Last night, I met with a group of friends that I’d not seen for probably 10 years, and it was glorious.
In 2006, I was relatively fresh-faced in the North-West Tech Community. I’d moved North in 2002, spent a couple of years finding my feet, and finally ended up hearing about GeekUp. GeekUp had been a mash-up of a few different Web Developers community groups, and was, for many years, my “geeky home”. It met monthly in a room above a bar, under a bar, and for a period of time, in a small nook on a balcony over a bar. Organised by Andrew for much of it’s time, and spread from Manchester to Leeds, Preston, Sheffield, Liverpool and further afield, it was a safe place for anyone who worked in Tech to come and realise that life wasn’t so bad all the time, or… at least, that’s how it felt to me. It was the first place I gave a talk outside of work, and a place where I finally felt like I’d found my “tribe”.
In 2011, my eldest was born, and I found it progressively harder and harder to get to meetings, and by 2016, when the meetings finally ended, I’d not been to one for over a year.
I kept an eye on people I knew, and kept bumping into individuals around the events I could make it to – mostly BarCamps [1] and by 2018 I missed the community feel, so I created something like GeekUp in my semi-rural area. It ran for about a year, by which time the mojo had gone, and I wrapped up the group … we were ahead of the curve on closing in-person meetups by a year!
About a month ago, I saw on LinkedIn that GeekUp was holding one-part reunion, one-part restart of events at the Leigh Hackspace, near Warrington.
And my word, what a GeekUp it was; I knew every face (barring one Leigh Hackspace user who turned up and discovered we had pizza, so stayed) although some took me a while to recall who they were and we all got to chat about what we’ve done in the in-between times.
Will there be another one? Andrew hopes to restart something in Manchester in the new year. One of the former Preston GeekUp organisers wants to restart something there, and the Leigh Hackspace was a great space to host “something”… although it might be a bit far for me for a monthly meeting!
So, what’s my message here? Well, if you previously organised a meetup, social group or community for some passion of yours, and it’s been a while since you ran one… why not consider whether you might consider reviving it – especially if you’ve still got the passion for that thing… and get back out there. I certainly enjoyed being back in the thick of it all.
[1] BarCamp: An “Unconference” or Unscheduled Conference; where there is no pre-defined schedule for your conference, just a number of meeting spaces, a “grid” or timetable, and a stack of sticky notes and pens for your attendees to put their talks forward. Usually free or a small nominal cost for room hire.
Featured image is the GeekUp logo, retrieved 2025-10-31 from https://geekup.org
Slides: No slides provided (nothing to present on!), but the script is here
Video: Not recorded.
Slot: 11 AM, 10th February 2025, 10 minutes
Notes: This is a little unusual. both because I’m posting it as a “Talk Summary” but also because it was a Eulogy. Auntie Pat died in December. The talk I delivered was my memories of her, augmented by a few comments from her next nearest relative, the daughter of her cousin. The room was mostly filled with people I didn’t know, except for one row with my brother and his family. Following the funeral, several people suggested I’d done very well. One person remarked they hadn’t heard the talk because they forgot to wear their hearing aid. I guess when someone passes away in their 80’s, most of their friends will be too. Several people expressed sadness that they hadn’t known all the things I shared about her. We all enjoyed memories of her.
I’m in the process of building a Network Firewall for a work environment. This blog post is based on that work, but with all the identifying marks stripped off.
For this particular project, we standardised on Alma Linux 9 as the OS Base, and we’ve done some testing and proved that the RedHat default firewalling product, Firewalld, is not appropriate for this platform, but did determine that NFTables, or NetFilter Tables (the successor to IPTables) is.
I’ll warn you, I’m pretty prone to long and waffling posts, but there’s a LOT of technical content in this one. There is also a Git repository with the final code. I hope that you find something of use in here.
This document explains how it is using Vagrant with Virtualbox to build a test environment, how it installs a Puppet Server and works out how to calculate what settings it will push to it’s clients. With that puppet server, I show how to build and configure a firewall using Linux tools and services, setting up an NFTables policy and routing between firewalls using FRR to provide BGP, and then I will show how to deploy a DHCP server.
Let’s go!
The scenario
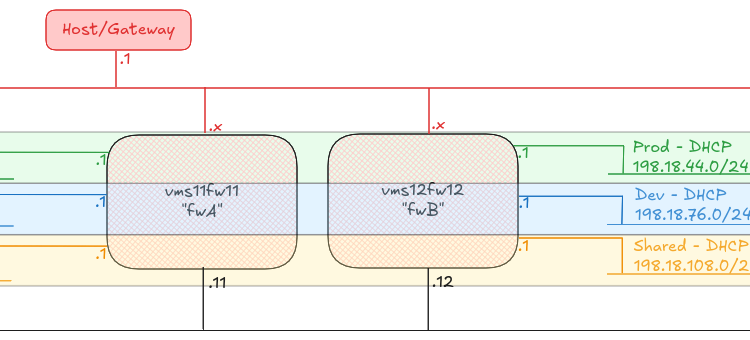
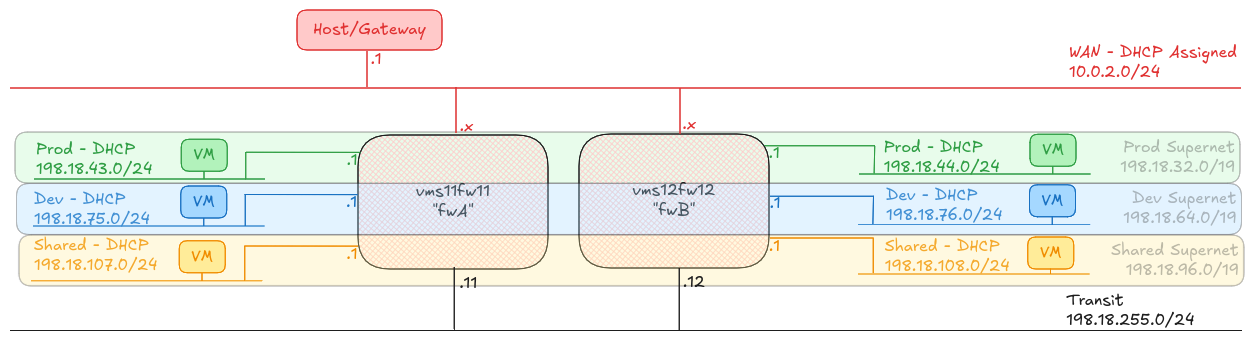
To prove the concept, I have built two Firewall machines (A and B), plus six hosts, one attached to each of the A and B side subnets called “Prod”, “Dev” and “Shared”.
Any host on any of the “Prod” networks should be able to speak to any host on any of the other “Prod” networks, or back to the “Shared” networks. Any host on any of the “Dev” networks should be able to speak to any host on the other “Dev” networks, or back to the “Shared” networks.
Any host in Prod, Dev or Shared should be able to reach the internet, and shared can reach any of the other networks.
For “reasons”, at work we run AWS Elastic Kubernetes Service (EKS) with our own custom-built workers. These workers are based on Alma Linux 9, instead of AWS’ preferred Amazon Linux 2023. We manage the deployment of these workers using AWS Auto-Scaling Groups.
Our unusal configuration of these nodes mean that we sometimes trip over configurations which are tricky to get support on from AWS (no criticism of their support team, if I was in their position, I wouldn’t want to try to provide support for a customer’s configuration that was so far outside the recommended configuration either!)
Over the past year, we’ve upgraded EKS1.23 to EKS1.27 and then on to EKS1.31, and we’ve stumbled over a few issues on the way. Here are a couple of notes on the subject, in case they help anyone else in their journey.
All three of the issues below were addressed by running an additional service on the worker nodes in a Systemd timed service which triggers every minute.
Incorrect routing for the 12th IP address onwards
Something the team found really early on (around EKS 1.18 or somewhere around there) was that the AWS VPC-CNI wasn’t managing the routing tables on the node properly. We raised an issue on the AWS VPC CNI (we were on CentOS 7 at the time) and although AWS said they’d fixed the issue, we currently need to patch the routing tables every minute on our nodes.
What happens?
When you get past the number of IP addresses that a single ENI can have (typically ~12), the AWS VPC-CNI will attach a second interface to the worker, and start adding new IP addresses to that. The VPC-CNI should setup routing for that second interface, but for some reason, in our case, it doesn’t. You can see this happens because the traffic will come in on the second ENI, eth1, but then try to exit the node on the first ENI, eth0, with a tcpdump, like this:
[root@test-i-01234567890abcdef ~]# tcpdump -i any host 192.0.2.123
tcpdump: data link type LINUX_SLL2
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
09:38:07.331619 eth1 In IP ip-192-168-1-100.eu-west-1.compute.internal.41856 > ip-192-0-2-123.eu-west-1.compute.internal.irdmi: Flags [S], seq 1128657991, win 64240, options [mss 1359,sackOK,TS val 2780916192 ecr 0,nop,wscale 7], length 0
09:38:07.331676 eni989c4ec4a56 Out IP ip-192-168-1-100.eu-west-1.compute.internal.41856 > ip-192-0-2-123.eu-west-1.compute.internal.irdmi: Flags [S], seq 1128657991, win 64240, options [mss 1359,sackOK,TS val 2780916192 ecr 0,nop,wscale 7], length 0
09:38:07.331696 eni989c4ec4a56 In IP ip-192-0-2-123.eu-west-1.compute.internal.irdmi > ip-192-168-1-100.eu-west-1.compute.internal.41856: Flags [S.], seq 3367907264, ack 1128657992, win 26847, options [mss 8961,sackOK,TS val 1259768406 ecr 2780916192,nop,wscale 7], length 0
09:38:07.331702 eth0 Out IP ip-192-0-2-123.eu-west-1.compute.internal.irdmi > ip-192-168-1-100.eu-west-1.compute.internal.41856: Flags [S.], seq 3367907264, ack 1128657992, win 26847, options [mss 8961,sackOK,TS val 1259768406 ecr 2780916192,nop,wscale 7], length 0
The critical line here is the last one – it’s come in on eth1 and it’s going out of eth0. Another test here is to look at ip rule
[root@test-i-01234567890abcdef ~]# ip rule
0: from all lookup local
512: from all to 192.0.2.111 lookup main
512: from all to 192.0.2.143 lookup main
512: from all to 192.0.2.66 lookup main
512: from all to 192.0.2.113 lookup main
512: from all to 192.0.2.145 lookup main
512: from all to 192.0.2.123 lookup main
512: from all to 192.0.2.5 lookup main
512: from all to 192.0.2.158 lookup main
512: from all to 192.0.2.100 lookup main
512: from all to 192.0.2.69 lookup main
512: from all to 192.0.2.129 lookup main
1024: from all fwmark 0x80/0x80 lookup main
1536: from 192.0.2.123 lookup 2
32766: from all lookup main
32767: from all lookup default
Notice here that we have two entries from all to 192.0.2.123 lookup main and from 192.0.2.123 lookup 2. Let’s take a look at what lookup 2 gives us, in the routing table
[root@test-i-01234567890abcdef ~]# ip route show table 2
192.0.2.1 dev eth1 scope link
Fix the issue
This is pretty easy – we need to add a default route if one doesn’t already exist. Long before I got here, my boss created a script which first runs ip route show table main | grep default to get the gateway for that interface, then runs ip rule list, looks for each lookup <number> and finally runs ip route add to put the default route on that table, the same as on the main table.
ip route add default via "${GW}" dev "${INTERFACE}" table "${TABLE}"
Is this still needed?
