snippet asks the runner to interpret the templated value matrix.os as the OS to use for this run.
Let’s move on to the build steps.
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Run Linux Build
if: matrix.os == 'ubuntu-latest'
run: echo "Ubuntu Latest" > release_ubuntu
- name: Run Mac Build
if: matrix.os == 'macos-latest'
run: echo "MacOS Latest" > release_mac
- name: Run Windows Build
if: matrix.os == 'windows-latest'
run: echo "Windows Latest" > release_windows
This checks out the source code on each runner, and then has a conditional build statement, based on the OS you’re using for each runner.
It should be fairly simple to see how you could build this out to be much more complex.
The final step in the matrix activity is to add the “built” file to the release. For this we use the softprops release action again.