I know when we upgraded our cluster from EKS1.23 to EKS1.27, this script was still needed. When I’ve just checked a worker running EKS1.31, after around 12 hours of running, and a second interface being up, it’s not been needed… so perhaps we can deprecate this script?
Dropping packets to the containers due to Martians
When we upgraded our cluster from EKS1.23 to EKS1.27 we also changed a lot of the infrastructure under the surface (AlmaLinux 9 from CentOS7, Containerd and Runc from Docker, CGroups v2 from CGroups v1, and so on). We also moved from using an AWS Elastic Load Balancer (ELB) or “Classic Load Balancer” to AWS Network Load Balancer (NLB).
Following the upgrade, we started seeing packets not arriving at our containers and the system logs on the node were showing a lot of martian source messages, particularly after we configured our NLB to forward original IP source addresses to the nodes.
What happens
One thing we noticed was that each time we added a new pod to the cluster, it added a new eni[0-9a-f]{11} interface, but the sysctl value for net.ipv4.conf.<interface>.rp_filter (return path filtering – basically, should we expect the traffic to be arriving at this interface for that source?) in sysctl was set to 1 or “Strict mode” where the source MUST be the coming from the best return path for the interface it arrived on. The AWS VPC-CNI is supposed to set this to 2 or “Loose mode” where the source must be reachable from any interface.
In this case you’d tell this because you’d see this in your system journal (assuming you’ve got net.ipv4.conf.all.log_martians=1 configured):
Dec 03 10:01:19 test-i-01234567890abcdef kernel: IPv4: martian source 192.168.1.100 from 192.0.2.123, on dev eth1
The net result is that packets would be dropped by the host at this point, and they’d never be received by the containers in the pods.
Fix the issue
This one is also pretty easy. We run sysctl -a and loop through any entries which match net.ipv4.conf.([^\.]+).rp_filter = (0|1) and then, if we find any, we run sysctl -w net.ipv4.conf.\1.rp_filter = 2 to set it to the correct value.
Is this still needed?
Yep, absolutely. As of our latest upgrade to EKS1.31, if this value isn’t set, then it will drop packets. VPC-CNI should be fixing this, but for some reason it doesn’t. And setting the conf.ipv4.all.rp_filter to 2 doesn’t seem to make a difference, which is contrary to the documentation in the relevant Kernel documentation.
After 12 IP addresses are assigned to a node, Kubernetes services stop working for some pods
This was pretty weird. When we upgraded to EKS1.31 on our smallest cluster we initially thought we had an issue with CoreDNS, in that it sometimes wouldn’t resolve IP addresses for services (DNS names for services inside the cluster are resolved by <servicename>.<namespace>.svc.cluster.local to an internal IP address for the cluster – in our case, in the range 172.20.0.0/16). We upgraded CoreDNS to the EKS1.31 recommended version, v1.11.3-eksbuild.2 and that seemed to fix things… until we upgraded our next largest cluster, and things REALLY went wrong, but only when we had increased to over 12 IP addresses assigned to the node.
You might see this as frequent restarts of a container, particularly if you’re reliant on another service to fulfil an init container or the liveness/readyness check.
What happens
EKS1.31 moves KubeProxy from iptables or ipvs mode to nftables – a shift we had to make internally as AlmaLinux 9 no longer supports iptables mode, and ipvs is often quite flaky, especially when you have a lot of pod movements.
With a single interface and up to 11 IP addresses assigned to that interface, everything runs fine, but the moment we move to that second interface, much like in the first case above, we start seeing those pods attached to the second+ interface being unable to resolve service addresses. On further investigation, doing a dig from a container inside that pod to the service address of the CoreDNS service 172.20.0.10 would timeout, but a dig against the actual pod address 192.0.2.53 would return a valid response.
Under the surface, on each worker, KubeProxy adds a rule to nftables to say “if you try and reach 172.20.0.10, please instead direct it to 192.0.2.53”. As the containers fluctuate inside the cluster, KubeProxy is constantly re-writing these rules. For whatever reason though, KubeProxy currently seems unable to determine that a second or subsequent interface has been added, and so these rules are not applied to the pods attached to that interface…. or at least, that’s what it looks like!
Fix the issue
In this case, we wrote a separate script which was also triggered every minute. This script looks to see if the interfaces have changed by running ip link and looking for any interfaces called eth[0-9]+ which have changed, and then if it has, it runs crictl pods (which lists all the running pods in Containerd), looks for the Pod ID of KubeProxy, and then runs crictl stopp <podID> [1] and crictl rmp <podID> [1] to stop and remove the pod, forcing kubelet to restart the KubeProxy on the node.
[1] Yes, they aren’t typos, stopp means “stop the pod” and rmp means “remove the pod”, and these are different to stop and rm which relate to the container.
Is this still needed?
As this was what I was working on all-day yesterday, yep, I’d say so 😊 – in all seriousness though, if this hadn’t been a high-priority issue on the cluster, I might have tried to upgrade the AWS VPC-CNI and KubeProxy add-ons to a later version, to see if the issue was resolved, but at this time, we haven’t done that, so maybe I’ll issue a retraction later 😂
I just want to note that Will Jessop noticed a significant typo in this post within an hour of my posting. The post was updated accordingly. Will is awesome and super lovely. Thanks Will!
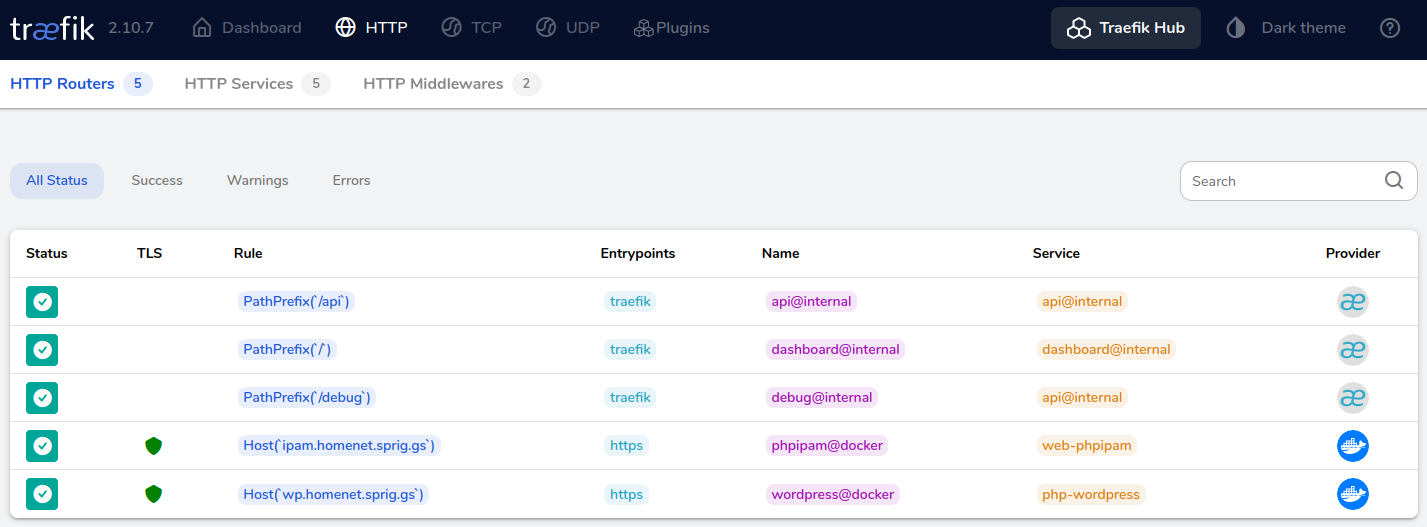
I have a small server running Docker for services at home. There are several services which will want to use HTTP, but I can’t have them all sharing the same port without a reverse proxy to manage how to route the traffic to the containers!
This is my guide to how I got Traefik set up to serve HTTP and HTTPS traffic.
The existing setup for one service
Currently, I have phpIPAM which has the following docker-compose.yml file:
The moment I want to bind another service to TCP/80, I get an error because we’ve already used TCP/80 for phpIPAM. Enter Traefik. Let’s stop the docker container with docker compose down and build our Traefik setup.
Traefik Setup
I always store my docker compose files in /opt/docker/<servicename>, so let’s create a directory for traefik; sudo mkdir -p /opt/docker/traefik
The (“dynamic”) configuration file
Next we need to create a configuration file called traefik.yaml
# Ensure all logs are sent to stdout for `docker compose logs`
accessLog: {}
log: {}
# Enable docker provider but don't switch it on by default
providers:
docker:
exposedByDefault: false
# Select this as the docker network to connect from traefik to containers
# This is defined in the docker-compose.yaml file
network: web
# Enable the API and Dashboard on TCP/8080
api:
dashboard: true
insecure: true
debug: true
# Listen on both HTTP and HTTPS
entryPoints:
http:
address: ":80"
http: {}
https:
address: ":443"
http:
tls: {}
With the configuration file like this, we’ll serve HTTPS traffic with a self-signed TLS certificate on TCP/443 and plain HTTP on TCP/80. We have a dashboard on TCP/8080 served over HTTP, so make sure you don’t expose *that* to the public internet!
The Docker-Compose File
Next we need the docker-compose file for Traefik, so let’s create docker-compose.yaml
There are a few parts here which aren’t spelled out on the Traefik quickstart! Firstly, if you don’t define a network, it’ll create one using the docker-compose file path, so probably traefik_traefik or traefik_default, which is not what we want! So, we’ll create one called “web” (but you can call it whatever you want. On other deployments, I’ve used the name “traefik” but I found it tedious to remember how to spell that each time). This network needs to be “attachable” so that other containers can use it later.
You then attach that network to the traefik service, and expose the ports we need (80, 443 and 8080).
And then start the container with docker compose up -d
alpine-docker:/opt/docker/traefik# docker compose up -d
[+] Running 2/2
✔ Network web Created 0.2s
✔ Container traefik-traefik-1 Started 1.7s
alpine-docker:/opt/docker/traefik#
Adding Traefik to phpIPAM
Going back to phpIPAM, So that Traefik can reach the containers, and so that the container can reach it’s database, we need two network statements now; the first is the “external” network for the traefik connection which we called “web“. The second is the inter-container network so that the “web” service can reach the “db” service, and so that the “cron” service can reach the “db” service. So we need to add that to the start of /opt/docker/phpipam/docker-compose.yaml, like this;
We then need to add both networks that to the “web” container, like this:
services:
web:
image: phpipam/phpipam-www:latest
networks:
- ipam
- web
# ...... and the rest of the config
Remove the “ports” block and replace it with an expose block like this:
services:
web:
# ...... The rest of the config for this service
## Don't bind to port 80 - we use traefik now
# ports:
# - "80:80"
## Do expose port 80 for Traefik to use
expose:
- 80
# ...... and the rest of the config
And just the inter-container network to the “cron” and “db” containers, like this:
cron:
image: phpipam/phpipam-cron:latest
networks:
- ipam
# ...... and the rest of the config
db:
image: mariadb:latest
networks:
- ipam
# ...... and the rest of the config
There’s one other set of changes we need to make in the “web” service, which are to enable Traefik to know that this is a container to look at, and to work out what traffic to send to it, and that’s to add labels, like this:
services:
web:
# ...... The rest of the config for this service
labels:
- traefik.enable=true
- traefik.http.routers.phpipam.rule=Host(`phpipam.homenet`)
# ...... and the rest of the config
Right, now we run docker compose up -d
alpine-docker:/opt/docker/phpipam# docker compose up -d
[+] Running 4/4
✔ Network ipam Created 0.4s
✔ Container phpipam-db-1 Started 1.4s
✔ Container phpipam-cron-1 Started 2.1s
✔ Container phpipam-web-1 Started 2.6s
alpine-docker:/opt/docker/phpipam#
If you notice, this doesn’t show to the web network being created (because it was already created by Traefik) but does bring up the container.
Checking to make sure it’s working
If we head to the Traefik dashboard (http://your-docker-server:8080) you’ll see the phpipam service identified there… yey!
Better TLS with Lets Encrypt
So, at home I actually have a DNS suffix that is a real DNS name. For the sake of the rest of this documentation, assume it’s homenet.sprig.gs (but it isn’t 😁).
This DNS space is hosted by Digital Ocean, so I can use a DNS Challenge with Lets Encrypt to provide hostnames which are not publically accessible. If you’re hosting with someone else, then that’s probably also available – check the Traefik documentation for your specific variables. The table on that page (as of 2023-12-30) shows the environment variables you need to pass to Traefik to get LetsEncrypt working.
As you can see here, I just need to add the value DO_AUTH_TOKEN, which is an API key. I went to the Digital Ocean console, and navigated to the API panel, and added a new “Personal Access Token”, like this:
Notice that the API key needed to provide both “Read” and “Write” capabilities, and has been given a name so I can clearly see it’s purpose.
Changing the traefik docker-compose.yaml file
In /opt/docker/traefik/docker-compose.yaml we need to add that new environment variable; DO_AUTH_TOKEN, like this:
services:
traefik:
# ...... The rest of the config for this service
environment:
DO_AUTH_TOKEN: dop_v1_decafbad1234567890abcdef....1234567890
# ...... and the rest of the config
Changing the traefik.yaml file
In /opt/docker/traefik/traefik.yaml we need to tell it to use Let’s Encrypt. Add this block to the end of the file:
Obviously change the email address to a valid one for you! I hit a few issues with the value specified in the documentation for delayBeforeCheck, as their value of “0” wasn’t long enough for the DNS value to be propogated around the network – 1 minute is enough though!
I also had to add the resolvers, as my local network has a caching DNS server, so I’d never have seen the updates! You may be able to remove both those values from your files.
Now you’ve made all the changes to the Traefik service, restart it with docker compose down ; docker compose up -d
Changing the services to use Lets Encrypt
We need to add one final label to the /opt/docker/phpipam/docker-compose.yaml file, which is this one:
services:
web:
# ...... The rest of the config for this service
labels:
- traefik.http.routers.phpipam.tls.certresolver=letsencrypt
# ...... and the rest of the config
Also, update your .rule=Host(`hostname`) to use the actual DNS name you want to be able to use, then restart the docker container.
phpIPAM doesn’t like trusting proxies, unless explicitly told to, so I also had add an environment variable IPAM_TRUST_X_FORWARDED=true to the /opt/docker/phpipam/docker-compose.yaml file too, because phpIPAM tried to write the HTTP scheme for any links which came up, based on what protocol it thought it was running – not what the proxy was telling it it was being accessed as!
Debugging any issues
If you have it all setup as per the above, and it isn’t working, go into /opt/docker/traefik/traefik.yaml and change the stanza which says log: {} to:
log:
level: DEBUG
Be aware though, this adds a LOT to your logs! (But you won’t see why your ACME requests have failed without it). Change it back to log: {} once you have it working again.
Adding your next service
I now want to add that second service to my home network – WordPress. Here’s /opt/docker/wordpress/docker-compose.yaml for that service;
alpine-docker:/opt/docker/wordpress# docker compose up -d
[+] Running 3/3
✔ Network wordpress Created 0.2s
✔ Container wordpress-mariadb-1 Started 3.0s
✔ Container wordpress-php-1 Started 3.8s
alpine-docker:/opt/docker/wordpress#
Tada!
One final comment – I never did work out how to make connections forceably upgrade from HTTP to HTTPS, so instead, I shut down port 80 in Traefik, and instead run this container.
I love the tee command – it captures stdout [1] and puts it in a file, while then returning that output to stdout for the next process in a pipe to consume, for example:
$ ls -l | tee /tmp/output
total 1
xrwxrwxrw 1 jonspriggs jonspriggs 0 Jul 27 11:16 build.sh
$ cat /tmp/output
total 1
xrwxrwxrw 1 jonspriggs jonspriggs 0 Jul 27 11:16 build.sh
But wait, why is that useful? Well, in a script, you don’t always want to see the content scrolling past, but in the case of a problem, you might need to catch up with the logs afterwards. Alternatively, you might do something like this:
if some_process | tee /tmp/output | grep -q "some text"
then
echo "Found 'some text' - full output:"
cat /tmp/output
fi
This works great for stdout but what about stderr [2]? In this case you could just do:
some_process 2>&1 | tee /tmp/output
But that mashes all of stdout and stderr into the same blob.
In my case, I want to capture all the output (stdout and stderr) of a given process into a file. Only stdout is forwarded to the next process, but I still wanted to have the option to see stderr as well during processing. Enter process substitution.
With this, I run capture_out step-1 do_a_thing and then in /tmp/tmp.sometext/step-1/stdout and /tmp/tmp.sometext/step-1/stderr are the full outputs I need… but wait, I can also do:
if capture_out has_an_error something-wrong | capture_out handler check_output
then
echo "It all went great"
else
echo "Process failure"
echo "--Initial process"
# Use wc -c to check the number of characters in the file
if [ -e "${TEMP_DATA_PATH}/has_an_error/stdout"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/has_an_error/stdout")" ]
then
echo "----stdout:"
cat "${TEMP_DATA_PATH}/has_an_error/stdout"
fi
if [ -e "${TEMP_DATA_PATH}/has_an_error/stderr"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/has_an_error/stderr")" ]
then
echo "----stderr:"
cat "${TEMP_DATA_PATH}/has_an_error/stderr"
fi
echo "--Second stage"
if [ -e "${TEMP_DATA_PATH}/handler/stdout"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/handler/stdout")" ]
then
echo "----stdout:"
cat "${TEMP_DATA_PATH}/handler/stdout"
fi
if [ -e "${TEMP_DATA_PATH}/handler/stderr"] && [ 0 -ne "$(wc -c "${TEMP_DATA_PATH}/handler/stderr")" ]
then
echo "----stderr:"
cat "${TEMP_DATA_PATH}/handler/stderr"
fi
fi
This has become part of my normal toolkit now for logging processes. Thanks bash!
Also, thanks to ChatGPT for helping me find this structure that I’d seen before, but couldn’t remember how to do it! (it almost got it right too! Remember kids, don’t *trust* what ChatGPT gives you, use it as a research starting point, test *that* against your own knowledge, test *that* against your environment and test *that* against expected error cases too! Copy & Paste is not the best idea with AI generated code!)
Footnotes
[1] stdout is the name of the normal output text we see in a shell, it’s also sometimes referred to as “file descriptor 1” or “fd1”. You can also output to &1 with >&1 which means “send to fd1”
[2] stderr is the name of the output in a shell when an error occurs. It isn’t caught by things like some_process > /dev/null which makes it useful when you don’t want to see output, just errors. Like stdout, it’s also referred to as “file descriptor 2” or “fd2” and you can output to &2 with >&2 if you want to send stdout to stderr.
In my current project I am often working with Infrastructure as Code (IoC) in the form of Terraform and Terragrunt files. Before I joined the team a decision was made to use SOPS from Mozilla, and this is encrypted with an AWS KMS key. You can only access specific roles using the SAML2AWS credentials, and I won’t be explaining how to set that part up, as that is highly dependant on your SAML provider.
While much of our environment uses AWS, we do have a small presence hosted on-prem, using a hypervisor service. I’ll demonstrate this with Proxmox, as this is something that I also use personally :)
Firstly, make sure you have all of the above tools installed! For one stage, you’ll also require yq to be installed. Ensure you’ve got your shell hook setup for direnv as we’ll need this later too.
Late edit 2023-07-03: There was a bug in v0.22.0 of the terraform which didn’t recognise the environment variables prefixed PROXMOX_VE_ – a workaround by using TF_VAR_PROXMOX_VE and a variable "PROXMOX_VE_" {} block in the Terraform code was put in place for the inital publication of this post. The bug was fixed in 0.23.0 which this post now uses instead, and so as a result the use of TF_VAR_ prefixed variables was removed too.
Set up AWS Vault
AWS KMS
AWS Key Management Service (KMS) is a service which generates and makes available encryption keys, backed by the AWS service. There are *lots* of ways to cut that particular cake, but let’s do this a quick and easy way… terraform
So far, so good… but wait, you’ve authenticated to your SAML access to AWS. Let’s close that shell, and go back in again
$ cd /path/to/demo
direnv: loading /path/to/demo/.envrc
direnv: using sops
$
Ah, now we don’t have our values exported. That’s what we wanted!
What now?!
Configuring the details of the proxmox cluster
We have our .envrc file which provides our credentials (let’s pretend we’re using a shared set of credentials across all the boxes), but now we need to setup access to each of the boxes.
Let’s make our two cluster directories;
mkdir cluster_01
mkdir cluster_02
And in each of these clusters, we need to put an .envrc file with the right IP address in. This needs to check up the tree for any credentials we may have already loaded:
source_env "$(find_up ../.envrc)"
export PROXMOX_VE_ENDPOINT="https://192.0.2.1:8006" # Documentation IP address for the first cluster - change for the second cluster.
The first line works up the tree, looking for a parent .envrc file to inject, and then, with the second line, adds the Proxmox API endpoint to the end of that chain. When we run direnv allow (having logged back into our saml2aws session), we get this:
Then in the cluster_01 directory, create a directory for the code you want to run (e.g. create a VLAN might be called “VLANs/30/“) and put in it this terragrunt.hcl
This assumes you have a terraform directory called terraform-module-network/vlan in a particular place in your tree or even better, a module in your git repo, which uses the input values you’ve provided.
That double slash in the source line isn’t a typo either – this is the point in that tree that Terragrunt will copy into the directory to run terraform from too.
A quick note about includes and provider blocks
The other key thing is that the “include” block loads the values from the first matching terragrunt.hcl file in the parent directories, which in this case is the one which defined the providers block. You can’t include multiple different parent files, and you can’t have multiple generate blocks either.
Running it all together!
Now we have all our depending files, let’s run it!
user@host:~$ cd test
direnv: loading ~/test/.envrc
direnv: using sops
user@host:~/test$ saml2aws login --skip-prompt --quiet ; saml2aws exec -- bash
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test$ cd cluster_01/VLANs/30
direnv: loading ~/test/cluster_01/.envrc
direnv: loading ~/test/.envrc
direnv: using sops
direnv: export +PROXMOX_VE_ENDPOINT +PROXMOX_VE_USERNAME +PROXMOX_VE_PASSWORD
user@host:~/test/cluster_01/VLANs/30$ terragrunt apply
data.proxmox_virtual_environment_nodes.available_nodes: Reading...
data.proxmox_virtual_environment_nodes.available_nodes: Read complete after 0s [id=nodes]
Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# proxmox_virtual_environment_network_linux_bridge.this[0] will be created
+ resource "proxmox_virtual_environment_network_linux_bridge" "this" {
+ autostart = true
+ comment = "VLAN30"
+ id = (known after apply)
+ mtu = (known after apply)
+ name = "vmbr30"
+ node_name = "proxmox01"
+ ports = [
+ "enp3s0.30",
]
+ vlan_aware = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
proxmox_virtual_environment_network_linux_bridge.this[0]: Creating...
proxmox_virtual_environment_network_linux_bridge.this[0]: Creation complete after 2s [id=proxmox01:vmbr30]
user@host:~/test/cluster_01/VLANs/30$
I’ve recently been working with a network estate that was a bit hard to get a handle on. It had grown organically, and was a bit tricky to allocate new network segments in. To fix this, I deployed PHPIPAM, which was super easy to setup and configure (I used the docker-compose file on the project’s docker hub page, and put it behind an NGINX server which was pre-configured with a LetsEncrypt TLS/HTTPS certificate).
PHPIPAM is a IP Address Management tool which is self-hostable. I started by setting up the “Sections” (which was the hosting environments the estate is using), and then setup the supernets and subnets in the “Subnets” section.
Already, it was much easier to understand the network topology, but now I needed to get others in to take a look at the outcome. The team I’m working with uses a slightly dated version of Keycloak to provide Single Sign-On. PHPIPAM will use SAML for authentication, which is one of the protocols that Keycloak offers. The documentation failed me a bit at this point, but fortunately a well placed ticket helped me move it along.
Setting up Keycloak
Here’s my walk through
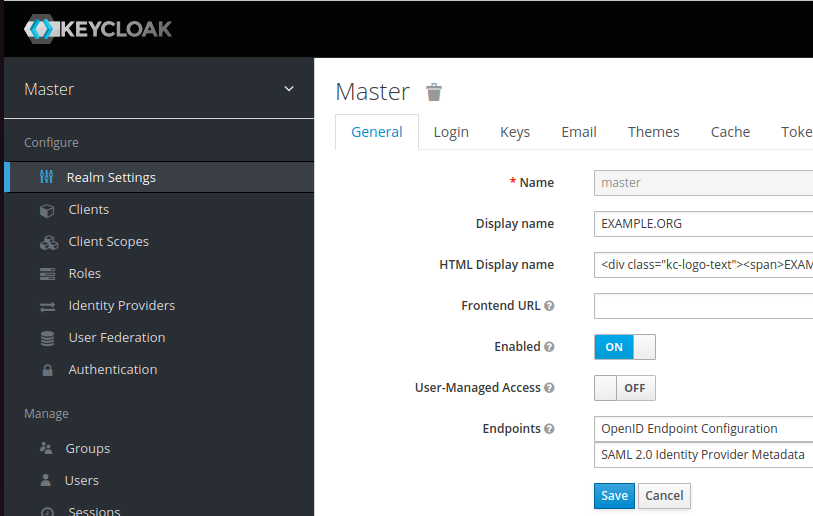
Go to “Realm Settings” in the sidebar and find the “SAML Identity Provider Metadata” (on my system it’s on the “General” tab but it might have changed position on your system). This will be an XML file, and (probably) the largest block of continuous text will be in a section marked “ds:X509Certificate” – copy this text, and you’ll need to use this as the “IDP X.509 public cert” in PHPIPAM.
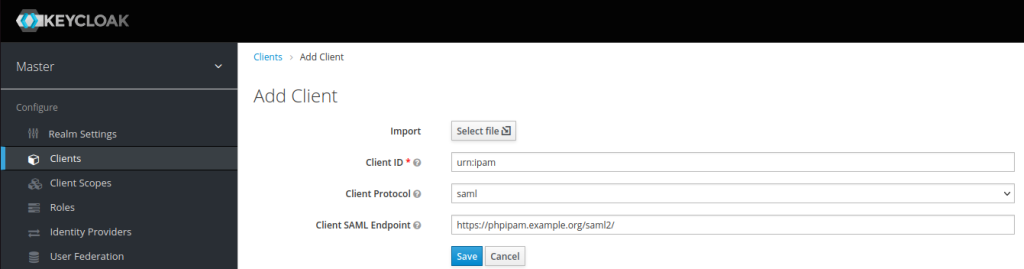
Go to “Clients” in the sidebar and click “Create”. If you want Keycloak to offer access to PHPIPAM as a link, the client ID needs to start “urn:” If you just want to use the PHPIPAM login option, give the client ID whatever you want it to be (I’ve seen some people putting in the URL of the server at this point). Either way, this needs to be unique. The client protocol is “saml” and the client SAML endpoint is the URL that you will be signing into on PHPIPAM – in my case https://phpipam.example.org/saml2/. It should look like this: Click Save to take you to the settings for this client.
If you want Keycloak to offer a sign-in button, set the name of the button and description.
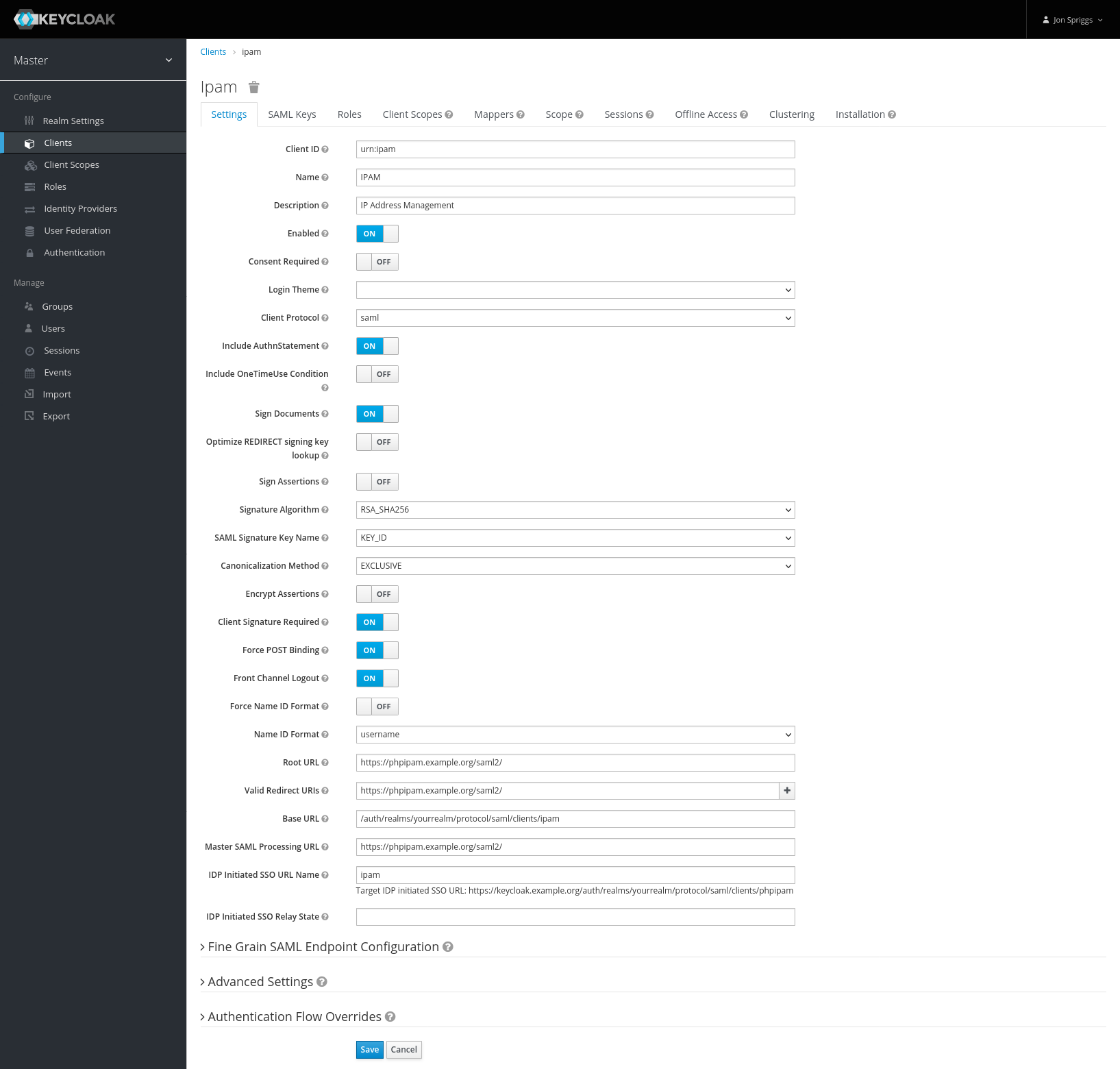
Further down the page is “Root URL” set that to the SAML Endpoint (the one ending /saml2/ from before). Also set the “Valid Redirect URIs” to that too.
Where it says “IDP Initiated SSO URL Name” put a string that will identify the client – I put phpipam, but it can be anything you want. This will populate a URL like this: https://keycloak.example.org/auth/realms/yourrealm/protocol/saml/clients/phpipam, which you’ll need as the “IDP Issuer”, “IDP Login URL” and “IDP Logout URL”. Put everything after the /auth/ in the box marked “Base URL”. It should look like this: Hit Save.
Go to the “SAML Keys” tab. Copy the private key and certificate, these are needed as the “Authn X.509 signing” cert and cert key in PHPIPAM.
Go to the “Mappers” tab. Create each of the following mappers;
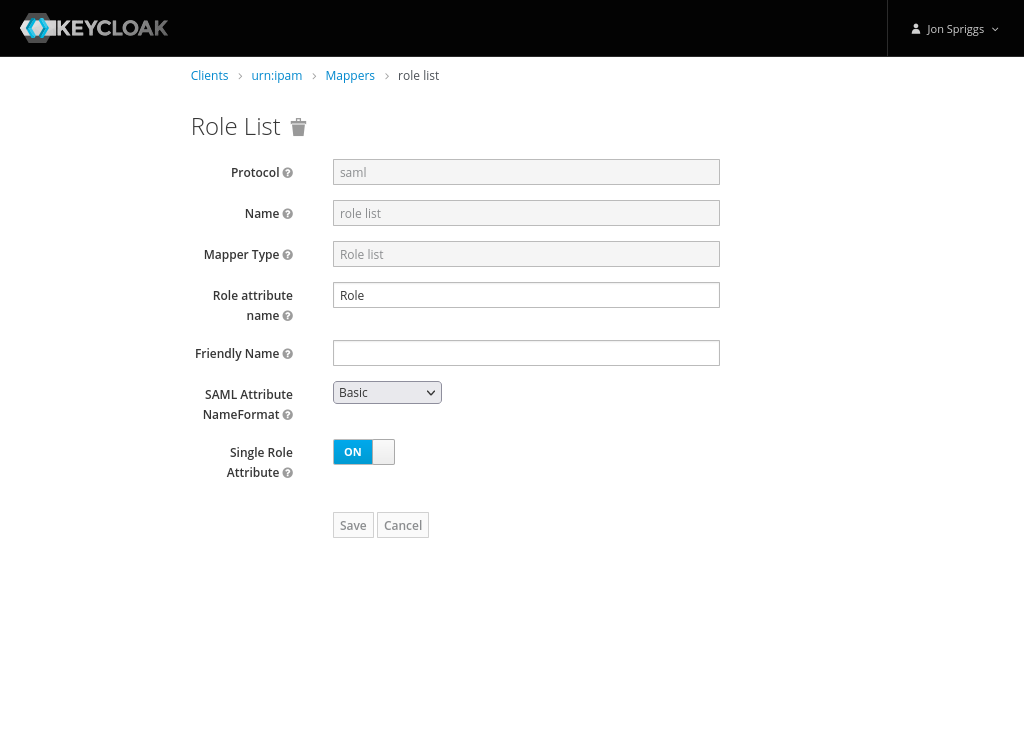
A Role List mapper, with the name of “role list”, Role Attribute Name of “Role”, no friendly name, the SAML Attribute NameFormat set to “Basic” and Single Role Attribute set to on.
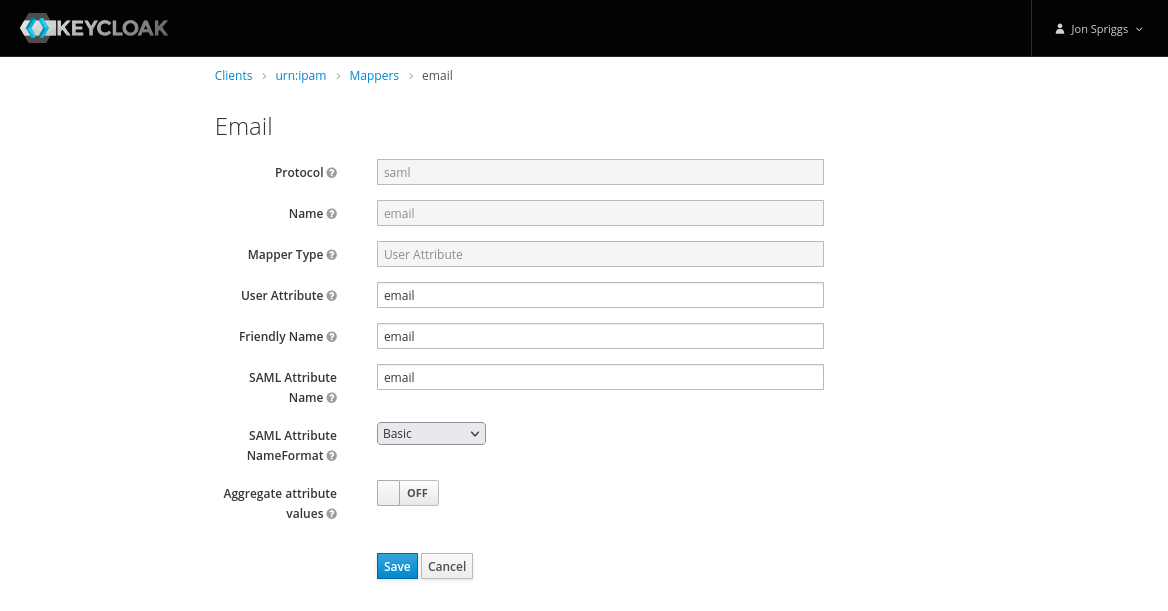
A User Attribute mapper, with the name, User Attribute, Friendly Name and SAML Attribute Name set to “email”, the SAML Attribute NameFormat set to “Basic” and Aggregate Attribute Values set to “off”.
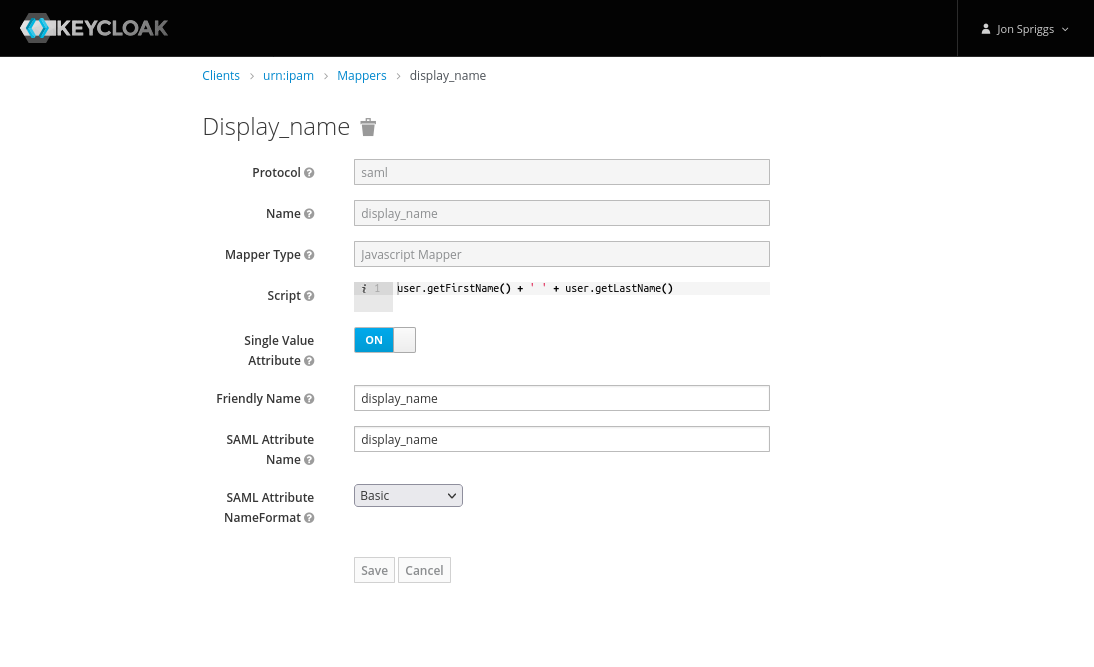
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “display_name” and the SAML Attribute NameFormat set to “Basic”. The Script should be set to this single line: user.getFirstName() + ' ' + user.getLastName().
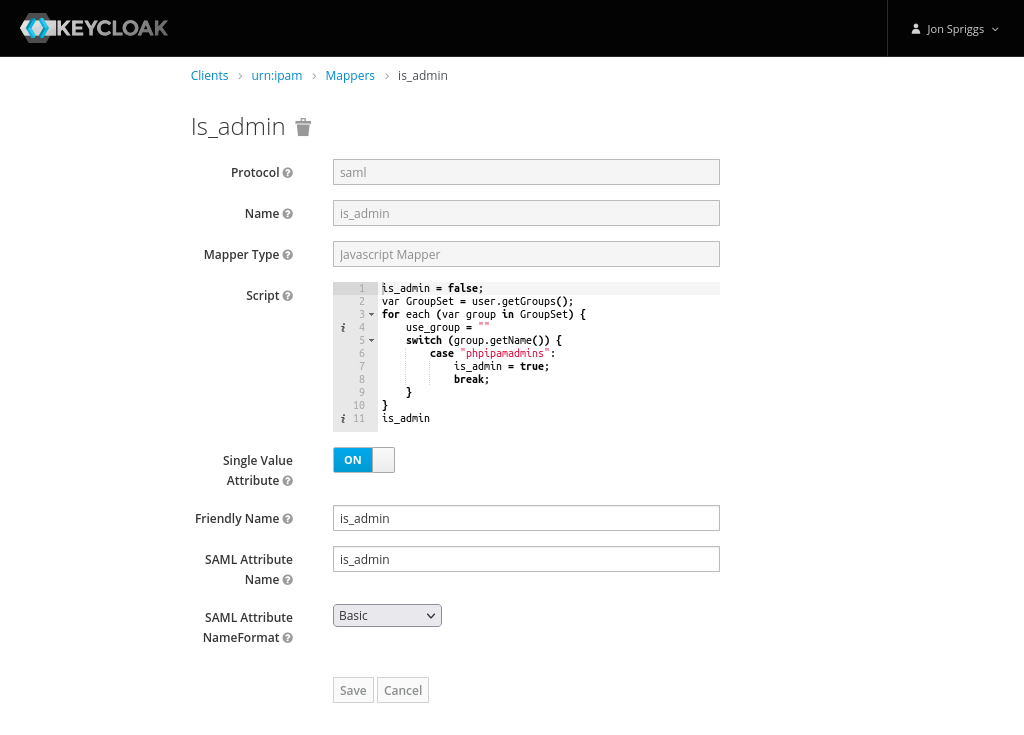
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “is_admin” and the SAML Attribute NameFormat set to “Basic”.
The script should be as follows:
is_admin = false;
var GroupSet = user.getGroups();
for each (var group in GroupSet) {
use_group = ""
switch (group.getName()) {
case "phpipamadmins":
is_admin = true;
break;
}
}
is_admin
Create one more mapper item:
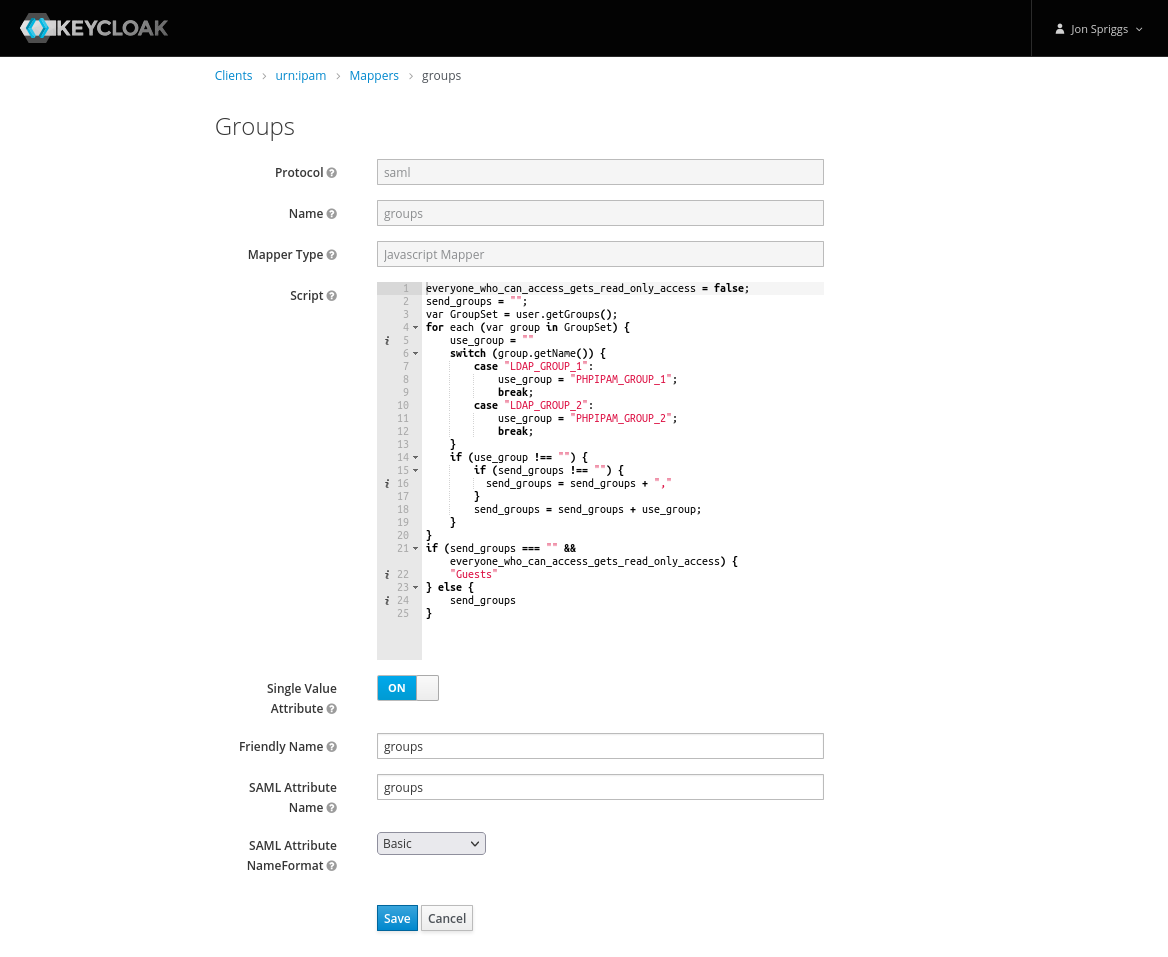
A Javascript Mapper, with the name, Friendly Name and SAML Attribute Name set to “groups” and the SAML Attribute NameFormat set to “Basic”. The script should be as follows:
everyone_who_can_access_gets_read_only_access = false;
send_groups = "";
var GroupSet = user.getGroups();
for each (var group in GroupSet) {
use_group = ""
switch (group.getName()) {
case "LDAP_GROUP_1":
use_group = "IPAM_GROUP_1";
break;
case "LDAP_GROUP_2":
use_group = "IPAM_GROUP_2";
break;
}
if (use_group !== "") {
if (send_groups !== "") {
send_groups = send_groups + ","
}
send_groups = send_groups + use_group;
}
}
if (send_groups === "" && everyone_who_can_access_gets_read_only_access) {
"Guests"
} else {
send_groups
}
For context, the groups listed there, LDAP_GROUP_1 might be “Customer 1 Support Staff” or “ITSupport” or “Networks”, and the IPAM_GROUP_1 might be “Customer 1” or “WAN Links” or “DC Patching” – depending on the roles and functions of the teams. In my case they relate to other roles assigned to the staff member and the name of the role those people will perform in PHP IPAM. Likewise in the is_admin mapper, I’ve mentioned a group called “phpipamadmins” but this could be any relevant role that might grant someone admin access to PHPIPAM.
Late Update (2023-06-07): I’ve figured out how to enable modules now too. Create a Javascript mapper as per above, but named “modules” and have this script in it:
// Current modules as at 2023-06-07
// Some default values are set here.
noaccess = 0;
readonly = 1;
readwrite = 2;
readwriteadmin = 3;
unsetperm = -1;
var modules = {
"*": readonly, "vlan": unsetperm, "l2dom": unsetperm,
"devices": unsetperm, "racks": unsetperm, "circuits": unsetperm,
"nat": unsetperm, "locations": noaccess, "routing": unsetperm,
"pdns": unsetperm, "customers": unsetperm
}
function updateModules(modules, new_value, list_of_modules) {
for (var module in list_of_modules) {
modules[module] = new_value;
}
return modules;
}
var GroupSet = user.getGroups();
for (var group in GroupSet) {
switch (group.getName()) {
case "LDAP_ROLE_3":
modules = updateModules(modules, readwriteadmin, [
'racks', 'devices', 'nat', 'routing'
]);
break;
}
}
var moduleList = '';
for (var key in modules) {
if (modules.hasOwnProperty(key) && modules[key] !==-1) {
if (moduleList !== '') {
moduleList += ',';
}
moduleList += key + ':' + modules[key];
}
}
moduleList;
OK, that’s Keycloak sorted. Let’s move on to PHPIPAM.
Setting up PHPIPAM
In the administration menu, select “Authentication Methods” and then “Create New” and select “Create new SAML2 authentication”.
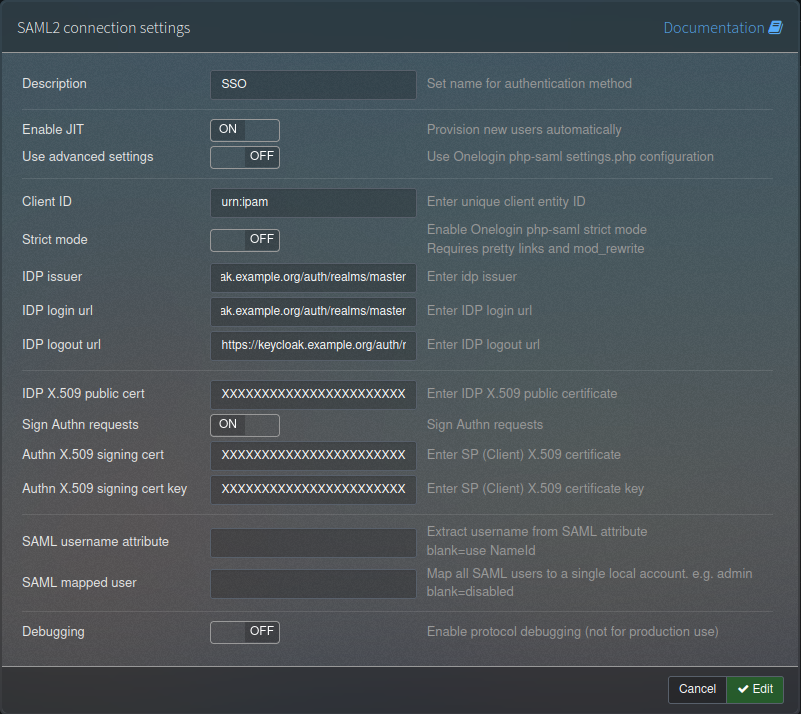
In the description field, give it a relevant name, I chose SSO, but you could call it any SSO system name. Set “Enable JIT” to “on”, leave “Use advanced settings” as “off”. In Client ID put the Client ID you defined in Keycloak, probably starting urn: or https://. Leave “Strict mode” off. Next is the IDP Issuer, IDP Login URL and IDP Logout URL, which should all be set to the same URL – the “IDP Initiated SSO URL Name” from step 4 of the Keycloak side (that was set to something like https://keycloak.example.org/auth/realms/yourrealm/protocol/saml/clients/phpipam).
After that is the certificate section – first the IDP X.509 public cert that we got in step 1, then the “Sign Authn requests” should be set to “On” and the Authn X.509 signing cert and cert key are the private key and certificate we retrieved in step 5 above. Leave “SAML username attribute” and “SAML mapped user” blank and “Debugging” set to “Off”. It should look like this:
Hit save.
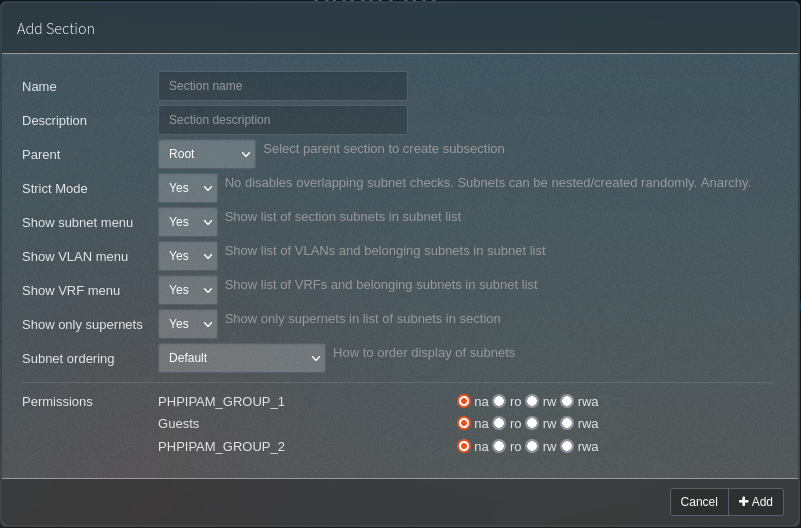
Next, any groups you specified in the groups mapper need to be defined. This is in Administration -> Groups. Create the group name and set a description.
Lastly, you need to configure the sections to define whigh groups have access. Each defined group gets given four radio buttons; “na” (no access), “ro” (read only), “rw” (read write) and “rwa” (read, write and administrate).
Try logging in. It should just work!
Debugging
If it doesn’t, and checking all of the above doesn’t help, I’ve tried adding some code into the PHP file in app/saml2/index.php, currently on line 149, above where it says:
**REMEMBER THIS IS JUST FOR TESTING PURPOSES AND SHOULD BE REMOVED ASAP**
In here is an array called _attributes which will show you what has been returned from the Keycloak server when someone tries to log in. In my case, I got this:
I recently was in the situation where I had two github profiles (one work, one personal) that I needed to incorporate in projects.
My work account on this device is my “default”, I use it to push, pull and so on, but the occasional personal activities (like terminate-notice) all should be attributed to my personal account.
To make this happen, I used direnv which reads a .envrcfile in the parents of the directory you’re currently in. I created a directory for my personal projects – ~/Code/Personaland placed a .envrc file which contains:
This means that I have a specific SSH key just for my personal activities (~/.ssh/personal.id_ed25519) and I’ve got my email address defined as two environment variables – AUTHOR (who wrote the code) and COMMITTER (who added it to the tree) – both are required when you’re changing them like this!
Because I don’t ever want it to try to use my SSH Agent, I’ve added the fact that SSH_AUTH_SOCK should be empty.
As an aside, work also require Commit Signing, but I don’t want to use that for my personal projects right now, so I also discovered a new feature as-of 2020 – the environment variables GIT_CONFIG_KEY_x, GIT_CONFIG_VALUE_x and GIT_CONFIG_COUNT=x
By using these, you can override any system, global and repo-level configuration values, like this:
This ensures that I *will not* GPG Sign commits, tags or pushes.
If I accidentally cloned a repo into an unusual location, or on purpose need to make a directory or submodule a personal repo, I just copy the .envrc file into that part of the tree, run direnv allowand hey-presto! I’ve turned that area into a personal repo, without having to remember the .gitconfigstring to mark a new part of my tree as a personal one.
Last week I created a post talking about the new project I’ve started on Github called “Terminate-Notice” (which in hindsight isn’t very accurate – at best it’s ‘spot-instance-responses’ and at worst it’s ‘instance-rebalance-and-actions-responder’ but neither work well)… Anyway, I mentioned how I was creating RPM and DEB packages for my bash scripts and that I hadn’t put it into a repo yet.
Well, now I have, so let’s wander through how I made this work.
I have a the following files in my shell script, which are:
/usr/sbin/terminate-notice (the actual script which will run)
/usr/lib/systemd/system/terminate-notice.service (the SystemD Unit file to start and stop the script)
/usr/share/doc/terminate-notice/LICENSE (the license under which the code is released)
/etc/terminate-notice.conf.d/service.conf (the file which tells the script how to run)
These live in the root directory of my repository.
I also have the .github directory (where the things that make this script work will live), a LICENSE file (so Github knows what license it’s released under) and a README.md file (so people visiting the repo can find out about it).
A bit about Github Actions
Github Actions is a CI/CD pipeline built into Github. It responds to triggers – in our case, pushes (or uploads, in old fashioned terms) to the repository, and then runs commands or actions. The actions which will run are stored in a simple YAML formatted file, referred to as a workflow which contains some setup fields and then the “jobs” (collections of actions) themselves. The structure is as follows:
# The pretty name rendered by Actions to refer to this workflow
name: Workflow Name
# Only run this workflow when the push is an annotated tag starting v
on:
push:
tags:
- 'v*'
# The workflow contains a collection of jobs, each of which has
# some actions (or "steps") to run
jobs:
# This is used to identify the output in other jobs
Unique_Name_For_This_Job:
# This is the pretty name rendered in the Github UI for this job
name: Job Name
# This is the OS that the job will run on - typically
# one of: ubuntu-latest, windows-latest, macos-latest
runs-on: runner-os
# The actual actions to perform
steps:
# This is a YAML list, so note where the hyphens (-) are
# The pretty name of this step
- name: Checkout Code
# The name of the public collection of actions to perform
uses: actions/checkout@v3
# Any variables to pass into this action module
with:
path: "REPO"
# This action will run a shell command
- name: Run a command
run: echo "Hello World"
Build a DEB package
At the simplest point, creating a DEB package is;
Create the directory structure (as above) that will unpack from your package file and put the files in the right places.
Create a DEBIAN/control file which provides enough details for your package manager to handle it.
Run dpkg-deb --build ${PATH_TO_SOURCE} ${OUTPUT_FILENAME}
Assuming the DEBIAN/control file was static and also lived in the repo, and I were just releasing the DEB file, then I could make the above work with the following steps:
name: Create the DEB
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Package
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Copy script files around to stop .github from being added to the package then build the package
run: |
mkdir PKG_SOURCE
cp -Rf REPO/usr REPO/etc REPO/DEBIAN PKG_SOURCE
dpkg-deb --build PKG_SOURCE package.deb
- name: Release the Package
uses: softprops/action-gh-release@v1
with:
files: package.deb
But no, I had to get complicated and ALSO build an RPM file… and put some dynamic stuff in there.
Build an RPM file
RPMs are a little more complex, but not by much. RPM takes a spec file, which starts off looking like the DEBIAN/control file, and adds some “install” instructions. Let’s take a look at that spec file:
The “Name”, “Version”, “Release” and “BuildArch” values in the top of that file define what the resulting filename is (NAME_VERSION-RELEASE.BUILDARCH.rpm).
Notice that there are some “macros” which replace /etc with %{_sysconfdir}, /usr/sbin with %{_sbindir} and so on, which means that, theoretically, this RPM could be installed in an esoteric tree… but most people won’t bother.
The one quirk with this is that %{name} bit there – RPM files need to have all these sources in a directory named after the package name, which in turn is stored in a directory called SOURCES (so SOURCES/my-package for example), and then it copies the files to wherever they need to go. I’ve listed etc/config/file and usr/sbin/script but these could just have easily been file and script for all that the spec file cares.
Once you have the spec file, you run sudo rpmbuild --define "_topdir $(pwd)" -bb file.spec to build the RPM.
So, again, how would that work from a workflow YAML file perspective, assuming a static spec and source tree as described above?
name: Create the DEB
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Package
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Copy script files around to stop .github from being added to the package then build the package
run: |
mkdir -p SOURCES/my-package-name
cp -Rf REPO/usr REPO/etc SOURCES/my-package-name
sudo rpmbuild --define "_topdir $(pwd)" -bb my-package-name.spec
- name: Release the Package
uses: softprops/action-gh-release@v1
with:
files: RPMS/my-package-name_0.0.1-1.noarch.rpm
But again, I want to be fancy (and I want to make resulting packages as simple to repeat as possible)!
So, this is my release.yml as of today:
name: Run the Release
permissions:
contents: write
on:
push:
tags:
- 'v*'
jobs:
Create_Packages:
name: Create Packages
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
path: "REPO"
- name: Calculate some variables
run: |
(
echo "GITHUB_REPO_NAME=$(echo "${GITHUB_REPOSITORY}" | cut -d/ -f2)"
echo "VERSION=$(echo "${GITHUB_REF_NAME}" | sed -e 's/^v//')"
echo "DESCRIPTION=A script which polls the AWS Metadata Service looking for an 'instance action', and triggers scripts in response to the termination notice."
echo "DEB_ARCHITECTURE=${ARCHITECTURE:-all}"
echo "RPM_ARCHITECTURE=${ARCHITECTURE:-noarch}"
echo "RELEASE=1"
cd REPO
echo "FIRST_YEAR=$(git log $(git rev-list --max-parents=0 HEAD) --date="format:%Y" --format="format:%ad")"
echo "THIS_COMMIT_YEAR=$(git log HEAD -n1 --date="format:%Y" --format="format:%ad")"
echo "THIS_COMMIT_DATE=$(git log HEAD -n1 --format="format:%as")"
if [ "$FIRST_YEAR" = "$THIS_COMMIT_YEAR" ]
then
echo "YEAR_RANGE=$FIRST_YEAR"
else
echo "YEAR_RANGE=${FIRST_YEAR}-${THIS_COMMIT_YEAR}"
fi
cd ..
) >> $GITHUB_ENV
- name: Make Directory Structure
run: mkdir -p "SOURCES/${GITHUB_REPO_NAME}" SPECS release
- name: Copy script files into SOURCES
run: |
cp -Rf REPO/[a-z]* "SOURCES/${GITHUB_REPO_NAME}"
cp REPO/LICENSE REPO/README.md "SOURCES/${GITHUB_REPO_NAME}/usr/share/doc/${GITHUB_REPO_NAME}/"
if grep -lr '#TAG#' SOURCES
then
sed -i -e "s/#TAG#/${VERSION}/" $(grep -lr '#TAG#' SOURCES)
fi
if grep -lr '#TAG_DATE#' SOURCES
then
sed -i -e "s/#TAG_DATE#/${THIS_COMMIT_YEAR}/" $(grep -lr '#TAG_DATE#' SOURCES)
fi
if grep -lr '#DATE_RANGE#' SOURCES
then
sed -i -e "s/#DATE_RANGE#/${YEAR_RANGE}/" $(grep -lr '#DATE_RANGE#' SOURCES)
fi
if grep -lr '#MAINTAINER#' SOURCES
then
sed -i -e "s/#MAINTAINER#/${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}/" $(grep -lr '#MAINTAINER#' SOURCES)
fi
- name: Create Control File
# Fields from https://www.debian.org/doc/debian-policy/ch-controlfields.html#binary-package-control-files-debian-control
run: |
mkdir -p SOURCES/${GITHUB_REPO_NAME}/DEBIAN
(
echo "Package: ${GITHUB_REPO_NAME}"
echo "Version: ${VERSION}"
echo "Section: ${SECTION:-misc}"
echo "Priority: ${PRIORITY:-optional}"
echo "Architecture: ${DEB_ARCHITECTURE}"
if [ -n "${DEPENDS}" ]
then
echo "Depends: ${DEPENDS}"
fi
echo "Maintainer: ${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}"
echo "Description: ${DESCRIPTION}"
if [ -n "${HOMEPAGE}" ]
then
echo "Homepage: ${HOMEPAGE}"
fi
) | tee SOURCES/${GITHUB_REPO_NAME}/DEBIAN/control
(
echo "Files:"
echo " *"
echo "Copyright: ${YEAR_RANGE} ${MAINTAINER:-Jon Spriggs <jon@sprig.gs>}"
echo "License: MIT"
echo ""
echo "License: MIT"
sed 's/^/ /' "SOURCES/${GITHUB_REPO_NAME}/usr/share/doc/${GITHUB_REPO_NAME}/LICENSE"
) | tee SOURCES/${GITHUB_REPO_NAME}/DEBIAN/copyright
- name: Create Spec File
run: PATH="REPO/.github/scripts:${PATH}" create_spec_file.sh
- name: Build DEB Package
run: dpkg-deb --build SOURCES/${GITHUB_REPO_NAME} "${{ env.GITHUB_REPO_NAME }}_${{ env.VERSION }}_${{ env.DEB_ARCHITECTURE }}.deb"
- name: Build RPM Package
run: sudo rpmbuild --define "_topdir $(pwd)" -bb SPECS/${GITHUB_REPO_NAME}.spec
- name: Confirm builds complete
run: sudo install -m 644 -o runner -g runner $(find . -type f -name *.deb && find . -type f -name *.rpm) release/
- name: Release
uses: softprops/action-gh-release@v1
with:
files: release/*
So this means I can, within reason, drop this workflow (plus a couple of other scripts to generate the slightly more complex RPM file – see the other files in that directory structure) into another package to release it.
OH WAIT, I DID! (for the terminate-notice-slack repo, for example!) All I actually needed to do there was to change the description line, and off it went!
So, this is all well and good, but how can I distribute these? Enter Repositories.
Making a Repository
Honestly, I took most of the work here from two fantastic blog posts for creating an RPM repo and a DEB repo.
First you need to create a GPG key.
To do this, I created the following pgp-key.batch file outside my repositories tree
%echo Generating an example PGP key
Key-Type: RSA
Key-Length: 4096
Name-Real: YOUR_ORG_NAME
Name-Email: your_org_name@users.noreply.github.com
Expire-Date: 0
%no-ask-passphrase
%no-protection
%commit
Store the public.asc file to one side (you’ll need it later) and keep the private.asc safe because we need to put that into Github.
Creating Github Pages
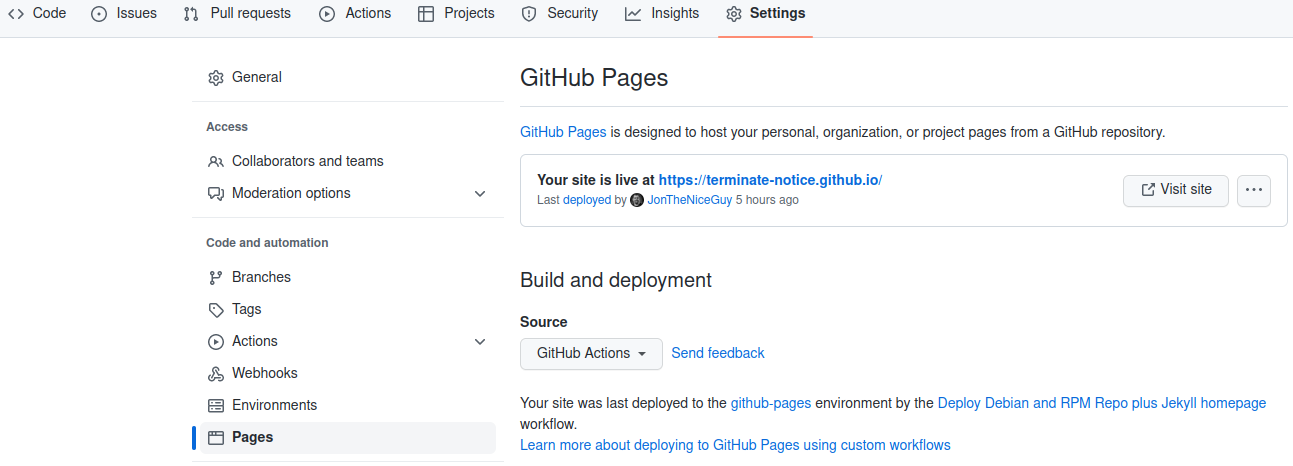
Create a new Git repository in your organisation called your-org.github.io. This marks the repository as being a Github Pages repository. Just to make that more explicit, in the settings for the repository, go to the pages section. (Note that yes, the text around this may differ, but are accurate as of 2023-03-28 in EN-GB localisation.)
Under “Source” select “GitHub Actions”.
Clone this repository to your local machine, and copy public.asc into the root of the tree with a sensible name, ending .asc.
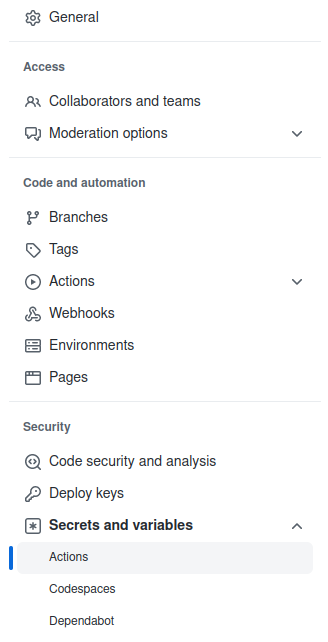
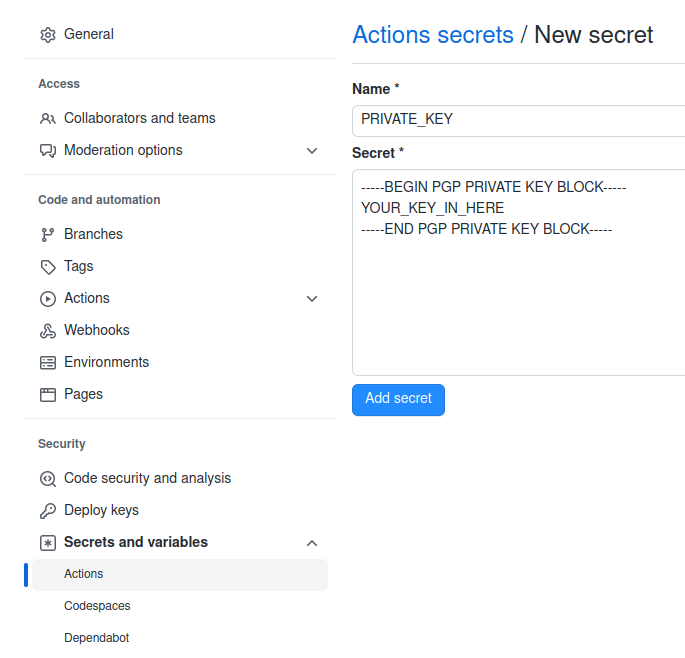
In the Github settings, find “Secrets and variables” under “Security” and pick “Actions”.
Select “New repository secret” and call it “PRIVATE_KEY”.
Now you can use this to sign things (and you will sign *SO MUCH* stuff)
Building the HTML front to your repo (I’m using Jekyll)
I’ve elected to use Jekyll because I know it, and it’s quite easy, but you should pick what works for you. My workflow for deploying these repos into the website rely on Jekyll because Github built that integration, but you’ll likely find other tools for things like Eleventy or Hugo.
Put a file called _config.yml into the root directory, and fill it with relevant content:
title: your-org
email: email_address@example.org
description: >-
This project does stuff.
baseurl: ""
url: "https://your-org.github.io"
github_username: your-org
# Build settings
theme: minima
plugins:
- jekyll-feed
exclude:
- tools/
- doc/
Naturally, make “your-org” “email_address@example.org” and the descriptions more relevant to your environment.
Next, create an index.md file with whatever is relevant for your org, but it must start with something like:
---
layout: home
title: YOUR-ORG Website
---
Here is the content for the front page.
Building the repo behind your static content
We’re back to working with Github Actions workflow files, so let’s pop that open.
I’ve basically changed the “stock” Jekyll static site Github Actions file and added every step that starts [REPO] to make the repository stuff fit in around the steps that start [JEKYLL] which build and deploy the Jekyll based site.
The key part to all this though is the step Build DEB and RPM repos which calls a script that downloads all the RPM and DEB files from the various other repository build stages and does some actions to them. Now yes, I could have put all of this into the workflow.yml file, but I think it would have made it all a bit more confusing! So, let’s work through those steps!
Making an RPM Repo
To build a RPM repo you get and sign each of the RPM packages you want to offer. You do this with this command:
Then, once you have all your RPM files signed, you then run a command called createrepo_c (available in Debian archives – Github Actions doesn’t have a RedHat based distro available at this time, so I didn’t look for the RPM equivalent). This creates the repository metadata, and finally you sign that file, like this:
gpg --detach-sign --armor repodata/repomd.xml
Making a DEB Repo
To build a DEB repo you get each of the DEB packages you want to offer in a directory called pool/main (you can also call “main” something else – for example “contrib”, “extras” and so on).
Once you have all your files, you create another directory called dists/stable/main/binary-all into which we’ll run a command dpkg-scanpackages to create the list of the available packages. Yes, “main” could also be called “contrib”, “extras” and “stable” could be called “testing” or “preprod” or the name of your software release (like “jaunty”, “focal” or “warty”). The “all” after the word “binary” is the architecture in question.
dpkg-scanpackages creates an index of the packages in that directory including the version number, maintainer and the cryptographic hashes of the DEB files.
We zip (using gzip and bzip2) the Packages file it creates to improve the download speeds of these files, and then make a Release file. This in turn has the cryptographic hashes of each of the Packages and zipped Packages files, which in turn is then signed with GPG.
Ugh, that was MESSY
Making the repository available to your distributions
RPM repos have it quite easy here – there’s a simple file, that looks like this:
The distribution user simply downloads this file, puts it into /etc/yum.sources.d/org-name.repo and now all the packages are available for download. Woohoo!
DEB repos are a little harder.
First, download the public key – https://org-name.github.io/public.asc and put it in /etc/apt/keyrings/org-name.asc. Next, create file in /etc/apt/sources.list.d/org-name.list with this line in:
deb [arch=all signed-by=/etc/apt/keyrings/org-name.asc] https://org-name.github.io/deb stable main
And now they can install whatever packages they want too!
Doing this the simple way
Of course, this is all well-and-good, but if you’ve got a simple script you want to package, please don’t hesitate to use the .github directory I’m using for terminate-notice, which is available in the -skeleton repo and then to make it into a repo, you can reuse the .github directory in the terminate-notice.github.io repo to start your adventure.